利用ChatGPT进行医疗计划文件的数据提取
在今天的数据驱动环境中,自动化已经成为业务效率的支撑。本文将深入介绍一个旨在自动化提取福利和保障概述(SBC)文档中数据的创新项目。目标很简单:将通常以更传统的PDF格式提供的SBC文档转换为可读取的JSON格式,从而消除手动数据录入的繁琐过程。
想象一下节省的时间和减少的人为错误!这正是数据团队旨在达到的确切目标,不过不要泄露得太早,他们确实达到了目标。
在我们揭开项目的细节之前,了解技术框架是至关重要的。基础设施的重要部分是围绕ChatGPT API构建的,这是设计提取和结构化数据的模块的核心。这项任务的复杂性不小。然而,通过细致的准备和格式化,产生了一个连贯的结果。
技术实现:
为了产生一致的结果,必须在chatGPT API周围建立大量数据准备和格式化基础架构。该过程在以下文档中概述。
- 转换PDF为文本:该模块首先将输入的SBC PDF文件转换为纯文本,便于进行进一步处理和数据提取。
- 将PDF分成离散的块:然后将提取的文本分割成离散块,每个块代表原始文档中的特定部分或数据点。
- 为ChatGPT创建提示:为每个分段生成定制的提示,以指导ChatGPT准确提取所需信息。
- 使用ChatGPT API执行提示:生成的提示将发送到ChatGPT API进行处理,它利用OpenAI的GPT-4语言模型的能力从文本中提取相关信息。
- 合并 API 响应:从 ChatGPT API 收到的响应被合并成一个综合的 JSON 对象,其中包含了所有结构化和机器可读格式提取的信息。
- 编写响应到关系型数据库:最终,JSON 对象被写入关系型数据库,使得提取的数据可以轻松地存储、检索和进一步分析。
结果:
chatGPT的结果非常令人鼓舞。由于SBC文档中数据表示的标准化缺乏,一些领域比其他领域更容易被提取出来(即一些健康计划创造自己版本的SBC文档)。
- 在大约90%的文档中,该系统能够提取包括计划免赔额、个人超支限额和不包括服务在内的信息。
- 在约70%的文档中,系统能够提取有关网络内和网络外护理的赔付和共同保险相关信息,例如心理健康,门诊手术等。
- 在约30%的文档中,该系统能够提取药房福利。这种困难反映了健康计划表示不同药物层次的各种方式。
限制:1. 该项目只处理保险福利和覆盖范围摘要的PDF文件。所有医疗计划都被法律要求创建这样的文件,它们的格式受到管制,因此可以进行自动处理(请参见此处的模板)。要处理非标准医疗计划文件,需要完全新的方法来解决这个问题。
2. chatGPT返回的JSON中,有58%的键的拼写与系统消息所定义的完全不一致(例如,当指定children_eye_exam_out_of_network_value时返回childrens_eye_exam_out_of_network_value)。这将防止我们将输出写入关系表,其中列名是静态的。改进的提示工程和随后的chatGPT版本(例如GPT4)可能会大大减少此错误率。
附录
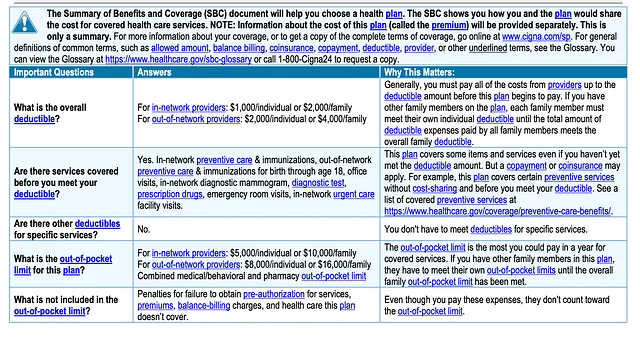
示例SBC:
系统返回的JSON: