改变未来:释放变形金刚深度学习的力量
介绍
在当今数字时代,自然语言理解对于人机交互至关重要。变压器以其异常的捕捉上下文关系和细微差别的能力,在这个领域成为了改变游戏规则的因素。从机器翻译到文本摘要,问答系统到情感分析,变压器在各种任务上产生了显著影响。
什么是变压器?
变形金刚,是深度学习中值得注意的组件,属于机器学习大家庭中的一部分。深度学习旨在模仿人类大脑的复杂运作,包含了各种专门针对特定任务的算法。与传统的机器学习方法不同,深度学习可以在监督、半监督或无监督模式下运行,提供了空前的灵活性。
利用深度学习的一个重要优势在于它从数据中提取丰富的特征。通过同时处理海量信息,深度学习使我们能够以人类的理解方式来感知物体。这种能力使深度学习在图像分类方面尤为有价值,其中它分析高维数据的能力突出。此外,深度学习在时序数据和自然语言处理(NLP)等领域的顺序数据分析中发挥着至关重要的作用。
为了有效地分析序列数据,循环神经网络(RNNs)占据了核心地位。RNNs拥有内部存储器,可以保留先前数据点的关键信息并进行准确的预测。然而,RNNs存在一些限制,比如训练速度慢和梯度消失问题。这是随着我们深入神经网络而失去关键数据的问题。为了克服这些障碍,研究人员开发了创新性的RNN变体,如双向RNN和长短期记忆(LSTM)网络。
双向循环神经网络复制整个循环神经网络链,能够分析前向和反向时间顺序的输入。该方法为模型提供了未来的上下文。另一方面,长短时记忆循环神经网络包含反馈连接,可以处理整个数据点序列,而不仅仅是单个数据点。虽然长短时记忆循环神经网络可以处理并行输入,但计算代价高,训练速度较慢。双向循环神经网络虽然比长短时记忆循环神经网络快,但仍面临类似的计算复杂性。
进入变形金刚——一种革命性的循环神经网络,它在捕捉复杂的词依赖关系的同时改变了序列到序列转换的方式。与传统的循环神经网络不同,变形金刚放弃了递归,采用了注意力机制,正如经典论文“注意力机制全都是你”的强调。这些注意力机制将单词在输入序列中的相对位置分配给它们,从而促进了更好的理解和处理。变形金刚已经在图像分类、自然语言处理和机器翻译等各个领域广泛应用。
一些使用Transformer的最着名的语言模型包括谷歌的BERT和OpenAI的GPT-3。这些模型利用了Transformer的强大能力,实现了前所未有的语言理解和生成能力。
建筑学
不会过多介绍建筑,会简洁地完成它。
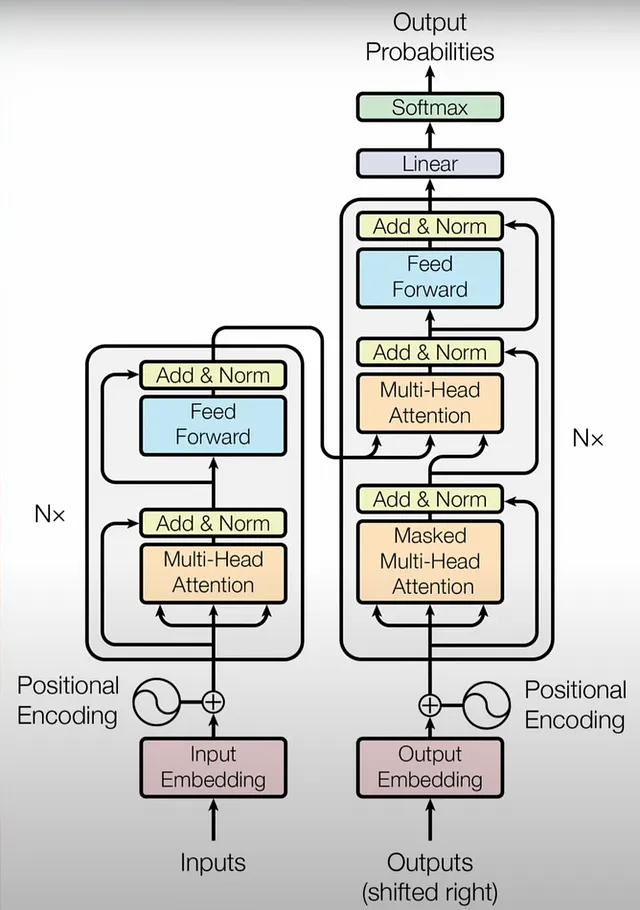
这是Transformer的基本概述。
让我逐步解释一下
高水平
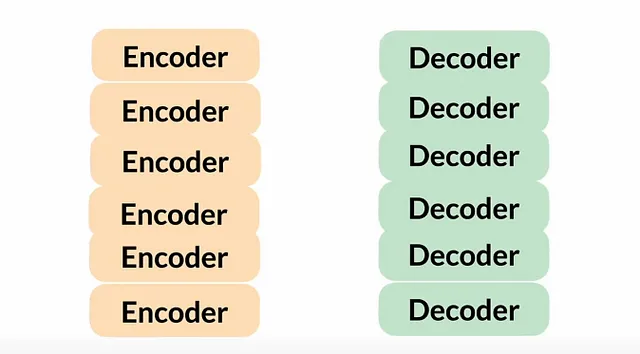
Transformer 的架构由 6 个编码器和 6 个解码器组成。
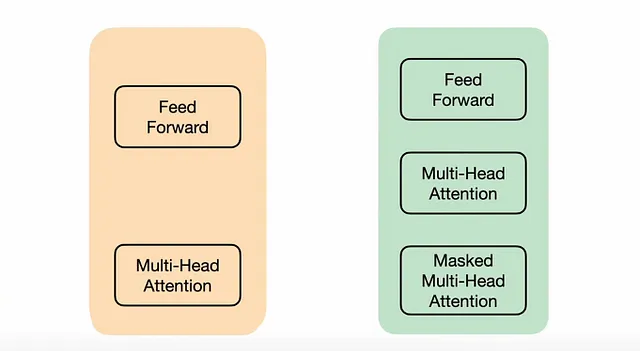
每个编码器都有1个自注意层和1个前馈神经层。另一方面,每个解码器都有2个自注意层和1个前馈神经网络层。
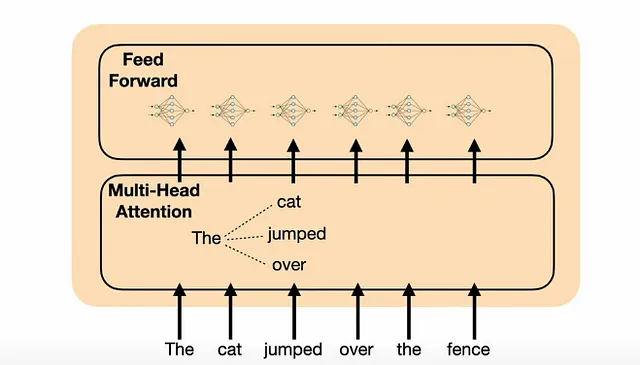
并行化是通过一次性将所有数据输入网络实现的,而不是一个一个地输入。在编码器的自注意力层中,该层中的所有词汇将相互比较,但传递到前馈神经网络时,它们会被单独处理。每个编码器都有不同的注意力和前馈机制层。
输入层
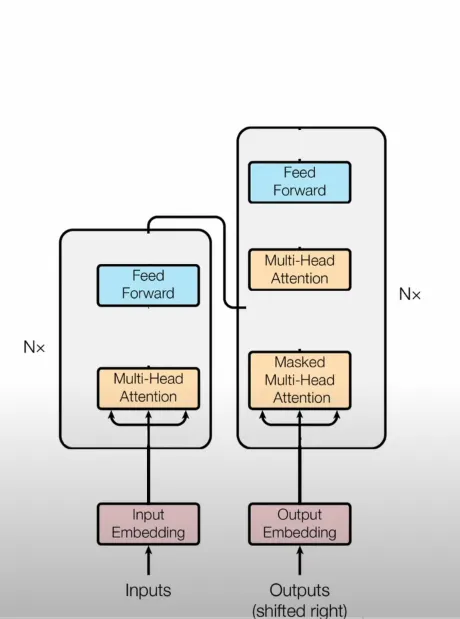
变压器中的输入和输出是嵌入式的,这意味着它们被转换为向量。
位置编码
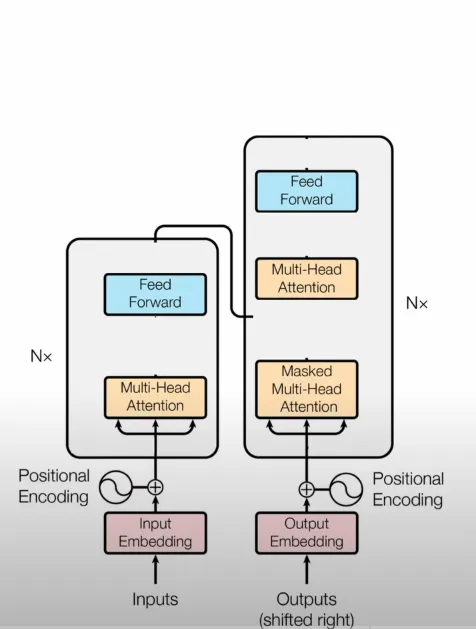
位置编码被添加在词嵌入上,提供有关每个单词在句子中位置的信息。由于Transformer缺乏循环,位置编码在理解单词顺序方面发挥着至关重要的作用。
输出层
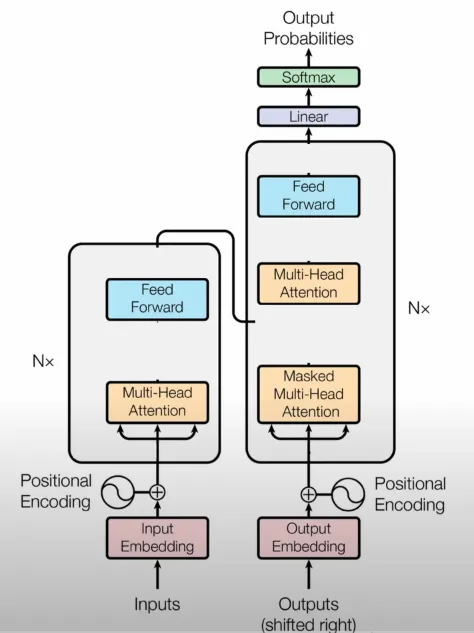
输出层将输出转换为可解释的格式。它由一个向量组成,其长度等于词汇表中单词的总数。向量中的每个单元格都表示在句子中下一个出现的单词可能性。
添加和规范化层
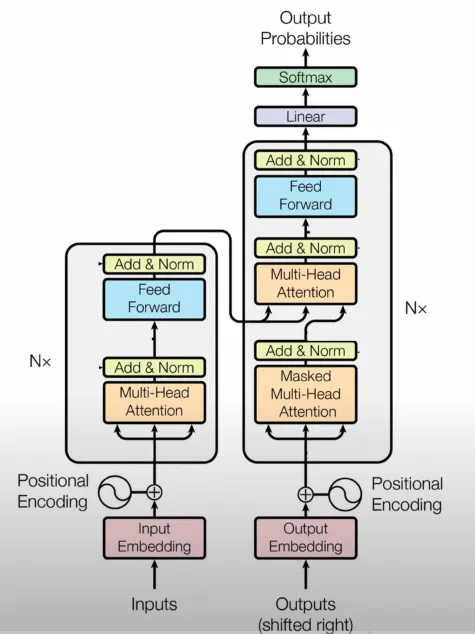
除了自注意力和前馈层外,Transformer 还包括两个额外的层,称为“加”层和“标准化”层。这些层对子层的输出执行标准化,具体使用层标准化而不是批标准化。
跳连通性
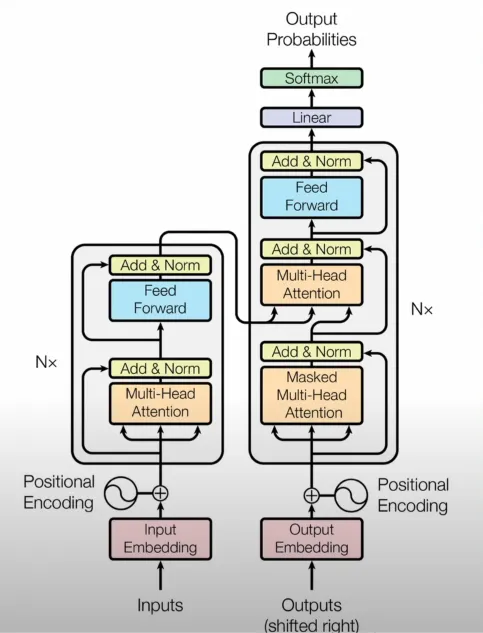
Transformer 架构还包括跳跃连接,其中一些数据绕过自注意力和前馈层,直接发送到标准化层。这有助于模型保留重要信息并避免遗忘。
区分变形金刚的想法
位置编码和注意力层
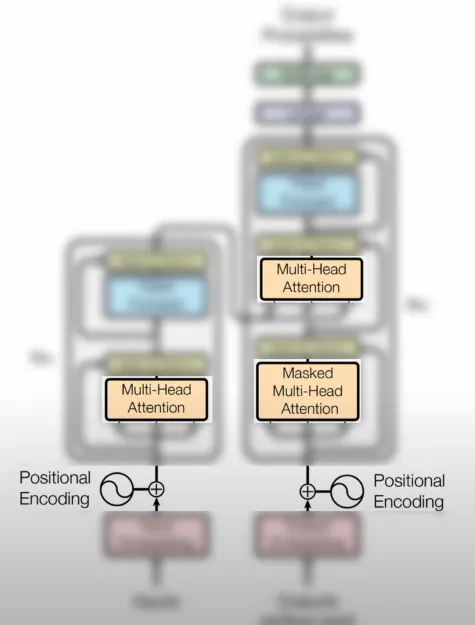
多头注意力
在多头注意力机制中,输入句子中的所有单词都相互比较,从而实现对单词之间关系的全面分析。
掩码多头注意力
在掩码多头注意力中,仅将前面的单词与句子中特定的单词进行比较,限制了比较的范围。
所有图片均摘自YouTube视频https://www.youtube.com/watch?v=_UVfwBqcnbM&t=15s。
注意力机制
什么是注意力?
注意力可以定义为集中精力关注特定元素,同时忽略可能在此刻看似无关的其他元素的能力。在机器学习的背景下,注意力指的是教模型专注于输入的特定方面,而忽略其他方面,从而增强其有效解决给定任务的能力。
为了说明这一点,考虑以下句子,“我要去银行贷款申请。” “银行”这个词可以有很多意思,例如金融机构或者血库。然而,在这个特定的句子中,我们打算指金融机构。理解上下文并解释句子中单词的含义,就是我们所说的注意力。虽然变形金刚可能不具备完美的上下文化能力,但它们目前是我们最有希望的方法。
变压器使用自我注意机制,使它们在计算相同序列的表示时可以建立不同段之间的连接。这种机制允许模型关注相关部分并捕捉输入数据内的关系。
“注意力”是如何工作的?
在关注的语境下,有两个主要组成部分:编码器和解码器。编码器接收输入序列并将其转换为一个固定形状的状态表示。另一方面,解码器将这个固定形状的状态映射到一个输出序列。
Scaled Dot Product (规模化点积)
缩放点积是注意力机制中使用的一组线性代数运算。它包括三个矩阵:q,k和v,分别称为查询、键和值。这个概念直接源自数据库,其中值由键索引,用户可以查询检索特定值。在自我注意力的情况下,没有外部用户或控制器发出查询,相反,机器本身通过反向传播调整q、k和v的值,以模拟用户与数据库的交互。
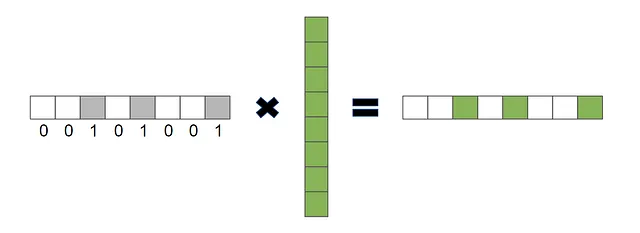
例如,检索过程可以表示为α⃗⋅v⃗,其中α⃗是一个由1和0构成的独热向量,v⃗是包含被检索值的向量。在这种情况下,向量α⃗充当查询,在输出中将包含从v⃗中α⃗= 1的值。
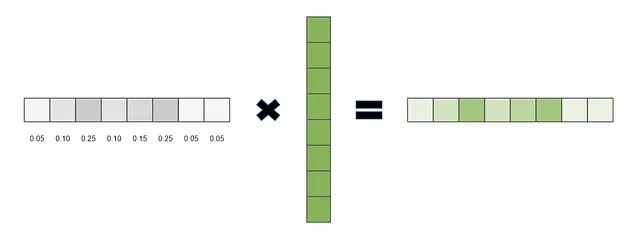
通过去除查询向量的限制,并允许0~1之间的浮点数值,我们可以实现加权比例检索。
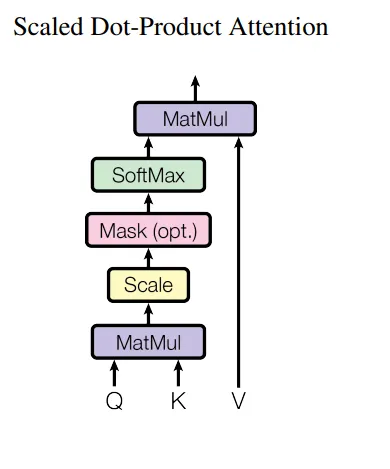
缩放点积注意力遵循类似的原则,以相同的方式使用向量乘法。应用softmax函数以获取标准化权重。
多头注意力(Multi-Head Attention)
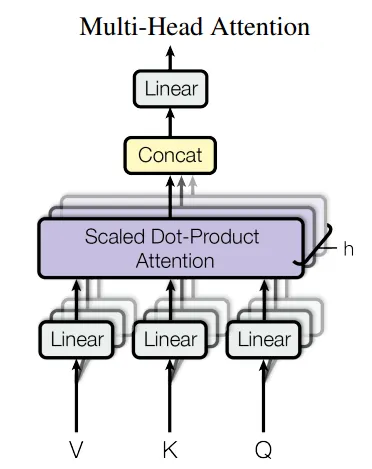
多头注意力机制与使用单个输入不同,它包含多个键、值和查询矩阵。每个注意力模块的操作是为了发现不同输入之间的关系并生成情境嵌入。然后,这些嵌入通过线性神经网络,连接到输出模块。这种方法通过允许模型捕捉数据中的多方面和依赖关系,提高了性能并促进了训练的稳定性。
网址https://www.baeldung.com/cs/attention-mechanism-transformers的图像和内容
结论
总之,变形金刚革命性地改变了人工智能领域,其能够捕捉上下文关系并提高性能。多头注意力增强了模型的理解和训练稳定性。尽管存在限制,变形金刚在弥补人与机器理解之间的差距方面标志着重要的里程碑。在这个变革性的人工智能领域中,令人兴奋的进展正在前方。