在企业知识库上建立一个私人ChatGPT。
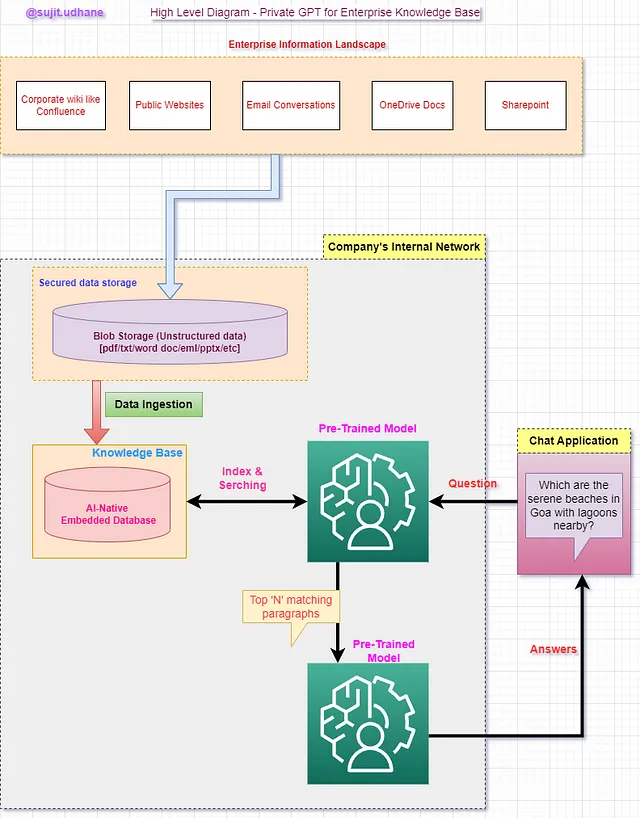
1. 商业场景:企业级别的信息分散在不同的位置,包括公司维基、公共网站、OneDrive、个人电子邮件账户、SharePoint等等。由于业务层面的复杂性、不同的贡献者和多个版本的文件,找到适当的信息以易于人们理解的形式是困难的。对于那些新来公司的人或需要快速获取有关信息以前进的终端用户来说,这变成了一项艰巨的任务。用户要么花更长的时间去找到必要的信息或在这种情况下采取适当的行动,要么放弃。
2.解决方案:一个集中式的知识存储库,汇集结构化和非结构化的材料,并以问题和答案形式向终端用户提供访问。
3. 解决方案的高层次视图:
4. 尝试该解决方案的先决条件:需要掌握一门编程语言。无论您是否在人工智能/机器学习方面有先前的专业知识。
5.解决方案的GitHub网址-https://github.com/imartinez/privateGPT
6.请按照ReadMe文件中提到的步骤进行操作(这些步骤已非常详细记录)。
步骤1:将所有材料存储到块或文件存储中。每当您想要引入新文档时,都需要执行此步骤。数据管道型解决方案将是实现此目标的好主意。
第二步:数据摄取用于将数据加载到AI本地嵌入式数据库中。
如果你遵循克隆的 Git 存储库中的 ReadMe 文件,那么你需要在命令行上执行一个步骤:python ingest.py。
第三步:运行Python应用程序,在CLI上接受问题提示。
如果您遵循从克隆的Git库中读取的ReadMe文件,那么有一步需要在命令行上执行:python privateGPT.py。
您现在可以在那里测试您自己的GPT与公司的知识库。
步骤四(可选):
CLI方法将限制可以访问您的解决方案的用户数量,使其不适用于生存策略。因此,您必须创建一个Web应用程序,以使您的聊天程序能够通过互联网访问。
这个GitHub网址将使你能够做到这一点 - https://github.com/SamurAIGPT/privateGPT。
最终,外部世界可以挖掘你们的企业知识库,获得有价值的信息。
7. 熟悉一些关键的GPT关键词是有益的。
预训练模型:如GPT或BERT等预训练模型是在大量数据上训练的,以学习数据中的模式和关系。这些模型捕捉了一般知识,并可以针对特定任务进行微调。它们在自然语言处理、图像识别或推荐系统等任务中表现出色。
AI原生嵌入式数据库:AI原生嵌入式数据库专门为优化AI应用的数据存储、检索和处理而设计。它提供了高效索引、实时数据处理、可扩展性和与AI框架的集成等特性。
LangChain 是一个基于语言模型的应用程序开发框架。
SentenceTransformers是用于最先进的文本、文字和图像嵌入的Python框架。该框架可用于构建100多种不同语言的句子和文本嵌入。然后,可以使用余弦相似性来比较这些嵌入,以识别具有共同意义的句子。对于语义文本相似性搜索、语义搜索或释义挖掘,这非常有帮助。
8. 解决方案的优势
预防数据丢失。组织的网络将继续存储所有敏感数据。
训练模型可用的选择很多。重点可以从创建或训练模型转移到解决业务问题。
私有GPT框架备受喜爱,在GitHub上拥有超过29k星。
各种模型都很容易进行配置。我使用了 GPT4All 进行实验,它是一个来自 OpenAI 的开源替代 ChatGPT 的工具。
9.参考文献
如何使用自己的数据创建私人聊天GPT 在本文中,我们将学习如何使用自己的数据创建一个私人聊天生成模型,以便让我们的机器人能够更自然地与用户进行交互。我们将使用 GPT-2 作为生成模型,并介绍如何准备数据、训练模型以及测试它。让我们开始吧!
在接下来的文章中,我将讨论一些其他受欢迎的框架,用于创建Chat GPT样式的应用程序。
我希望这篇文章对你有所帮助。如果是这样,请鼓掌。