RELAI为LLM幻觉检测设定了新的现代化标准
由: 王文校,Siddhant Bharti, Priyatham Kattakinda, Soheil Feizi.
请自行尝试:RELAI代理人可供个人和企业用户使用在:relai.ai。
摘要
- SimpleQA 数据集:OpenAI 最近发布了一个新的基于事实的数据集,揭示了顶级LLM模型(如GPT-4o和Claude-3.5-Sonnet)存在较高的臆想率。
- RELAI的验证代理:这些专业代理会自动检测和标记LLM输出中的幻觉,并实时处理。
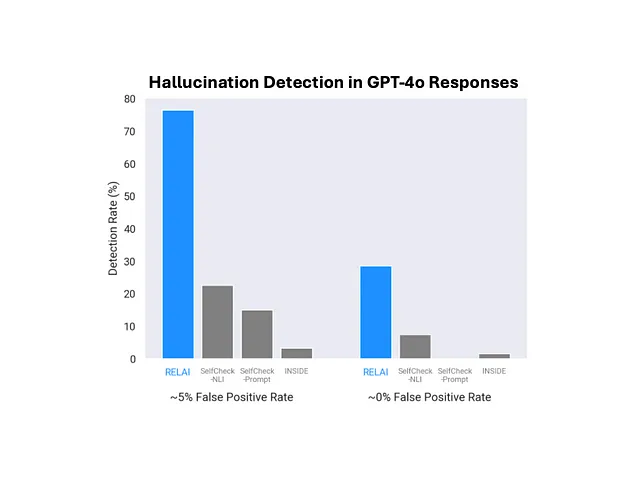
- RELAI建立了在幻觉检测方面的最新技术水平:对于GPT-4o,RELAI在5%的假阳性率下实现了76.5%的检测率,并在0%的假阳性率下实现了28.6%的检测率。RELAI在性能上远远超过现有的基准线。
简单问答数据集介绍
在2024年10月30日,OpenAI最近发布了SimpleQA数据集,为评估简短、寻求事实的查询中的真实性提供了一个强大的基准。SimpleQA侧重于各种主题的简短回答问题。该数据集最小化了歧义,并经过了彻底的质量检查,使其成为检测“幻觉”的理想测试场地——即语言模型中的不正确或捏造的答案。
以下是数据集中的一个示例样本:
提示:比尔·基恩在国家漫画家协会奖中获得最佳分发面板奖多少次?
地面真相:四次
在SimpleQA中,顶级LLM的幻觉发生率很高
尽管这个数据集被称为“简单”QA,但对于顶尖的LLMs来说,似乎并不简单。事实上,OpenAI在这里提供的分析表明,顶尖的LLMs在这个数据集上都遇到困难,导致幻觉率很高。
在我们的分析中,我们关注两个顶级的LLM:GPT-4o 和 Claude-3.5-Sonnet(版本20241022),并且在从数据集中随机抽取的200个提示上对它们进行评估。这里是展示它们准确性的表格:
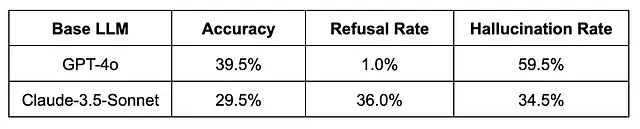
拒绝率是指基础模型无法提供答案(无论是正确还是错误)的样本所占的比例。在评估幻觉检测方法的性能时,我们只关注基础LLM产生响应的情况,就像放弃投票一样,没有意义的输出可以标记为幻觉或正确。我们注意到这些结果与OpenAI自己的见解一致,验证了我们的实验设置。
这里是GPT-4o在数据集中的一个样本的幻觉示例。
提示:Bil Keane 在国家漫画家协会奖中获得过多少次最佳综合画报奖?
地面的真相:四倍。
GPT-4o:比尔·基恩三次荣获国家漫画家协会最佳分发面板奖。
在顶尖的法学硕士课程中,幻觉频率之高凸显了对验证工具的需求,尤其是在关键领域如医疗保健和金融领域,可靠性至关重要。
RELAI的LLM验证代理
最近,RELAI公司引入了LLM验证代理,以实时检测和标记LLM的输出中的幻觉,提高了LLM在关键领域输出的可靠性,这些领域中事实的准确性至关重要。
LLM幻觉是由一系列复杂因素引起的,包括训练数据和输入标记化以及模型架构。为了解决这些挑战,RELAI的验证框架包括多样化和互补的验证代理,每个代理具有独特的功能以进行强力检测。
- 幻觉验证代理:该代理分析LLM生成的分布中的统计模式,通过标记表明缺乏事实依据的统计线索,检测潜在的幻觉。
- LLM验证代理:使用RELAI专有的LLM作为辅助模型,该代理对原始响应进行交叉参考以识别不一致之处,并标记可能具有事实错误的答案。
- 基于事实的LLM验证代理:该代理从可靠的、经过批准的来源检索和比较信息,将LLM生成的答案与这些参考资料进行匹配,添加额外的验证层。
这些代理有两种操作模式,用户可以设置。在“常规模式”(默认情况下),代理针对回复中的主要不准确之处,而在“强力模式”下,代理进行更深入的分析,甚至识别小的不准确之处。
由于这些代理使用互补信号来检测幻觉,因此将它们视为一个整体验证代理是很有用的。我们考虑两种情况:
- RELAI Ensemble Verifier-I:当所有个体代理检测到幻觉时,此代理标记幻觉。
- RELAI集成验证器-U:当至少一个个别代理检测到幻觉时,此代理标记幻觉。
一起,RELAI的验证代理人为幻觉检测提供了全面的解决方案,每个代理人专注于独特的方面 - 统计线索,交叉引用或来源验证 - 以确保多层次,可靠的验证过程。
评估设置
我们在SimpleQA数据集上评估了RELAI的验证代理,以及几种现有的基准方法用于幻觉检测。在评估幻觉检测方法时,有两个关键指标是必不可少的:
- 检测率(或真阳性率)是指基础LLM中被正确标记为幻觉的错误响应的百分比。
- 错误阳性率指的是来自基础LLM的正确响应中被错误标记为幻觉的百分比。
理想的幻觉检测器将具有100%的检测率和0%的误报率。
RELAI的LLM验证代理的一个关键优势是它们还为标记的响应提供解释,详细说明为什么响应可能含有幻觉。当基础模型的响应被标记时,用户可以查看代理的理由并采取明智的行动。这种以用户为中心的方法增强了对RELAI代理响应的信心,提供了超越其他基线模型的透明度,后者通常只为幻觉检测提供简单的标签。
以下是一个由RELAI验证代理标记的GPT-4o的幻觉示例。
提示:比尔·基恩(Bil Keane)在全国漫画家协会奖中获得最佳连载面板奖多少次?
地面真相:四次
GPT-4o: Bil Keane 三次获得国家漫画家协会最佳连载漫画奖。
RELAI的LLM验证器:比尔·基恩共获得了四次最佳综合面板奖,而不是三次。
RELAI的幻觉验证器:声称Bil Keane曾三次获得全国连环画家协会奖项最佳联合漫画奖是没有依据的。你应该交叉核实这一信息。
RELAI的Grounded LLM验证器:回应不准确。 Bil Keane在1967年、1971年、1973年和1974年四次赢得了国家漫画家协会最佳分发专栏奖,而不是三次。
参考:- 维基百科
在SimpleQA的这个例子中,RELAI的三个验证代理都标记了一种幻觉。
对于我们的数值实验,我们将代理回应转换成一个二进制标签,指示基础模型的回应是否包含幻觉。
基线方法
在我们的实验中,我们包含了三个现有的基线: 使用 NLI 的 SelfCheckGPT [引用],使用 LLM 提示的 SelfCheckGPT [引用] 和 INSIDE [引用]。我们还测试了 FAVA 方法 [引用],但由于它们在这个数据集上表现不佳,我们没有将它们包含在我们后续的分析中。
结果
首先,我们在SimpleQA数据集中评估GPT-4o响应的幻觉检测方法。下图说明了各种方法的检测率与误报率之间的关系。

在这个图中,“最佳”指的是一种方法,可以正确标记出所有的幻觉,而没有任何错误的阳性结果。我们从这个图中得出了几点观察。
- 在大约5%的假阳性率下,RELAI的Grounded LLM验证器实现了78%的检测率。
- 在接近0%的误报率下,RELAI的Ensemble Verifier-I实现了28.6%的检测率。这是值得注意的,因为将此代理添加到LLM中可以将幻觉率降低三分之一,而不会引入任何误报。
- 在不同的误报率体系下,RELAI明显优于现有的基准线。
任何验证方法的一个关键因素是其泛化能力。那些在 GPT-4o 上成功的代理商是否能在另一个基础模型上同样有效地表现?为了测试 RELAI 的代理商的泛化能力,我们选择了另一个流行的 LLM:Claude-3.5-Sonnet。下面的图示了在同一 SimpleQA 数据集中对 Claude 的回答进行各种方法的表现。
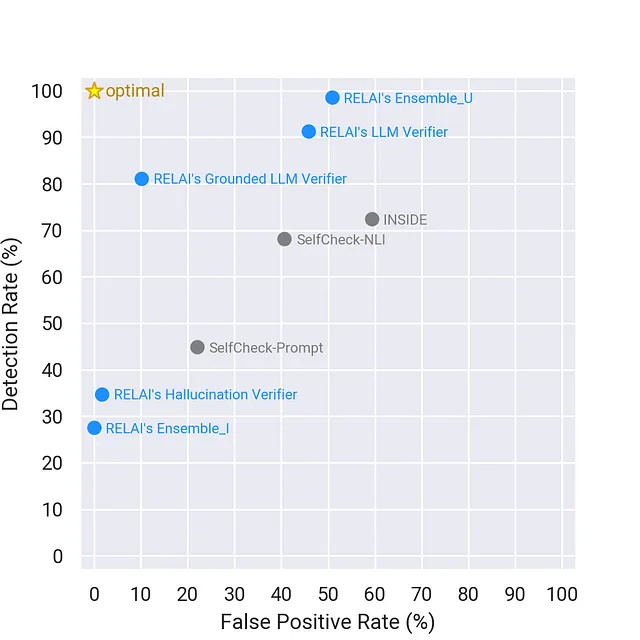
我们观察到在Claude-3.5-Sonnet上RELAI代理性能与GPT-4o上的表现类似的趋势。
- 在误报率约为10%的情况下,RELAI的Grounded LLM验证器实现了81%的检测率。
- 在接近0%的误报率下,RELAI Ensemble Verifier-I实现了27.5%的检测率。
- RELAI代理明显优于现有的基线。
如何使用RELAI的验证代理
RELAI提供了一个易于使用的平台,可以利用这些实时幻觉代理。您可以简单地选择一个基本模型(例如GPT-4o)进行聊天,并添加一个或多个验证代理以实时标记模型响应中潜在的幻觉。下面是一个图示,展示了RELAI代理如何在实践中运作:
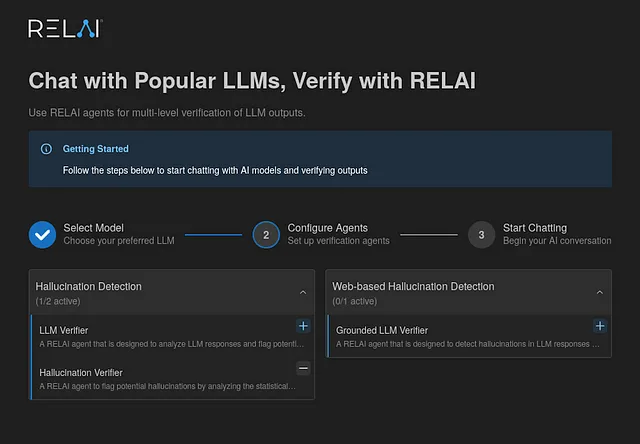
结论
RELAI的LLM验证代理设立了一个新的标准在幻觉检测中,远远超过现有的方法。这些代理可供个人用户在relai.ai上使用。RELAI还提供API访问权给企业,让他们能够与他们的AI可靠性解决方案无缝集成。

这个故事发布在生成式人工智能上。在领英上与我们联系并关注Zeniteq,以及时了解最新的人工智能故事。
订阅我们的通讯和YouTube频道,获取有关生成人工智能的最新新闻和更新。让我们一起共同塑造人工智能的未来!