使用RNN构建强大的语言模型:逐步指南
如果ChatGPT只使用1个RNN隐藏层进行训练,它会如何工作?
ChatGPT基于GPT架构。但我们也可以使用RNN建立聊天机器人,它可以非常有教育意义。
语言建模
我们的目标是使用循环神经网络构建一种[语言模型]。这是什么意思?假设我们有长度为m的句子。语言模型可以让我们预测观察到该句子的概率(在给定数据集中)。
P(w1…wm) = ∏i=1mP(wi|w1…wi-1)
用语言来解释,一个句子的概率等于每个词在前面的词给定条件下的概率的乘积。
为什么这很有用?为什么我们想要分配观察一句话的概率?
一个机器翻译系统通常会为输入的句子生成多个候选句子。您可以使用语言模型来选择最有可能的句子。语音识别系统中也会进行类似的评分。
但是解决语言建模问题也有一个很酷的副作用。因为我们可以预测给定前面单词的概率,我们能够生成新的文字。这是一个生成模型。
在给定一系列单词的情况下,我们从预测的概率中抽样出下一个单词,并不断重复这个过程,直到我们得到一个完整的句子。这就是 chatGPT 的工作方式。它不像人类那样形成意见。它只是开始输出单词,并且通过逐个单词地生成一些有意义的内容。
请注意,在上述公式中,每个单词的概率都取决于之前所有单词的条件。实际上,由于计算或内存限制,许多模型难以表示这种长期依赖关系。它们通常只能看到前几个单词。
导入csv导入迭代工具导入运算符导入numpy as np导入nltk导入sys从日期时间导入datetime
导入 matplotlib.pyplot 库 as plt%matplotlib inline# 下载 NLTK 模型数据(您只需执行此操作一次)nltk.download(“book”)## 训练数据和自然语言处理(NLP)预处理
让我们阅读并将一些文本转换为整数令牌。
为了训练我们的语言模型,我们需要文本作为学习的素材。
1. 分词文本
我们有原始文本,但我们想进行每个单词的预测。这意味着我们必须将我们的评论分成句子和单词。我们可以只通过空格拆分每个评论,但那不会正确处理标点符号。句子“他走了!”应该有3个标记:“他”,“走了”,“!”我们将使用[NLTK]的“word_tokenize”和“sent_tokenize”方法,这些方法为我们完成了大部分的工作。
2. 删除不常用的单词
大多数文本中的单词仅出现一两次。删除这些不常用的单词是一个好主意。拥有庞大的词汇会使我们的模型训练缓慢(我们稍后会讨论这是为什么),而且因为我们没有很多这些单词的上下文示例,我们也无法学习如何正确使用它们。这与人类学习的方式非常相似。要真正理解如何适当地使用一个词,您需要在不同的上下文中看到它。
在我们的代码中,我们将我们的词汇限制为最常用的“vocabulary_size”个单词(我将其设置为8000,但随意更改)。我们通过“UNKNOWN_TOKEN”替换所有未包含在我们的词汇表中的单词。例如,如果我们的词汇表中不包括“nonlinearities”这个单词,那么句子“nonlineraties are important in neural networks”就会变成“UNKNOWN_TOKEN are important in Neural Networks”。单词“UNKNOWN_TOKEN”将成为我们词汇表的一部分,并且我们将像其他单词一样预测它。当我们生成新文本时,我们可以再次替换“UNKNOWN_TOKEN”,例如,通过获取我们词汇表中不存在的随机抽样单词,或者我们可以只生成句子,直到我们得到一个不包含未知标记的句子为止。
3.在开头和结尾处添加特殊标记。
我们还想了解哪些单词在句子的开头和结尾出现。为了实现这一点,我们在每个句子之前添加一个特殊的“SENTENCE_START”标记,并在每个句子之后添加一个特殊的“SENTENCE_END”标记。这使我们能够询问:假设第一个标记是“SENTENCE_START”,下一个单词(实际上是句子的第一个单词)可能是什么?
4. 构建训练数据矩阵
我们的循环神经网络的输入是向量,而不是字符串。因此,我们创建了一个单词到索引的映射,`index_to_word`和`word_to_index`。例如,单词“友好”可能在索引2001处。训练样本x可能是`[0, 179, 341, 416]`,其中0对应于`SENTENCE_START`。相应的标签y将是`[179, 341, 416, 1]`。请记住,我们的目标是预测下一个单词,因此y只是x向量向后移动一个位置,并且最后一个元素是`SENTENCE_END`符号。换句话说,上面的单词`179`的正确预测将是实际下一个单词的`341`。
您可以使用Web数据进行游戏:词汇量=8000,未知标记="UNKNOWN_TOKEN",句子开始标记="SENTENCE_START",句子结束标记="SENTENCE_END"。
# 读取数据并追加SENTENCE_START和SENTENCE_END标记 print("正在读取CSV文件...") with open(r'data\reddit-comments-2015–08.csv', 'r', encoding="utf-8") as f: reader = csv.reader(f, skipinitialspace=True) # reader.next() # 将完整评论拆分成句子 sentences = itertools.chain(*[nltk.sent_tokenize(x[0].lower()) for x in reader]) # 追加SENTENCE_START和SENTENCE_END sentences = ["%s %s %s" % (sentence_start_token, x, sentence_end_token) for x in sentences] print("已处理%d个句子。" % (len(sentences))) # 对句子进行分词 tokenized_sentences = [nltk.word_tokenize(sent) for sent in sentences]
# 计算单词频率 word_freq = nltk.FreqDist(itertools.chain(*tokenized_sentences)) print("发现%d个独特的单词标记。" % len(word_freq.items()))
# 获取最常用的单词,并构建“index_to_word”和“word_to_index”向量。 vocab = word_freq.most_common(vocabulary_size-1) index_to_word = [x[0] for x in vocab] index_to_word.append(unknown_token) word_to_index = dict([(w,i) for i,w in enumerate(index_to_word)])
print(“使用词汇量 %d。” % 词汇量大小)print(“我们词汇表中最不常见的单词是 '%s',出现了 %d 次。” %(词汇表[-1][0],词汇表[-1][1]))
# 用未知的标记替换除我们词汇表之外的所有单词 for i, sent in enumerate(tokenized_sentences): tokenized_sentences[i] = [w if w in word_to_index else unknown_token for w in sent]
打印(“\n示例句子:‘%s’”%sentences [0])打印(“\n预处理后的示例句:‘%s’”%tokenized_sentences [0])或使用莎士比亚的十四行诗:导入调用的refrom nltk.tokenize
#字母 = "([A-Za-z])" #前缀 = "(先生|圣|夫人|小姐|博士)[.]" #后缀 = "(有限公司|股份有限公司|初级|高级)" #开头词 = "(先生|夫人|小姐|博士|教授|船长|陆战队上尉|空军中尉|他的|她的|它的|他们的|我们的|但是|然而|那个|这个|无论何处)" #缩略词 = "([A-Z][.][A-Z][.](?:[A-Z][.])?)" #网址 = "[.](com|net|org|io|gov|edu|me)" #数字 = "([0–9])"
#词汇量 = 8000词汇量 = 3000
unknown_token = “未知标记”sentence_start_token = “句子开始”sentence_end_token = “句子结束”
保持html结构,将以下英文文本翻译成简体中文: def clean_roman_numerals(text): pattern = r”\b(?=[MDCLXVIΙ])M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})([IΙ]X|[IΙ]V|V?[IΙ]{0,3})\b\.?” return re.sub(pattern, ‘&’, text) def clean_roman_numerals(text): 正则表达式 = r”\b(?=[MDCLXVIΙ])M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})([IΙ]X|[IΙ]V|V?[IΙ]{0,3})\b\.?” 返回 re.sub(正则表达式, ‘&’, text)。
# 读取数据并添加SENTENCE_START和SENTENCE_END标记
print(“正在读取文本文件…”)
with open(r'data\shakespeare-sonnets.txt', 'r') as f:
text = f.read()
text = text.replace(",", "。")
text = text.replace(":", "。")
text = text.replace(";", "。")
text = text.replace("?", "。")
text = text.replace("!", "。")
text = clean_roman_numerals(text)
# text = re.sub(prefixes, "\\1
计算词频 word_freq = nltk.FreqDist(itertools.chain(*tokenized_sentences)) print("发现%d个唯一词令牌。" % len(word_freq.items()))
# 获取最常见的单词,构建索引到单词和单词到索引的向量。 vocab = word_freq.most_common(vocabulary_size-1) index_to_word = [x[0] for x in vocab] index_to_word.append(unknown_token) word_to_index = dict([(w,i) for i,w in enumerate(index_to_word)])
print(“使用词汇量%d.” % 词汇量大小) print(“我们词汇库中出现最少的单词是“%s”,仅出现了%d次。” %(词汇[-1] [0],词汇[-1] [1]))
# 用未知标记替换所有不在我们词汇表中的单词 对于枚举标记化句子中的i和sent,如果w在word_to_index中,则tokenized_sentences[i]等于sent中的w,否则等于未知标记。
print(“\n 示例句子: ‘%s’”%句子[0])print(“\n 预处理后的示例句子:‘%s’”%tokenized_sentences[0])len(tokenized_sentences)tokenized_sentences[5]sentences [1:5]让我们创建训练数据:X_train = []y_train = []for idx,sent在enumerate(tokenized_sentences [:-1])中:X_train.append([word_to_index [w] for w在sent中])y_train.append([word_to_index [w] for w in tokenized_sentences [idx + 1] ] [: len([word_to_index [w] for w in sent])] ))X_trainnp.array([[1,2,3],[1,2],[1]])pip show pandasX_train = np.asarray(X_train)y_train = np.asarray(y_train)X_train.shapey_train.shapeX_train = np.asarray([[word_to_index [w] for w in sent [:-1]] for sent in tokenized_sentences])y_train = np.asarray([[word_to_index [w] for w in sent [1:]] for sent in tokenized_sentences])X_train.shapetype(X_train)让我们打印一个训练数据示例x_example,y_example = X_train [1000],y_train [1000]print(“x:\n%s\n%s”%(” “。join([index_to_word [x] for x in x_example]),x_example))print(”\ n y:\n%s\n%s“%(”。“join([index_to_word [x] for x in y_example]),y_example))
`word_dim` 是我们的词汇大小,而 `hidden_dim` 是我们的隐藏层大小(我们可以选择它)。
让我们更具体地看一下为我们的语言模型设计的RNN的形式。输入x将是一系列单词(就像上面打印的例子一样),每个x_t是一个单词。但还有一件事情:由于矩阵乘法的工作原理,我们不能简单地使用一个单词索引(比如36)作为输入。相反,我们将每个单词表示为大小为“词汇量大小”的独热向量。
例如,索引为36的单词将是所有0和位置在第36个的1的向量。因此,每个x_t将成为一个向量,x将成为一个矩阵,每行代表一个单词。
我们将在神经网络代码中执行此转换,而不是在预处理中执行。我们的网络输出o具有类似的格式。每个o_t都是一个`vocabulary_size`元素的向量,每个元素代表该词成为句子中下一个单词的概率。
让我们回顾一下RNN的方程式:
s_t &= \tanh(Ux_t + Ws_{t-1}) \\o_t &= \mathrm{softmax}(Vs_t) s_t &= \tanh(Ux_t + Ws_{t-1}) \\o_t &= \mathrm{softmax}(Vs_t)
假设我们选择词汇大小 C = 3000 和隐藏层大小 H = 100。您可以将隐藏层大小看作我们网络的“记忆”。使其更大可以让我们学习更复杂的模式,但也会导致额外的计算。那么我们有:
x_t & R^3000 o_t & R^3000 s_t & R^100U & R^100 乘以 3000W & R^100 乘以 100V & R^3000 乘以 100
U、V 和 W 是我们网络中的权重。请注意,它们是代码版本中到目前为止使用的权重的转置(因此第一维表示下游层中神经元的数量,而不是上游层中的神经元)。它们是我们希望从数据中学习的参数。因此,我们需要学习总共 2HC + H² 个参数。
在C=3000和H=100的情况下,总计为610,000。
尺寸也告诉我们模型的瓶颈。请注意,因为x_t是一个独热向量,将其与U相乘基本上与选择U的一列相同,因此我们不需要执行完整的乘法运算。
然后,在我们的网络中,最大的矩阵乘法是Vs_t。这就是为什么我们尽可能想保持我们的词汇量小的原因。
初始化参数U、V和W可能有些棘手。
我们不能只将它们初始化为0,因为这将导致我们所有层中的对称计算。我们必须随机初始化它们。
由于正确的初始化似乎对训练结果有影响,因此在这个领域进行了大量的研究。事实证明,最佳的初始化取决于激活函数(\tanh在我们的情况下),其中一个推荐的方法是在区间$\left[-\frac{1}{\sqrt{n}}, \frac{1}{\sqrt{n}}\right]$内随机初始化权重,其中n是前一层的输入连接数。
通常来说,只要将参数初始化为小的随机值,大多数情况下都能正常工作。
类RNN:def __init__(self, word_dim, hidden_dim=100, bptt_truncate=4):#分配实例变量self.word_dim = word_dimself.hidden_dim = hidden_dimself.bptt_truncate = bptt_truncate#随机初始化网络参数self.U = np.random.uniform(-np.sqrt(1. / word_dim), np.sqrt(1. / word_dim), (hidden_dim, word_dim))self.V = np.random.uniform(-np.sqrt(1. / hidden_dim), np.sqrt(1. / hidden_dim), (word_dim, hidden_dim))self.W = np.random.uniform(-np.sqrt(1. / hidden_dim), np.sqrt(1. / hidden_dim), (hidden_dim, hidden_dim))让我们实现前向传播:def softmax(x):“”“为x中的每组分数计算softmax值。”“”e_x = np.exp(x-np.max(x))return e_x / e_x.sum()def forward_propagation(self, x):#时间步长T = len(x)#在前向传递过程中,我们保存所有的隐藏状态s因为需要之后。#我们为初始隐藏层添加一个额外的元素,将其设置为0s = np.zeros((T + 1, self.hidden_dim))s[-1] = np.zeros(self.hidden_dim)#每个时间步的输出。同样,我们将它们保存以备后用。o = np.zeros((T, self.word_dim))#对于每个时间步...for t in np.arange(T):#注意,我们正在使用U[t]对x进行索引。这与使用一个独热向量乘以U是相同的。s[t] = np.tanh(self.U [:,x[t]] + self.W点积(s [t-1]))o[t] = softmax(self.V点积(s [t]))返回[o,s]
RNN.forward_propagation = 前向传播
我们不仅返回计算输出,还返回隐藏状态。我们稍后会使用它们来计算梯度,并通过在此处返回它们来避免重复计算。每个“o”都是一个表示词汇表中单词概率的向量,但有时,例如在评估我们的模型时,我们只想要具有最高概率的下一个单词。我们称这个函数为“predict”:def predict(self,x):#执行前向传递并返回最高分数的索引o,s = self.forward_propagation(x)np.argmax(o,axis = 1)返回
RNN.predict = 预测 让我们尝试看一个实例输出: print("x:\n%s\n%s" % (" ".join([index_to_word[x] for x in X_train[10]]), X_train[10])) np.random.seed(17) model = RNN(词汇量大小) o, s = model.forward_propagation(X_train[10]) print(o.shape, o)
对于句子中的每个单词(上面的16个单词),我们的模型进行了8000次预测,代表下一个单词出现的概率。
那是因为我们选择了词汇量大小C = 8000,因此我们的输出层有8000个神经元。
以下是每个单词的最高概率预测的索引:for i in predictions: print(i)len(index_to_word)
预测结果 = model.predict(X_train[10]) print(predictions.shape, predictions) print("x:\n%s" % (" ".join([index_to_word[x] for x in predictions])))
好的,所有参数目前尚未受过训练。
计算损失
为了训练网络,我们需要一种衡量它失误的方式。我们称之为损失函数 L,我们的目标是找到最小化我们训练数据的损失函数的参数 U、V 和 W。
一个常见的选择作为损失函数的是交叉熵损失。
如果我们有N个训练样本(文本中的单词数)和C个类别(词汇表的大小),那么关于我们的预测o和真实标签y的损失由以下公式给出:
L(y,o) = -{1}{N} \sum_{n \in N} y_{n} \log o_{n} L(y,o) = -{1}{N} \sum_{n \in N} y_{n} \log o_{n}
这个公式看起来有点复杂,但它真正做的事情只是在我们的训练示例上进行求和,并根据我们的预测偏离度来添加损失。y(正确的单词)和o(我们的预测)离得越远,损失就越大。我们实现了函数`calculate_loss`:
保持 HTML 结构,将以下英文文本翻译成简体中文: def calculate_total_loss(self, x, y): L = 0 # 对于每个句子... for i in np.arange(len(y)): o, s = self.forward_propagation(x[i]) # print(“o ka shape”,o.ndim)#我们只关心“正确”单词的预测 correct_word_predictions = o[np.arange(len(y[i])), y[i]] # correct_word_predictions = o[np.arange(len(y[i]))] # 根据我们的偏差添加损失 L += -1 * np.sum(np.log(correct_word_predictions)) return L
def calculate_loss(self, x, y): # 将总损失除以训练样例数 N = np.sum((len(y_i) for y_i in y)) return self.calculate_total_loss(x,y)/N
RNN.calculate_total_loss = 计算总损失 RNN.calculate_loss = 计算损失
随机预测的损失应该是多少?
那将为我们提供一个基准,并确保我们的实施是正确的。
我们的词汇量为C个,因此每个词平均预测概率应为1/C,这将产生损失$L = -\frac{1}{N} N \log\frac{1}{C} = \log C$。
type(np.arange(len(y_train[0])),y_train[0])y_train[8] type(np.arange(len(y_train [0])),y_train [0])y_train [8]
# 为节省时间,限制1000个样例打印(“随机预测的期望损失:%f” % np.log(词汇量))(“实际损失:%f” % model.calculate_loss(X_train [:1000],y_train [:1000]))
## 通过时间反向传播进行训练
我们会迭代所有训练样本,在每次迭代中我们会将参数轻微调整,以减小误差。
这些指令是由损失梯度给出的:\frac{\partial L}{\partial U},\frac{\partial L}{\partial V},\frac{\partial L}{\partial W}。
我们也需要一个学习率,它定义了我们在每次迭代中希望迈出多大的步长。
因为层权重参数在网络中的所有时间步骤中是共享的,所以每个输出的梯度不仅取决于当前时间步骤的计算,还取决于其之前的时间步骤!
我们以训练样例(x,y)作为输入并返回梯度\ frac {\ partial L} {\ partial U},\ frac {\ partial L} {\ partial V},\ frac {\ partial L} {\ partial W}。
def bptt(self, x, y): T = len(y) # 进行正向传播 o, s = self.forward_propagation(x) # 我们在这些变量中累积梯度 dLdU = np.zeros(self.U.shape) dLdV = np.zeros(self.V.shape) dLdW = np.zeros(self.W.shape) delta_o = o delta_o[np.arange(len(y)), y] -= 1. # 对于每个输出反向传播... for t in np.arange(T)[::-1]: dLdV += np.outer(delta_o[t], s[t].T) # 初始delta计算 delta_t = self.V.T.dot(delta_o[t]) * (1 - (s[t] ** 2)) # 通过时间反传(至多为self.bptt_truncate步) for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]: # print “Backpropagation step t=%d bptt step=%d “ % (t, bptt_step) dLdW += np.outer(delta_t, s[bptt_step-1]) dLdU[:,x[bptt_step]] += delta_t # 更新下一步的delta delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2) return [dLdU, dLdV, dLdW]
RNN.bptt = bptt (循环神经网络. BPTT = BPTT)
梯度检验
无论何时实现反向传播,都建议同时实现梯度检查,这是验证您的实现是否正确的一种方法。梯度检查的思想是参数的导数等于该点的斜率,我们可以通过稍微改变参数然后除以变化来近似计算。
\frac{\partial L}{\partial \theta} \approx \lim_{h \to 0} \frac{J(\theta + h) - J(\theta -h)}{2h} (保持HTML结构)将以下英文文本翻译为简体中文:
我们接着将使用反向传播计算出的梯度和上述方法估算出的梯度进行比较。如果没有明显的差异,那么就没问题了。近似需要为每个参数计算总损失,所以梯度检查非常昂贵(请记住,上面的示例中有超过一百万个参数)。因此,在具有较小词汇量的模型上执行检查是个好主意。
def gradient_check(self, x, y, h=0.001, error_threshold=0.01): # 使用反向传播计算梯度。我们想检查这些梯度是否正确。bptt_gradients = model.bptt(x, y) # 我们要检查的所有参数列表。model_parameters = ['U', 'V', 'W'] # 检查每个参数的梯度 for pidx, pname in enumerate(model_parameters): # 从模型中得到实际参数值,例如,model.W参数 = operator.attrgetter(pname)(self) print("正在执行参数%s的梯度检查,大小为%d。" % (pname, np.prod(parameter.shape))) # 迭代参数矩阵的每个元素,例如,(0,0),(0,1)... it = np.nditer(parameter, flags=['multi_index'], op_flags=['readwrite']) while not it.finished: ix = it.multi_index # 保存原始值,以便稍后重置 original_value = parameter[ix] # 利用 (f(x+h) – f(x-h))/(2*h) 估计梯度 parameter[ix] = original_value + h gradplus = model.calculate_total_loss([x],[y]) parameter[ix] = original_value – h gradminus = model.calculate_total_loss([x],[y]) estimated_gradient = (gradplus – gradminus)/(2*h) # 将参数重置为原始值 parameter[ix] = original_value # 使用反向传播计算出的该参数的梯度 backprop_gradient = bptt_gradients[pidx][ix] # 计算相对误差:(|x – y|/(|x| + |y|)) relative_error = np.abs(backprop_gradient – estimated_gradient) / ( np.abs(backprop_gradient) + np.abs(estimated_gradient)) # 如果误差过大,则失败梯度检查 if relative_error > error_threshold: print("梯度检查错误:parameter=%s ix=%s" % (pname, ix)) print("+h 损失:%f" % gradplus) print("-h 损失:%f" % gradminus) print("估计梯度:%f" % estimated_gradient) print("反向传播梯度:%f" % backprop_gradient) print("相对误差:%f" % relative_error) return it.iternext() print("参数%s的梯度检查通过。" % (pname))
RNN.gradient_check = 梯度检查
为避免执行数百万次昂贵的计算,我们使用更小的词汇量进行检查。
grad_check_vocab_size = 100np.random.seed(10)model = RNN(grad_check_vocab_size, 10, bptt_truncate=1000)model.gradient_check([0,1,2,3], [1,2,3,4]) grad_check_vocab_size = 100 np.random.seed(10) model = RNN(grad_check_vocab_size, 10, bptt_truncate=1000) model.gradient_check([0,1,2,3], [1,2,3,4])
## 梯度下降实现
一个名为 `sdg_step` 的函数计算梯度并对一个批次执行更新。
然后,一个外循环循环遍历训练集并调整学习速率。
# 执行一步 SGD.def numpy_sdg_step(self, x, y, learning_rate): # 计算梯度 dLdU、dLdV、dLdW = self.bptt(x, y) # 根据梯度和学习率调整参数 self.U -= learning_rate * dLdU self.V -= learning_rate * dLdV self.W -= learning_rate * dLdW
RNN.sgd_step = numpy_sdg_step#外部SGD循环#—模型:RNN模型实例#—X_train:训练数据集#—y_train:训练数据标签#—learning_rate:SGD的初始学习率#—nepoch:遍历完整数据集的次数#—评估损失数后:评估此许多个时期之后的损失
使用随机梯度下降训练模型,X_train和y_train为训练数据,学习率为0.005,迭代100次,在每次迭代后评估损失。我们记录损失值以便之后绘制图表。num_examples_seen跟踪已处理的训练样本数量。若损失增加,则调整学习率。对于每个训练样本,执行一个随机梯度下降步骤进行优化模型。我们可以测试一下模型训练的时间:使用RNN模型进行训练,词汇表大小为vocabulary_size。执行model.sgd_step(X_train[10], y_train[10], 0.005)代码的执行时间即可。
梯度下降的一步在我的笔记本电脑上大约需要34毫秒(Web数据需要120毫秒)。
我们的训练数据中大约有2,766个例子(如果使用Web数据,则有80,000个例子),因此一次迭代(整个数据集上的迭代)需要几十分钟(使用Web数据则需要几个小时)。
多个世代将需要很多小时(甚至对于Wen的数据可能需要数天甚至数周!),而与OpenAIs、Googles和Facebook正在使用的数据相比,我们仍在使用较小的数据集!
研究人员已经确定了许多可以使模型计算更少的方法,例如使用分层softmax或添加投影层以避免大矩阵乘法(请参见[这里]或[这里])。
让我们尝试用小数据集运行 SGD 并检查损失是否实际下降:
vocabulary_sizenp.random.seed(17)
# 训练数据的一个小子集看看会发生什么模型 = RNN(词汇量大小)损失 = train_with_sgd(model, X_train[:100], y_train[:100], nepoch=10, evaluate_loss_after=1)
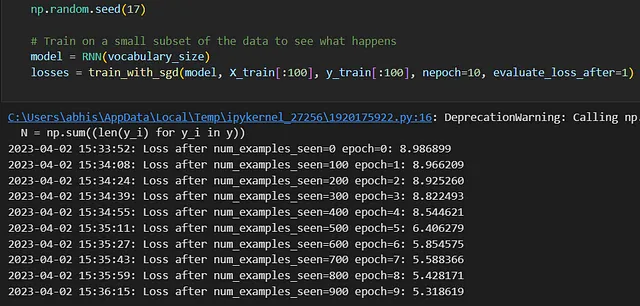
耶!我们的损失在单调递减 :-)
生成文本
现在我们已经有一个模型了,虽然它可能不是很训练有素,但我们可以让它为我们生成新的文本!让我们实现一个帮助函数来生成新的句子:
def generate_sentence(model, senten_max_length): # 我们以开始标记开始句子 new_sentence = [word_to_index[sentence_start_token]] # 重复直到我们得到结束标记,目前保持句子少于senten_max_length个词 while (not new_sentence[-1] == word_to_index[sentence_end_token]) and len(new_sentence)
样本 = np.random.multinomial(1,nrm_v) 抽样的词 = np.argmax (样本) 新句子.append(抽样的词)
#print(new_sentence) sentence_str = [index_to_word[x] for x in new_sentence[1:-1]] #print(sentence_str) return sentence_str num_sentences = 10 senten_min_length = 7 senten_max_length = 20 保留HTML结构,将以下英文文本翻译成简体中文: #print(new_sentence) 句子_str = [index_to_word[x] for x in new_sentence[1:-1]] #print(sentence_str) 返回sentence_strnum_sentences = 10 senten_min_length = 7senten_max_length = 20
对于 i 在范围内的循环(num_sentences):sent = [] #我们想要长句子,而不是只有一两个单词的句子 而 len(sent)
好吧,我们无法在Anaconda笔记本中编写ChatGPT,但这基本上就是语言模型编程的方式!
我们的香草循环神经网络无法生成有意义的文本,因为它没有训练所有单词。
在你训练所有单词后,你会发现它无法学习那些相距数步之远的单词之间的依赖关系。这就是为什么当递归神经网络首次被发明时,它们未能获得广泛的流行。虽然它们理论上很优美,但在实践中并不好用,而我们一开始并没有完全理解为什么。
幸运的是,现在关于训练循环神经网络的困难已经得到了[更好的理解]。
更加复杂的循环神经网络模型,例如LSTMs,是许多任务的最新技术。今天,在自然语言处理中,变形金刚是王者!
导入tarfile模块#打开文件file = tarfile.open('hin_mixed_2019_10K.tar.gz')#提取文件file.extractall('./data')file.close()
# 维护 html 结构,将以下英文文本翻译为简体中文: import re from nltk import tokenize
#字母=“([A-Za-z])”#前缀=“(先生|圣|夫人|小姐|博士)[.]”#后缀=“(公司|有限公司|初级|高级)”#开头=“(先生|女士|小姐|博士|教授|船长|上尉|尉|他\s|她\s|它\s|他们\s|他们的\s|我们的\s|我们\s|但\s|然而\s|那\s|这\s|无论何处)”#首字母缩略词=“([A-Z][.][A-Z][.](?:[A-Z][.])?)"#网站=“[.](com|net|org|io|gov|edu|me)”#数字=“([0-9])”
vocabulary_size = 8000vocabulary_size = 3000
词汇量为8000词汇量为3000
未知标记 = "UNKNOWN_TOKEN" 句子开头标记 = "SENTENCE_START" 句子结尾标记 = "SENTENCE_END"
def clean_roman_numerals(text): pattern = r”\b(?=[MDCLXVIΙ])M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})([IΙ]X|[IΙ]V|V?[IΙ]{0,3})\b\.?” return re.sub(pattern, ‘&’, text) 清理罗马数字(text): 模式 = r”\b(?=[MDCLXVIΙ])M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})([IΙ]X|[IΙ]V|V?[IΙ]{0,3})\b\.?” return re.sub(模式,‘&’,text)
# 读取数据并追加SENTENCE_START和SENTENCE_END标记
print("读取txt文件...")
with open('data\hin_mixed_2019_10K\hin_mixed_2019_10K-sentences.txt', 'r', encoding="utf-8") as f:
text = f.read()
text = text.replace(",", ".")
text = text.replace(":", ".")
text = text.replace(";", ".")
text = text.replace("?", ".")
text = text.replace("!", ".")
text = clean_roman_numerals(text)
# text = re.sub(prefixes,"\\1
# 统计单词频率 word_freq = nltk.FreqDist(itertools.chain(*tokenized_sentences)) print("发现%d个独特的单词令牌。" % len(word_freq.items()))
# 获取最常见的单词,并建立索引到单词和单词到索引向量 vocab = word_freq.most_common(vocabulary_size-1) index_to_word = [x[0] for x in vocab] index_to_word.append(unknown_token) word_to_index = dict([(w,i) for i,w in enumerate(index_to_word)])
print("使用词汇量为%d。" % 词汇量大小)print("我们词汇表中出现次数最少的词是“%s”,出现了%d次。" % (vocab[-1][0], vocab[-1][1]))
将所有不在我们词汇表中的单词替换为未知标记。对于枚举的句子,对于其中的每个单词,若该单词存在于单词-索引中,则保留该单词,否则替换为未知标记。
print("”\n示例句子:'%s'" % sentences[0])print("”\n处理后的示例句子:'%s'" % tokenized_sentences[0])X_train = np.asarray([[word_to_index[w] for w in sent[:-1]] for sent in tokenized_sentences])y_train = np.asarray([[word_to_index[w] for w in sent[1:]] for sent in tokenized_sentences])x_example,y_example = X_train [1000],y_train [1000]print("x:\n%s\n%s" % (" ".join([index_to_word[x] for x in x_example]), x_example))print("\n y:\n%s\n%s" % (" ".join([index_to_word[x] for x in y_example]), y_example))print("x:\n%s\n%s" % (" ".join([index_to_word[x] for x in X_train[10]]), X_train[10]))np.random.seed(17)model = RNN(vocabulary_size)o,s = model.forward_propagation(X_train[10])print(o.shape,o) predictions = model.predict(X_train[10])print(predictions.shape,predictions)print("x:\n%s" % (" ".join([index_to_word[x] for x in predictions])))# 仅限 1000 个示例,以节省时间print("对于随机预测的期望损失:%f" % np.log(vocabulary_size))print("实际损失:%f" % model.calculate_loss(X_train[:1000],y_train[:1000]))grad_check_vocab_size = 100np.random.seed(10)model = RNN(grad_check_vocab_size,10,bptt_truncate = 1000) model.gradient_check([0,1,2,3],[1,2,3,4])np.random.seed(17)model = RNN(vocabulary_size)%timeit model.sgd_step(X_train[10],y_train[10],0.005)np.random.seed(17)
# 在数据的小子集上进行训练以了解情况 model = RNN(vocabulary_size) losses = train_with_sgd(model, X_train[:100], y_train[:100], nepoch=10, evaluate_loss_after=1) num_sentences = 10 senten_min_length = 7 senten_max_length = 20
对于i在范围内的句子:句子= [] #我们要长句子,不是只有一两个单词的句子,而当len(sent)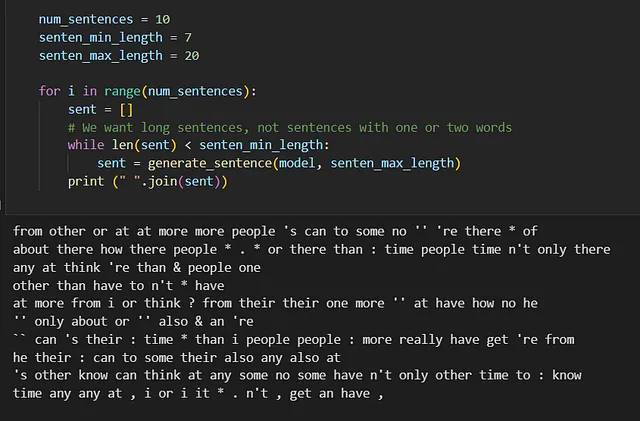
结论
总之,本文提供了一个全面且易于理解的指南,教读者如何使用RNN构建语言模型。从理解RNN背后的理论到实现和训练模型,本文提供了宝贵的见解和实用的建议。
我们开始讨论语言模型的重要性及其在各个领域中的应用。然后,我们深入探讨了RNN的架构以及它们如何适合建模诸如语言这样的序列数据。它对那些有兴趣探索基于RNN的语言模型在自然语言处理任务中潜力的人们而言,是一个宝贵的资源。









