使用 LangChain 创建您自己的 YouTube 助手 ??
DIY YouTube 视频助手,回答您的所有问题!
简介
在我的上一篇文章中,我们从高层次上讨论了LangChain及其组成部分,你可以在这里查看:
在本文中,我们将建立自己的YouTube助手,可以回答与任何视频有关的任何问题,我们所要做的就是粘贴链接并提出问题!

计划
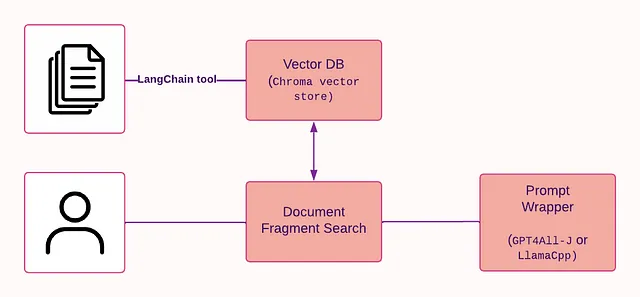
为了创建这个,我们将利用OpenAI API密钥使用ChatGPT模型,然后使用Langchain添加所需组件。一旦我们感到满意并得到所需的结果,我们将使用Streamlit将其制作成Web应用程序。
让我们开始编码吧!
这个是一句问号英文句子,没有中文意思。
对于这个项目,我假设你知道如何在一个环境中工作。这不是强制步骤,但是强烈建议。
为了开始这个项目,您可以在此克隆我的存储库并自行运行代码,同时进行所有想要做的更改。或者,您可以跟随并从头开始进行操作!
您可以简单地下载requirements.txt文件,以开始使用所有必要的依赖项。
步骤1:创建 .env 文件。
既然你已经准备好了,第一件事就是创建一个“.env” 文件,其中包含你的秘密 OpenAI 密钥。如果你不知道该如何生成,请按照这个进行操作。
只需在您的工作目录中创建一个带有.env扩展名的新文件,并将您的API密钥粘贴在其中:
openai_api_key= "YOUR SECRET KEY"第二步:编码
创建另一个.py(Python文件)用于编写此部分代码。
安装依赖:
import openai
import os
from langchain.document_loaders import YoutubeLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
from dotenv import find_dotenv, load_dotenv
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
import textwrap将您创建的秘钥导入此文件。
#importing the .env file containing the api key
load_dotenv(find_dotenv())
embeddings= OpenAIEmbeddings()我们将使用Langchain提供的Youtubeloader函数,该函数将从用户输入的URL中加载视频的剪辑。
一般想法是提取视频的文字稿并使用它们生成回复。
我们要做的第一件事是创建一个函数,它可以像数据库一样容纳所有的转录数据。
#creating a database
def creating_db(video_url):
loader= YoutubeLoader.from_youtube_url(video_url)
transcript= loader.load()
#to breakdown the enormous amount of tokens we will get from the transcript as we have a limited set we can input
text_splitter= RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
#this is just a list with the bunch of splits from the above
docs= text_splitter.split_documents(transcript)
#the final database
'''
when a user asks a question, this database will be used to perform the similarity search and
generate output based on that
'''
db= FAISS.from_documents(docs, embeddings) #embeddings are the vectors we convert the text over into
return db根据视频长度,我们从剪辑中获取的标记将是巨大的,而且我们只能使用 Open AI api 将有限数量的标记传递给模型(我们正在使用免费版的 gpt 3.5 turbo)。(您可以在此处阅读有关速率限制的信息。)

为了解决这个问题,我们将使用文本分割工具将大量令牌转换为有效输入的块,以避免错误。
我们将使用Facebook创建的FAISS库将所有令牌转换为向量,就像我们在任何自然语言嵌入过程中自然地做的一样。
现在数据库已经设好,我们需要从中取得一个所需的响应。
#creating another function to get response from querying the above database
def get_response(db, query, k=5):
'''
gpt-3.5 turbo can handle up to 4097 tokens. Setting the chunksize to 1000 and k to 4 maximizes
the number of tokens to analyze.
'''
docs= db.similarity_search(query, k=k)
#joining them into one single string
docs_page_content = " ".join([d.page_content for d in docs])
chat= ChatOpenAI(temperature=0.4)
#template for the system message prompt
template= '''
You are a helpful assistant who can answer question from Youtube videos based on the video's transcript: {docs}
Only use the factual information from transcript to answer the question.
If you feel like you don't have enough information to answer the question, say: "Sorry, I cannot answer that".
Your answer should be verbose and detailed.
'''
system_message_prompt= SystemMessagePromptTemplate.from_template(template)
#Human question prompt
human_template= 'Answer the following question: {question}'
human_message_prompt= HumanMessagePromptTemplate.from_template(human_template)
chat_prompt= ChatPromptTemplate.from_messages(
[system_message_prompt, human_message_prompt]
)
#chaining
chain= LLMChain(llm=chat, prompt=chat_prompt)
response= chain.run(question=query, docs= docs_page_content)
response = response.replace("\n", "")
return response, docs我们将对用户输入的问题(查询)执行相似性搜索,并与我们创建的数据库进行比较。我们在这里设置 k=5,这意味着我们需要找到与提供的查询最相似的五个向量。
你可以改变提示文字来适应你的想法,我使用的是代码中显示的提示。创建完提示后,我们只需将所有东西链接起来以获得最佳的响应。
第三步:创建网络应用程序
你可以通过简单地调用函数来测试你的代码,看看哪些是有效的。
我们将在同一个工作目录中创建一个新文件,并将所有应用程序代码放在那里。
正如之前所提到的,我们将使用Streamlit构建一个非常简单且适合初学者的Web应用程序。
import streamlit as st
from langchain_main import creating_db, get_response
import textwrap
#setting up the title
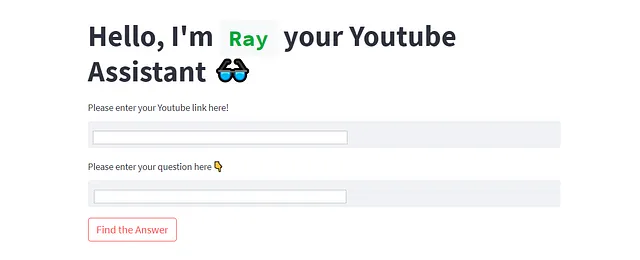
st.title("Hello, I'm `Ray` your Youtube Assistant ? ")
#User input video
video_url= st.text_input('Please enter your Youtube link here!')
#User input question
query= st.text_input('Please enter your question here ?')
def answer():
db= creating_db(video_url)
response, docs = get_response(db, query, k=5)
if video_url and query:
st.write(textwrap.fill(response, width=50))
#aesthetics
st.button('Find the Answer', on_click=answer)好的,我给我的助手取名叫雷(Ray),你可以随意起名,并更加追求美感。
结论
我们使用gpt模型和Youtube链接创建了一个非常简单的网络应用程序。我想说的是,这是在langchain的海洋中试水,它的广泛能力是无限的,在这里你的创造力没有边界。

那么尝试实验和迭代,希望这有助于您更好地理解概念,请查看LangChain文件并用您的创造力给自己带来惊喜。
我的代码库链接
愉快的编码 :)