如何在Colab上免费使用GPT-Neo 2.7B
你是否渴望在 Colab 上使用强大的 GPT-Neo 2.7B,但又担心免费版的系统资源有限?别担心,我们为你提供了解决方案。在本文中,我们将为你介绍一种聪明的技巧,即使你的系统 RAM 较低,也能让你使用 GPT-Neo 2.7B。通过我们的分步指南,你将学习如何在 Colab 上释放 GPT-Neo 2.7B 的全部潜力,无论资源限制如何。准备好享受 GPT-Neo 2.7B 的惊人文本生成能力,不用担心系统要求!
步骤1:启用GPU加速
第一步是确保您的Colab笔记本电脑启用了GPU加速。按照以下简单步骤启用GPU加速:
- 在Colab笔记本的顶部单击“运行时”菜单。
- 从下拉菜单中选择“更改运行时类型”。
- 在“硬件加速器”栏目中,选择“GPU”作为硬件加速器。
- 点击“保存”按钮以应用更改。
启用 GPU 加速将允许您充分利用 GPU 的性能,在运行 GPT-Neo 2.7B 时显著提高性能。
步骤二:安装所需软件包。
为了开始,我们需要安装必要的包。打开一个新的Colab笔记本,在代码单元格中运行以下命令:
pip install -U --no-cache-dir transformers
pip install torch
pip install accelerate这些命令将安装变压器库、火炬和加速器,这些是使用GPT-Neo所必需的。
步骤3:加载模型和分词器。
导入必要的模块:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GPTNeoConfig接下来,让我们加载GPT-Neo 2.7B模型和分词器。将以下代码添加到新的代码单元格中:
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-2.7B")# Create a configuration for the model
config = GPTNeoConfig.from_pretrained('EleutherAI/gpt-neo-2.7B')# Define a custom model class with gradient checkpointing
class GPTNeoWithCheckpointing(AutoModelForCausalLM):
def forward(self, *inputs, **kwargs):
return super().forward(*inputs, **kwargs)# Instantiate the model with gradient checkpointing
model = GPTNeoWithCheckpointing(config)# Move the model to GPU
model = model.to('cuda')# Load the model to GPU
model = model.half() # Use torch.float16 for reduced memory usage
model = model.to('cuda')
这将安装分词器,创建一个带有梯度检查点的自定义模型类,并加载GPT-Neo 2.7B模型。我们将模型移动到GPU。
步骤4:生成文本
现在我们已经设置好了模型和分词器,让我们生成一些文本。将以下代码添加到新的代码单元格中:
# Generate text
input_prompt = "I am Gpt-neo"
input_ids = tokenizer.encode(input_prompt, return_tensors="pt").to('cuda')
generated_output = model.generate(input_ids=input_ids, do_sample=True, max_length=100)
generated_text = tokenizer.decode(generated_output[0], skip_special_tokens=True)这里我们定义一个输入提示并使用分词器进行编码。我们通过调用模型的生成方法来生成文本。do_sample=True参数启用随机抽样,max_length确定生成的文本的最大长度,您可以自定义模型生成参数。最后,我们使用分词器对生成的输出进行解码,以获取可读的文本。
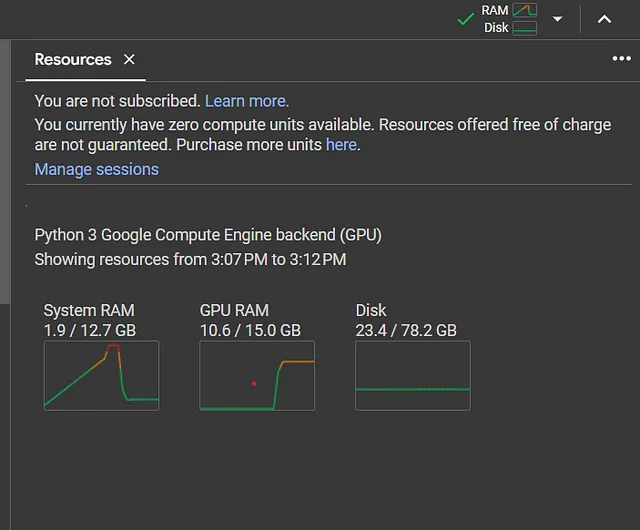
为什么使用梯度检查点?
Colab 提供有限的系统内存,免费版为12GB。加载像GPT-Neo 2.7B这样的大型模型很容易超出这个内存限制,从而导致内存不足错误。
为了克服这一限制,我们利用梯度检查点技术。梯度检查点技术可以让我们在内存和计算之间进行权衡,通过重新计算反向传播期间的中间激活状态,而不是将它们存储在内存中,来减少模型的内存占用。
通过使用梯度检查点技术,我们可以在Colab的有限资源上加载GPT-Neo 2.7B,而不会遇到内存问题。这种技术显著减少了加载过程中所需的GPU内存分配。