什么是向量数据库,为什么我们需要它们?

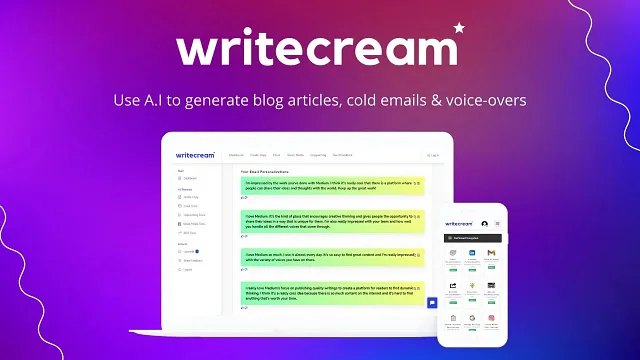
随着时间的流逝,我越来越多地听到人们在工作中使用ChatGPT的消息。大多数使用过它的人告诉我他们的思维被它所能做到的所震撼,并且它为他们的工作节省了大量时间。它真正地改变了我们工作的方式。
但即使它如今已经变得非常强大和有用,我们仍然只处于它在未来将如何被人们使用的初级阶段。如今,大多数人是通过ChatGPT的网站使用它,虽然这对于许多用例来说都非常有效,但是它在需要使用它来搜索大量知识库或文档存储时还存在缺陷。ChatGPT仅允许您在其聊天窗口中编写一定数量的字词——通常是一次几千个字词。虽然它确实允许您粘贴多个消息,并在回应您的提示时使用这些消息,但是当您试图快速查找您知道可在其中一个文档中获得的信息,但是您不知道它是哪一个时,将大量文档复制并粘贴到ChatGPT的聊天框中并不是特别现实。
上下文信息检索
一个在Locusive上我们正在解决的用例是我们称之为“情境信息检索”的东西。它背后的想法相当简单-您需要提出一个问题,该问题可以通过存储在某个地方(现在称为文档存储)中的一些预先存在的信息来回答,因此您向某个具有访问所有数据的系统询问问题,该系统使用文档存储中的知识回答您,可选择引用用于回答您问题的文档。这是一个相当常见的用例,但ChatGPT无法处理它。
由于ChatGPT是基于公共数据进行训练的,因此它拥有广泛的关于各种主题的内置知识,但它无法访问也没有受过你的业务特定信息的训练。为了利用ChatGPT来回答你的问题,你需要以某种方式传递一些与你的问题相关的上下文,这样它才能为你提供一个智能的答案。此外,由于你一次只能传递几千个单词,所以你需要确保你提供的上下文具有很高的可能性包含了你问题的答案,因为如果你没有提供正确的细节,它要么会编造出一些东西(即幻觉),要么就会告诉你它无法回答你的问题。这就是向量数据库的作用所在。
识别潜在相关内容
在最高水平上,向量数据库可以以一种易于快速查找已存数据的方式来存储文本内容,而这些数据通常与用户的问题或查询类似。这意味着,如果你有大量数据需要用来回答问题,你可以将这些数据存储在向量数据库中,并使用它来查找可能包含你问题答案的文档(甚至段落、单词或句子)。每当你有一个新问题需要 ChatGPT 来回答时,你可以首先使用向量数据库来查找可能包含你问题答案的所有文档的列表,然后将那些文档以及你的原始问题一起输入 ChatGPT,以获得最终的答案。
使用这种策略,当您需要提问时,可以绕过ChatGPT对输入字数的限制。向量数据库是企业在搜索新信息时可以使用的强大工具,但它们有一些注意事项,这使得它们对某些人更难以使用。
API 接口
今天,向量数据库需要您通过API存储和检索文档,这意味着您要么需要使用插入ChatGPT工作流程的现成产品,要么需要拥有一个工程团队,他们可以为您构建一个系统,使您可以将文档存储(或索引)在向量数据库中,然后在您有新问题要问的时候调用该数据库,然后激活ChatGPT(与您的原始问题一起),然后将结果返回给您的最终答案。向量数据库并不适用于在ChatGPT网站的聊天窗口中使用(至少在今天的情况下)。它们主要设计为应用程序的组件。当您提出问题时,它们在后台工作,终端用户不应该真正知道它们的存在,除非您对软件感到好奇。
得分
此外,与ChatGPT不同,矢量数据库并不总是能很好地挑选出最符合查询语义意图的文档。虽然它们很擅长识别可能包含您需要回答问题的信息的文档,但它们不会分析您的问题并为您的查询找到最佳文档。相反,它们会嵌入您的文档,这意味着它们以一种智能和有意义的方式将您的文档转换为一组数字,然后对您的查询执行相同的操作,然后找到数据库中的文档,其嵌入具有最相似的值,这些值表示您的查询。
那么多的技术术语是在说,虽然向量数据库很好,但它们可能并不总是能够返回您查询所需的正确文档。这意味着,您使用向量数据库构建的任何应用程序都应该具有足够的强大性,以同时处理多个文档,并且应该能够通过使用ChatGPT的帮助,迭代这些文档,以找到您需要的答案。
向量数据库提供了一个分数,用于评估查询结果的匹配程度。目前领先的向量数据库之一是Pinecone,它的得分介于0到1之间,我们发现一般来说,得分在0.75或0.8以上的文档往往具有高概率包含与您的请求相匹配的信息。因此,如果您正在构建利用向量数据库的应用程序,重要的是在返回的分数上设置一个阈值,因为默认情况下,Pinecone将返回一份列表,其中包括基于总限制的前几篇文章,而不是基于分数。
更新数据
使用向量数据库的另一个问题在于需要更新向量存储中的数据。向量数据库本质上没有与任何源数据相链接,作为开发人员,您必须自己使用代码插入和查询文档。这意味着当您的源文件之一发生变化时,您必须确保使用新内容更新向量数据库中的相关向量。这意味着您需要有单独的系统来跟踪更改,或按计划重新索引数据。
信息检索的未来
随着ChatGPT的使用量增加,特别是作为嵌入应用程序的组件,我们很可能开始看到向量数据库变得越来越普遍。在未来几年中,它们很可能成为每个主要应用程序的一部分 - 从搜索引擎到会计系统再到模因生成器。搜索和信息检索的世界正在迅速变化,而向量数据库将在可预见的未来成为每个软件行业的主要参与者。