Cuda内存不足?学习大于内存模型的基础知识。

想要训练一个机器学习模型吗?是一个巨大的模型正在耗尽您GPU的内存吗?或者它是一个较小的模型,但是您正在试图将海量数据输入它中。
随着我们将LLM进一步推广至各个领域,这些问题将越来越频繁地出现。我将提供一般概述和有关这些问题的论文链接,让您深入了解您觉得有趣的内容。
我相信还有很多方法我没有涉及到,但我只会介绍我个人研究或测试过的技术。
此外,这是关于 ChatGPT 推理的我最喜欢的一篇论文。
GPU需求的粗略计算:Transformer模型
###
# Training
###
Model_Parameters_Memory = Params * Precision
Intermediate_Activations_Memory = Seq_Length * Seq_Length * Attention_Heads * Precision
Optimizer_Memory = Params * Optimizer_Requirement
Gradient_Memory = Params * Precision
Input_Memory = Input_Size * Batch_Size * Precision
Total_Memory_Training = Model_Parameters_Memory + Intermediate_Activations_Memory + Optimizer_Memory + Gradient_Memory + Input_Memory
###
# Inference
###
Model_Parameters_Memory = Params * Precision
Intermediate_Activations_Memory = Seq_Length * Seq_Length * Attention_Heads * Precision
Input_Memory = Input_Size * Batch_Size * Precision
Total_Memory_Inference = Model_Parameters_Memory + Intermediate_Activations_Memory + Input_Memory以下是微软一篇试图更准确地实现此功能的论文。
处理大于内存模型时有两个核心概念。
- 将模型分割成不同组件,分布在不同的机器上。
- 将模型卸载到计算机上,直到您需要处理它。
- 他们通过减少某些方面来缩小这个模型,同时试图尽可能保持其相似性。
分割模型
将模型拆分其实很简单。你如何将模型分成特定计算机上的某些部分?我不会讨论像行或列分割方法这样的细节。
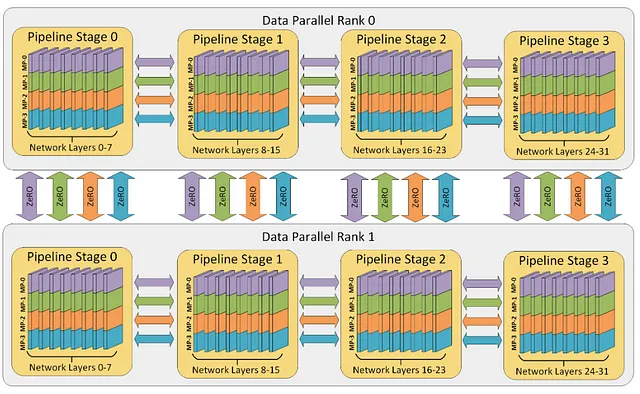
数据并行:多数据模型之一
在这里,我们将数据跨越不同机器上的GPU进行拆分。设备之间通信梯度,使我们能够有效更新模型参数。
模型并行:一个数据多个模型自动模型并行
假设我们的模型太大,无法适应单个GPU。这时就需要使用模型并行技术。我们将模型分配到多个GPU上,这些GPU可以在同一台机器上,也可以是不同设备。这种方式使我们能够高效地训练更大的模型。
管道并行性:一份数据,多种(但不同的)模型 Paper
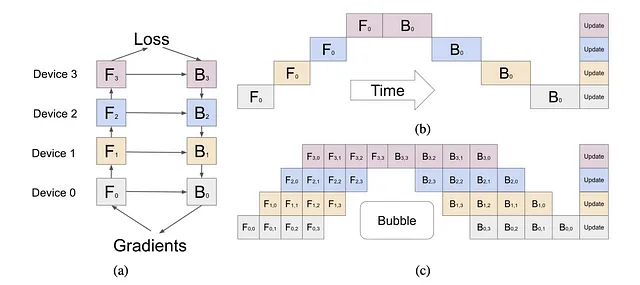
想象一下流水线。这就是管道并行的工作原理。我们把不同层的模型放在不同的GPU上,按顺序执行这些层。这样可以提高我们的计算效率和GPU利用率。
卸载模型
模型卸载是指允许在训练过程中将模型的某些部分存储在主设备之外以节省内存的技术。以下是一些标准的模型卸载技术:
渐变检查点:论文
这种技术通过在正向传递中丢弃中间输出并在反向传递期间重新计算它们来降低内存使用。这可以显着降低内存使用,但会增加计算成本。在此方法中,计算内容和时间还存在许多变化。
激活卸载:
这是一种更高级的模型卸载形式,其中激活张量(每一层的输出)在训练期间被卸载到CPU内存或磁盘上。这可以显着减少GPU内存的使用,但需要有效地管理未打包的数据以最小化对训练速度的影响。
参数卸载:
这种技术将模型参数转移至CPU内存或磁盘上。通常与激活函数转移一起使用,以进一步减少GPU内存的使用。
缩小模型
这里的核心概念是找到一种减小模型本身大小的方法。例如,用于让模型在你的手机上运行。
混合精度训练:论文
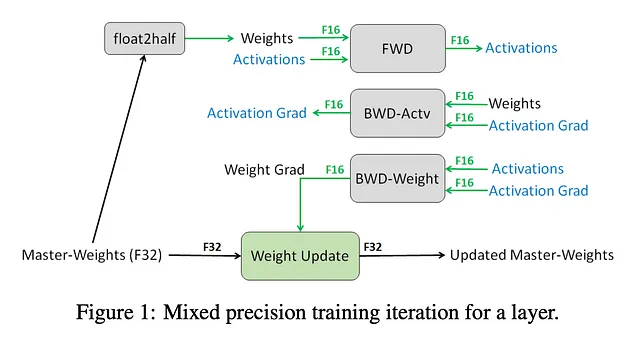
混合精度训练可以显著减少内存使用,针对某些模型部分使用低精度(半精度等)数据类型。这可以与其他卸载技术结合使用,以实现更显著的内存节省。
重要提示:
混合精度是加速训练和目前GPU制造的重要组成部分。如果您想知道为什么大公司几乎与您在家中使用的GPU一样快地“浪费”资金购买这些昂贵的GPU,您必须观看此视频,了解其中的真相。
查看图形以理解这些 Nvidia 的“荒谬”成本,希望你能联想到它们的关系。
方法的组合
外存训练: 论文
方法:优化器卸载、梯度卸载、参数卸载
这是一种更极端的模型卸载形式,整个模型存储在磁盘上,只有在需要时加载到GPU内存中的小部分。这允许训练庞大的模型,即使使用其他卸载技术,也无法适配单台计算机的内存。然而,这需要一个快速的存储系统来最小化对训练速度的影响。
转移:纸张
方法:优化器离线、梯度离线、参数离线。
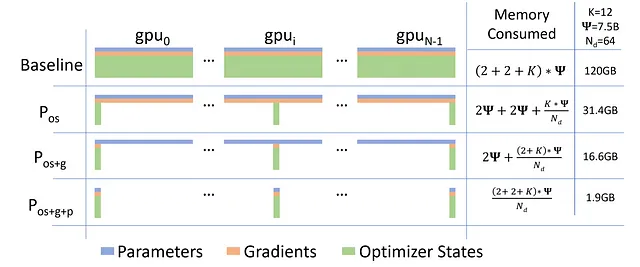
由微软开发的ZeRO是一种内存优化技术,可减少模型参数、梯度和优化器状态的内存占用。通过在数据并行进程之间划分这些元素,它可以实现模型与GPU数量成线性比例的扩展。
分片算法:论文
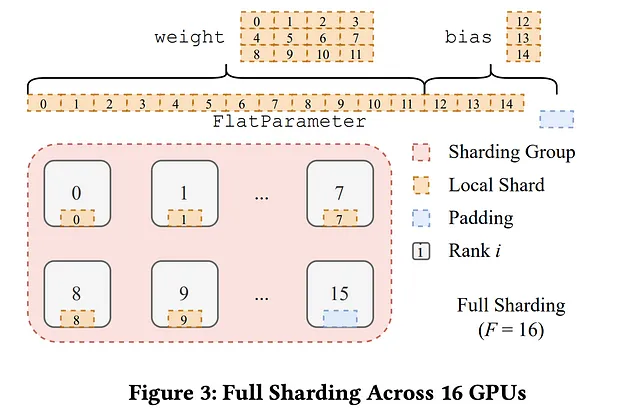
方法:优化器卸载,梯度卸载,参数卸载和数据并行。
真正的大型模型和数据集;我们使用分片技术。我们将模型和数据分割成多个部分并分布在不同的机器上,每个机器负责不同的模型和数据子集。这种方法是最近展示的方法之一,受到了Deepspeed离线机制的启发。