LLM仍然做得不好的是什么?
探讨当前LLM(大语言模型)的能力和缺陷
```html
大型语言模型(LLMs)革命性地改变了自然语言处理,在文本生成、翻译以及各种语言相关任务中展现出卓越的能力。这些模型,如GPT-4、BERT和T5,基于变换器架构,并在大量文本数据上进行训练,以预测序列中的下一个单词。
```Here is the translated text while keeping the HTML structure: ```html How LLMs Work? ``` ```html 大型语言模型是如何工作的? ```
LLMs 通过多层注意机制处理输入文本,使它们能够捕捉单词和短语之间的复杂关系。该过程涉及几个关键组件和步骤:
分词和嵌入
First, the input text is tokenized into smaller units, typically words or subwords. These tokens are then converted into numerical representations called embeddings. For example, the sentence “The cat sat on the mat” might be tokenised into [“The”, “cat”, “sat”, “on”, “the”, “mat”], and each token would be assigned a unique vector representation. 首先,输入文本被分解为更小的单元,通常是单词或子词。这些标记随后被转换为称为嵌入的数值表示。例如,句子“猫坐在垫子上”可以被分解为[“猫”,“坐”,“在”,“垫子”],每个标记将被分配一个独特的向量表示。
To translate "Multi-Layer Processing" to simplified Chinese while keeping the HTML structure, you can write: ```html Multi-Layer Processing ``` In simplified Chinese, it would be: ```html 多层处理 ``` So, the complete translation while maintaining the structure would be: ```html 多层处理 ```
嵌入式令牌通过多个变换层进行处理,每个层包含自注意机制和前馈神经网络。
在每一层:
- 自我关注:该模型计算所有标记对之间的注意分数,使其能够衡量不同单词之间的重要性。例如,在句子“河边的银行关门了”中,模型可能会分配更高的注意分数在“银行”和“河边”之间以理解上下文。
- 前馈网络:这些网络进一步处理注意力加权表示,使模型能够捕获更复杂的模式。
```html
上下文理解
``````html 随着输入通过这些层次,模型构建了对文本日益复杂的表示,捕捉了局部和整体的上下文。这使得大型语言模型能够理解微妙的关系,例如: ```
- 长距离依赖性(例如,跨句子理解代词的引用)
- 语义相似性和差异
- 惯用语和比喻语言
培训和模式识别
在训练期间,LLMs被暴露于大量的文本数据,使它们能够学习语言中的模式和结构。
这包括:
- 语法和句法:模型学习控制句子结构和词序的规则。
- 语义关系:它识别相关概念之间的联系(例如,“狗”和“小狗”)。
- ```html
常用短语和习语:模型学习常用表达及其含义。
```
生成相应
在生成回复时,LLM使用其学习到的模式来预测在特定上下文中最可能的下一个词或标记。这个过程是迭代的,每个生成的标记都会影响后续标记的预测。例如,如果给出“埃菲尔铁塔位于”,模型可能会生成“巴黎”,这是基于它对这些概念之间学习到的关联。通过利用这些复杂的机制,LLMs可以生成连贯和具有上下文适应性的回复,通常展现出对语言和知识的类人理解。
推理和规划的限制
```html 尽管大型语言模型(LLMs)具有令人印象深刻的能力,但它们在推理和规划等领域仍面临重大挑战。Subbarao Kambhampati及其同事的研究揭示了这些局限性,揭示了LLMs在几个关键领域难以与人类的认知能力相匹配。 ```
缺乏因果理解
```html
Kambhampati 的研究表明,LLM 在因果推理方面存在困难,而因果推理对于理解现实世界中事件和行动之间的关系是至关重要的。
```例1:天气和服装当一个人穿着大衣因为外面很冷时,LLMs可能无法推断脱掉大衣会让这个人感觉更冷。这表明他们无法理解温度和服装选择之间的因果关系。
例2:植物生长如果获得植物因缺水而死亡的信息,LLM可能不会可靠地得出结论,定期浇水可以防止植物死亡。这表明缺乏对水和植物生存之间因果关系的理解。
多步规划的困难
在多步规划方面,LLMs存在的另一个问题是不足。康帕帕蒂的研究表明,这些模型通常很难将复杂任务分解为逻辑序列的操作。
Here's the translated text while keeping the HTML structure: ```html
示例:生日派对策划
当被要求策划一个生日派对时,LLM 可能会生成相关项目或活动的列表,例如:
```- 邀请客人
- 购买装饰物
- To keep the HTML structure intact while translating the text, you can use the following: ```html 订单蛋糕 ``` If you have an entire HTML document or specific tags you'd like to include this translation in, please provide more context, and I'd be happy to assist!
- Sure! The translation of "Prepare food" in Simplified Chinese is: ```html 准备食物 ```
- Sure! Here’s the translated text while keeping the HTML structure intact: ```html 设置音乐 ```
```html 然而,这个清单缺乏有效规划所需的逻辑顺序和依赖关系。一个更复杂的计划应包括以下步骤: ```
- 设定日期和时间
- ```html 创建宾客名单 ```
- ```html 发送邀请函(至少在活动前两周) ```
- 确定派对主题
- 根据客人的喜好和饮食限制来制定菜单。
- 订购蛋糕(至少提前一周)
- 购买装饰品和派对用品
- ```html 准备或订购食物(时间取决于食物类型) ```
- ```html 在派对当天布置装饰 ```
- 安排音乐和娱乐
字符阻挡问题
Kambhampati的研究的一个主要重点是Blocksworld领域,这是一个经典的规划问题,涉及将方块堆叠和拆卸以达到所需的配置。尽管看起来很简单,但这个领域已被证明对LLMs来说是异常具有挑战性的。Kambhampati的实验表明,即使是像GPT-3这样的先进模型也很难独立生成正确的Blocksworld任务计划。在他们的研究中,Kambhampati和他的同事们测试了各种LLMs,包括不同版本的GPT,在一组600个Blocksworld实例上。结果令人震惊-即使是最有能力的模型也只能正确解决少部分问题。例如,GPT-3(Instruct)在给出自然语言提示时只能解决约12.5%的实例,而在使用更正式的PDDL(规划领域定义语言)提示时,性能甚至会进一步下降。
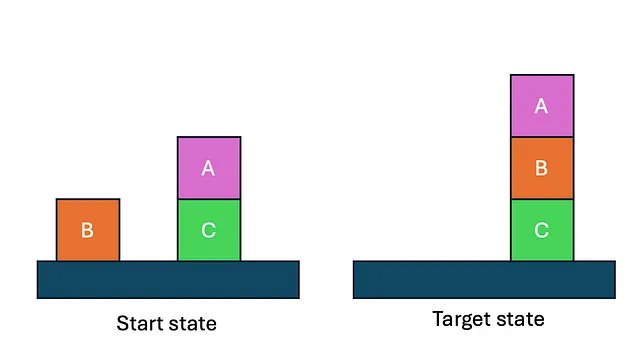
研究还探讨了微调对LLMs规划能力的影响。Kambhampati的团队在1,000个Blocksworld示例的数据集上对GPT-3进行了微调,这与他们的测试集是分开的。然而,结果令人失望-微调模型只解决了约20%的测试实例,这表明微调在提高LLMs在这个领域的规划能力方面具有有限的效果。
Kambhampati的研究表明,大型语言模型(LLMs)往往过于依赖模式匹配,而不是对规划问题进行真正的理解。这一点通过观察到在提示中更改示例计划会导致准确性显著下降来证明,即使在模型之前生成过正确计划的情况下也是如此。
- Sure, here is the translation while maintaining the HTML structure: ```html GPT-4 性能: ```
- 在标准区块世界域中使用自然语言提示:
- ```html 零样本:解决了600个实例中的210个(35%) ```
- Here's the translation while keeping the HTML structure: ```html One-shot: 解决了 206 个实例中的 600 个(34.3%) ```
2. 使用PDDL风格的提示 — PDDL风格的提示是一种使用计划领域定义语言(PDDL)语法向大型语言模型呈现规划问题的方法。这种方法不同于自然语言提示,它采用形式化的、结构化的语言来描述规划领域和问题。PDDL风格的提示通常包含两个主要组成部分:领域描述和问题描述。领域描述定义了跨特定领域中所有问题通用的断言和动作,而问题描述则指定了特定问题实例的初始状态、对象和目标状态。
- 零射击:解决了600个实例中的106个(17.7%)
- Here is the translated text while keeping the HTML structure: ```html One-shot: 解决了 600 个实例中的 75 个 (12.5%) ```
```html 3. 与其他模型的比较: ```
- GPT-4在Blocksworld领域表现明显优于先前的GPT模型。
- GPT-3.5在整个自然语言实例集中没有解决一个实例。
4. 思维链条的提示:
- 思维链触发并没有显著提高性能,与一次性自然语言提示相比。
5. 神秘的方块世界:
- ```html 当域名被混淆(改名为“神秘方块世界”)时,GPT-4的性能显著下降: ```
- ```html 自然语言提示:仅解决了600个实例中的1个 ```
```html 6. 微调结果 (GPT-3): ```
- 一个在1,000个Blocksworld实例上微调的GPT-3模型只解决了大约20%(600个中的122个)的测试实例。
这些发现突出了当前LLMs在处理需要多步推理和规划的任务中的基本限制。
时间推理
Kambhampati 的研究还指出,LLMs 在时间推理方面的困难,特别是在理解事件的顺序或时间的流逝时。
历史时间线 当被要求按时间顺序安排历史事件时,LLM可能会在排序上犯错误,特别是对于密切相关或连续发生的事件。例如,他们可能会错误地排列法国大革命的事件,或者错过第二次世界大战中关键战役的时间。
```html 反事实推理 ```
Kambhampati指出的另一个困难领域是反事实推理——考虑与已知事实相矛盾的假设场景的能力。
替代历史当被问及“如果工业革命没有发生会怎样?”时,语言模型可能会难以构建一个连贯的替代历史。他们可能会产生未能考虑到这种变化的深远影响的回应,或者可能无意中包括没有工业化就不会存在的技术或社会结构。
These limitations highlight the need for continued development in AI systems to bridge the gaps in reasoning and planning capabilities. Kambhampati’s work suggests that while LLMs excel at pattern recognition and language generation, they still lack the deeper understanding and logical reasoning abilities that humans possess. 这些局限性突显了在人工智能系统中持续发展的必要性,以弥补推理和计划能力的差距。 Kambhampati的工作表明,尽管大语言模型在模式识别和语言生成方面表现出色,但它们仍然缺乏人类所具备的更深层次的理解和逻辑推理能力。
这突出了发展混合人工智能系统的重要性,将LLM的优势与其他人工智能技术结合起来,以实现更强大的推理和规划能力。
令牌和数字错误
LLMs 在处理数字和比较时展示出奇怪的错误,特别是在处理小数和数学运算时。这些错误源于该模型的标记化过程和其缺乏真正的数字理解。让我们深入探讨这个问题:
标记化和数字表示
这些错误的根本原因在于LLM如何对数字输入进行标记化和处理。正如标记化指南中所解释的,数字经常以不一致的方式被分割成单独的标记。
例如:
- “380” 可能被分词为一个单独的令牌
- “381”可以分为两个令牌: “38”和“1”
- Here's the translation with the HTML structure preserved: ```html “3000”可能是一个令牌,而“3100”可能被拆分为“3”和“100” ```
```html
这种不一致的分词使得模型难以保持对数值的连贯理解。
```
Decimal Comparison Errors in Simplified Chinese is: 十进制比较错误
Here is the translated text while keeping the HTML structure:
```html
The example of 9.9 
Here’s why this error occurs: 这里是这个错误发生的原因:
- 该模型将“9.9”和“9.11”分开进行标记化处理。
- ```html 它可能将这些视为字符串比较,而不是数值比较。 ```
- 在字符串比较中,“9.11”确实会在字母顺序上排在“9.9”之后。
这导致了错误的断言,即 9.9 小于 9.11。
Sure! Here is the translation while keeping the HTML structure: ```html More Examples of Numerical Errors 更多数字错误的例子 ```
- 算术运算: LLM 通常在基本算术方面感到困难,尤其是在更大的数字或十进制操作方面。例如,他们可能会错误地计算 127 + 677.
- 不一致的四舍五入:当被要求对数字进行四舍五入时,LLMs可能会产生不一致的结果,尤其是对于接近四舍五入阈值的数字。
- 操作顺序:LLMs 在数学表达式中可能无法正确应用操作顺序。
- Here’s the translated text while keeping the HTML structure: ```html 大型数字比较:比较非常大的数字或具有许多小数位的数字通常会导致错误。 ```
Here is the translated text while keeping the HTML structure: ```html Research and Data 研究与数据 ```
```html
Patel等人(2021)的研究发现,尽管GPT-3具有令人印象深刻的语言能力,但在基本算术任务上却表现不佳。该模型在涉及超过三位数的计算时,其准确性显著下降。
``````html
另一篇由张等人(2022)撰写的研究论文显示,LLMs在需要精确数字推理的任务上表现不佳。他们发现,即使是最新的模型,如GPT-3和PaLM,在一个数字推理问题的数据集上也仅达到不到50%的准确率。
```含义和潜在解决方案
这些数值错误具有重要的影响,特别是在金融、工程或科学研究等需要精确计算的领域。一些正在探索的潜在解决方案包括:
- 专业化的分词:开发更一致地处理数字的分词方法。
- 混合模型:将LLM与专门的数值处理模块相结合。
- 强化培训:在培训过程中增加更多的数理推理任务。
- Here’s the translated text while keeping the HTML structure intact: ```html External Calculators: 使用外部工具进行算术运算,并将结果反馈给LLM。 ```
Understanding these limitations is crucial for developers and users of LLM-based systems. It highlights the need for careful validation of any numerical outputs and the importance of not blindly trusting LLM results for critical numerical tasks. --- 理解这些限制对于基于LLM的系统的开发者和用户至关重要。这突显了对任何数值输出进行仔细验证的必要性,以及在关键数值任务中不要盲目信任LLM结果的重要性。
幻觉和偏见
Sure! Here’s the translation of "Hallucinations" into simplified Chinese while keeping the HTML structure: ```html Hallucinations ``` Translated: ```html 幻觉 ```
```html
大型语言模型(LLMs)最显著的问题之一是它们倾向于生成虚假或无意义的信息,这被称为幻觉。这些幻觉发生在模型生成与输入数据不相关、虚构或不一致的内容时。
```偏见
```html
大型语言模型可能会不经意间延续其训练数据中存在的偏见。这可能导致生成刻板印象或偏见内容,可能促进错误信息和不公正的刻板印象。
```理解来源
```html
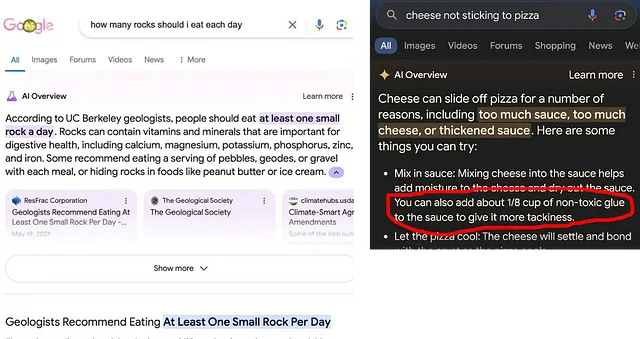
大型语言模型并不理解信息的来源,也无法区分来自诸如洋葱新闻这样的模仿文章和真实文章。如果你在模型(例如在RAG设置中)中提示它仅基于提供的文章来提供答案,并传递一些模仿文章,模型通常不会理解它们是模仿,并会使用这些文章。这就是为什么Gemini在某个时候能够回答建议人们每天吃至少一小块石头,或者应该用无毒胶水把奶酪固定在披萨上的原因。
```
其他限制
源引用LLM不能准确引用它们所提供的信息的来源。它们经常生成貌似可信但完全虚构的来源,这对需要可靠引用的任务是有问题的。
```html
数学能力
```尽管他们在语言方面很有才能,却常常在基本的数学任务上遇到困难。他们可能会给出简单计算的错误答案,突显了他们在数值推理方面的限制。
Sure! Here is the translation while keeping the HTML structure: ```html Contextual Understanding ``` In simplified Chinese, it would be: ```html 上下文理解 ```
LLMs有时无法在长篇文本中保持一致性,或者难以理解复杂的背景,导致出现矛盾或无关的回应。特别是在开发代理程序时,代理程序不能专注于根本任务,而是被计划项目分散,远离上下文。这种现象被称为“上下文漂移”,可以通过几种方式表现出来:
在LLM中一致性问题的例子
长距离依赖LLMs通常难以在较长的文本序列中保持连贯性。例如:
- ```html 在一个长篇故事写作任务中,一种大型语言模型(LLM)可能在开头引入一个名为“John”的角色,但在后面却没有解释地称呼他为“Mike”。 ```
- ```html 当总结一篇冗长的学术论文时,模型可能准确地捕捉到引言,但可能错误地表现或遗漏后面部分的关键发现(https://arxiv.org/html/2404.02060v2) ```
任务持久性代理 powered by LLMs 可能会失去他们的主要目标:
- ```html 一位虚拟助手负责规划假期,可能会先建议目的地,但随后可能会偏离主题,开始讨论当地美食,而未能完成原定行程。 ```
- 一名AI编码助手被要求优化特定功能时,可能会开始重构代码库中无关的部分,从而忽略了最初的请求(更多信息请参考https://paperswithcode.com/paper/self-consistency-of-large-language-models).
Here is the translated text while keeping the HTML structure: ```html Contextual Understanding复杂或细致的上下文可能导致不一致的反应: ```
- ```html 在关于气候变化的多轮对话中,语言模型可能最初提供科学准确的信息,但后来却通过陈述有关温室气体的错误事实而自相矛盾。 ```
- Sure! Here is the translated text while keeping the HTML structure: ```html 当分析法律文件时,模型可能会正确解释早期条款,但将这种理解错误地应用于后面更复杂的部分 (https://arxiv.org/html/2404.02060v2) ```
导致不一致的因素
注意机制局限性 Transformer 中的自我注意力机制虽然强大,但在处理非常长的序列时可能会遇到困难。
- Certainly! Here's the translation in simplified Chinese while maintaining the HTML structure: ```html As the input grows, the model’s ability to attend to relevant information from earlier in the sequence diminishes, leading to a recency bias 随着输入的增长,模型关注序列中早期相关信息的能力减弱,从而导致了近期偏见 ```
- ```html
这可能导致模型偏向于输入后面部分的信息,可能与之前的上下文相矛盾或忽略它。
```
训练数据偏见。训练在多样化数据集上的LLMs可能因为冲突信息而难以保持一致性。
- 该模型在训练过程中可能暴露于矛盾的事实或观点,导致在这些主题上查询时产生不一致的输出。
- 在具有不断发展知识或相互矛盾思想的领域中,这可能特别棘手。
缺乏真正的理解,尽管LLM具有令人印象深刻的能力,却缺乏真正的理解。
- They operate based on statistical patterns in text rather than a deep understanding of concepts and their relationships. 他们根据文本中的统计模式进行操作,而不是对概念及其关系有深入的理解。
- Sure! Here is the translation while keeping the HTML structure: ```html This limitation can lead to 逻辑不一致性或无法在长序列中维持复杂的推理链. ```
结论
总的来说,虽然LLMs在自然语言处理方面取得了重大进展,但它们在推理、规划、数值理解和保持事实准确性方面仍面临重大挑战。
保持HTML结构,翻译如下: ```html
一致性问题对开发可靠的人工智能系统提出了重大挑战:
```- 在像医疗保健或金融分析等关键应用程序中,不一致的输出可能导致严重后果。
- Certainly! Here’s the translated text while keeping the HTML structure intact: ```html 对于旨在执行复杂多步骤任务的AI代理,无法保持集中注意力和上下文严重限制了它们的有效性。 ```
```html
解决这些局限性是在人工智能领域的一个活跃研究领域。正在探索改进注意力机制、专业训练方案和外部记忆系统的发展等技术,以增强大型语言模型的长期一致性和上下文理解。正在进行的研究旨在解决这些局限性,为未来更强大和可靠的语言模型铺平道路。
```