在GPU加速下本地运行LLMs:在Kubernetes上设置NVIDIA GPU运算符、Ollama和Open WebUI的逐步指南
你好!
大型语言模型(LLMs)的概念自ChatGPT等工具进入我们的生活以来一直受到重视。我们中许多人都很好奇如何在我们自己的环境中利用这些模型的力量。
在这篇文章中,我将引导您通过在带有NVIDIA GPU的Kubernetes集群上设置NVIDIA GPU Operator、Ollama和Open WebUI的过程。
到最后,您会完成所有设置并且能够自己测试一个模型。这些步骤可能听起来有点技术性,但我向您保证,只要有正确的指导,它们都是直接明了的,我会一直和您并肩前行。
首先,让我们简要地了解一下Ollama和Open WebUI是什么。
Ollama: 一个用于在本地运行和管理LLMs的工具。Ollama使开发人员或用户可以轻松安装、配置和使用这些模型。它提供了必要的工具,通过简单的命令行和API在本地环境中高效地运行模型。它允许用户构建私人模型,同时保持数据隐私。
打开WebUI:一个专为用户友好交互而开发的开源Web界面,用于与大型语言模型进行交互。通过Open WebUI,您可以通过网络浏览器使用语言模型,从而获得更轻松的体验。这意味着您可以在基于网络的环境中对大型语言模型进行实验或使用,而无需命令行知识。由于它是开源的,因此可以进行自定义和进一步开发。
先决条件:
- 一个Kubernetes集群(在这个演示中我正在运行版本1.31)
- 在集群中具有NVIDIA GPU的工作节点(我在此演示中使用的是A40)
- 船长
- Kubectl
- 可选地,NGINX Ingress Controller 和 Cert-Manager 用于入口访问。
步骤1:安装NVIDIA GPU Operator
首先,使用以下命令添加官方的NVIDIA Helm仓库:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
然后,在gpu-operator命名空间中安装它:
helm install --wait nvidia-gpu-operator -n gpu-operator --create-namespace nvidia/gpu-operator
等待一段时间后,命令kubectl get po -n gpu-operator的输出应该如下所示:
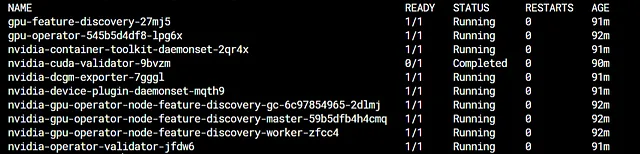
一旦成功安装了NVIDIA GPU运算符,将自动向带有NVIDIA GPU的工作节点添加以下注释。

接下来,让我们安装Ollama。
第二步:安装 Ollama
首先,为Ollama创建一个命名空间:
kubectl create ns ollama
接下来,应用以下部署和服务的YAML文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ollama
namespace: ollama
spec:
strategy:
type: Recreate
selector:
matchLabels:
name: ollama
template:
metadata:
labels:
name: ollama
spec:
containers:
- name: ollama
image: ollama/ollama:latest
env:
- name: PATH
value: /usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
- name: LD_LIBRARY_PATH
value: /usr/local/nvidia/lib:/usr/local/nvidia/lib64
- name: NVIDIA_DRIVER_CAPABILITIES
value: compute,utility
ports:
- name: http
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: 1
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
---
apiVersion: v1
kind: Service
metadata:
name: ollama
namespace: ollama
spec:
type: ClusterIP
selector:
name: ollama
ports:
- port: 80
name: http
targetPort: http
protocol: TCP
要通过HTTPS和域名访问Ollama API,请根据您的设置编辑并应用以下Ingress。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ollama-ingress
namespace: ollama
annotations:
cert-manager.io/cluster-issuer: "letsencrypt-prod"
nginx.ingress.kubernetes.io/ssl-redirect: "true"
spec:
tls:
- hosts:
- ollama-api.suleyman.academy
secretName: ollama-tls
rules:
- host: ollama-api.suleyman.academy
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: ollama
port:
number: 80
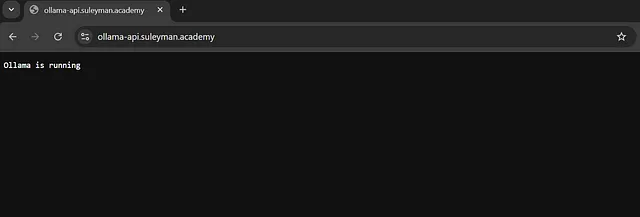
如果您在访问ollama-api.suleyman.academy时看到以下响应,则表示设置成功。
安装好了Ollama后,让我们继续安装Open WebUI,以便更轻松地使用。
步骤 3:安装 Open WebUI
首先,添加 Open WebUI Helm 仓库:
helm repo add openwebui https://helm.openwebui.com
helm repo update
然后,定制并运行以下Helm安装命令:
helm install open-webui open-webui-demo \
--set ollama.enabled=false \
--set ingress.enabled=true \
--set ingress.class="nginx" \
--set ingress.annotations."cert-manager\.io/cluster-issuer"="letsencrypt-prod" \
--set ingress.host="chat.suleyman.academy" \
--set ingress.tls=true \
--set ingress.existingSecret="openwebui-tls"
等待一会儿后,请访问https://chat.suleyman.academy,并点击“注册”按钮完成管理员注册。
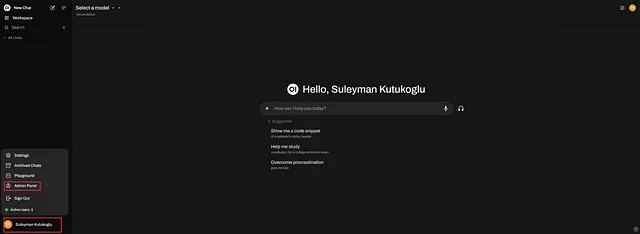
现在,让我们将Ollama连接到Open WebUI。请按照以下步骤建立Ollama连接。
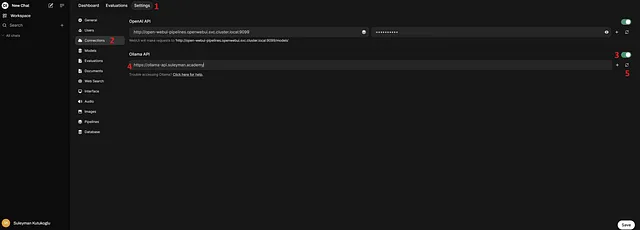
输入您的Ollama API地址(在我的情况下,是https://ollama-api.suleyman.academy)
如果您在第5步之后看到此消息,则表示Ollama连接已成功建立。

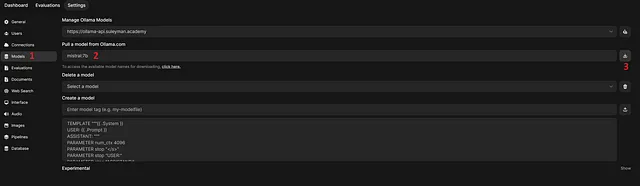
为了测试设置,让我们下载Mistral 7B模型并进行聊天测试。您可以在https://github.com/ollama/ollama 上看到其他可用的模型。
按照以下步骤在运行在Kubernetes集群上的Ollama上下载Mistral 7B模型。
成功下载模型后,请按照以下步骤进行聊天测试。
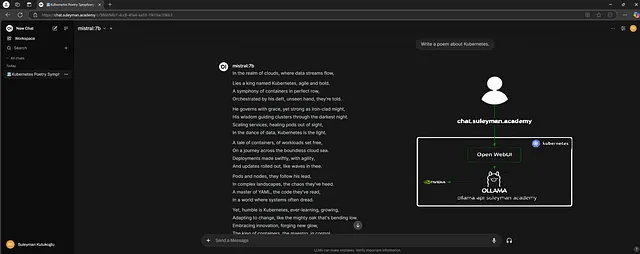
点击新聊天然后将模式切换为mistral: 7b,之后发送您的消息。
正如你所看到的,我们收到了一个成功的响应。
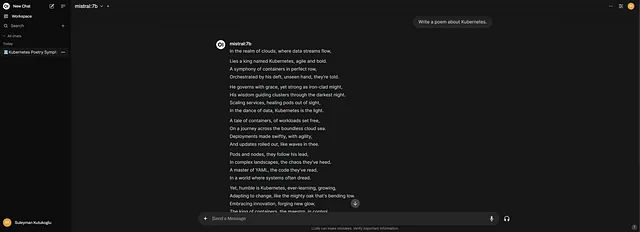
此外,下面的截图显示了对运行在Kubernetes上的Ollama POD的请求。

结论:
那就是这样了!
如果你已经按照步骤进行了操作,现在应该有一个完全运行良好的NVIDIA GPU Operator、Ollama和Open WebUI的设置。我们甚至成功地下载并测试了Mistral 7B模型。在本地运行这些模型可以让你拥有更多的控制权,保持数据私密性,并提供很大的灵活性——同时使实验变得更加容易。
希望您觉得这个指南有用,并且感到对进一步探索有信心。如果您有任何问题或见解想分享,欢迎在下方留言。
快乐实验,并在您的Kubernetes集群中享受LLMs的世界!
参考资料:
要深入了解讨论的工具并找到更多文档,请查看以下有用的链接:
- 奥拉马 GitHub 仓库:探索可用模型并获取有关奥拉马的更详细信息。
- NVIDIA GPU运算符文档:找到官方文档以帮助您更好地理解NVIDIA GPU运算符。
- 打开WebUI GitHub存储库:了解更多关于Open WebUI,并看看您如何定制或扩展其功能。