偏差方差折衷及其如何塑造今天的LLMs
在当今的ML领域,我们发现自己被这些庞大的变压器模型如chatGPT和BERT所包围,它们为我们提供了几乎在任何下游任务上无与伦比的表现,但前提是首先需要在上游任务上进行大量的预训练。是什么让变压器需要如此多的参数,因此,需要如此多的训练数据来使它们工作?
这是我想要探讨的问题,通过探究LLM(学习至少一个语言的人)和数据科学中偏差和方差这一基石话题之间的联系。这将会很有趣!
背景
首先,我们需要回想起一些记忆,并为即将到来的事情定义一些基础工作。
变异
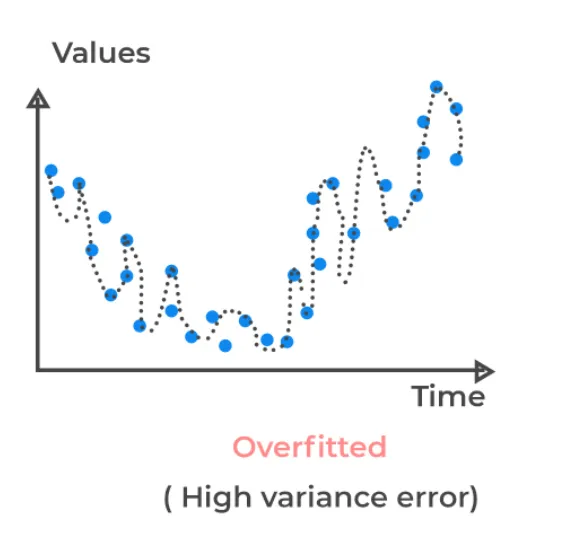
变异几乎与过度拟合在数据科学中成为同义词。该术语的核心语言选择是变化的概念。 高方差模型是指在输入变量X发生小变化时,目标变量Y的预测值变化很大的模型。
因此在高方差模型中,X的小变化会导致Y的巨大响应(这就是为什么Y通常被称为响应变量)。在下面的方差经典示例中,你可以看到这一点,只需稍微改变X,我们立即得到Y的不同值。
这在分类任务中也会表现出来,例如将“Mr Michael”分类为男性,但将“Mr Miichael”分类为女性,神经网络的输出立即产生显著的变化,只是因为添加了一个字母。
偏见
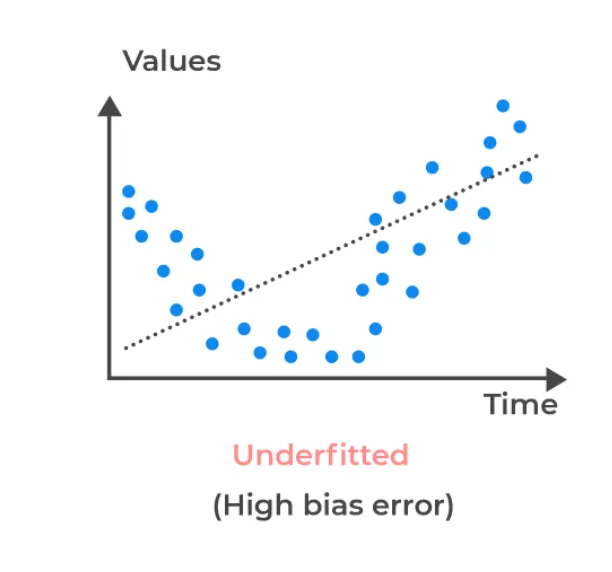
偏差与欠拟合密切相关,该术语本身的根源有助于解释为什么在这种情况下使用它。偏差通常指由于倾向于某种事物而偏离真实值,在机器学习术语中,高偏差模型是指对数据中某些特征有偏见的模型,选择忽略其余的部分,这通常是由于参数设置不足导致的,模型没有足够的复杂性准确拟合数据,因此建立了一种过度简化的观点。
在下面的图像中,您可以看到该模型并未充分考虑数据的总体模式,而是天真地拟合某些数据点或特征,并忽略了数据的抛物线特征或模式。
归纳偏好
感应偏差是对特定规则或函数的先验偏好,是偏差的一个特例。这可以来自于关于数据的先前知识,无论是使用启发式方法还是我们已经知道的自然规律。例如:如果我们想要建模放射性衰变,那么曲线需要是指数和平滑的,这是会影响我的模型及其结构的先前知识。
感知偏差并不是一件坏事,如果你对数据有先验知识,就可以用更少的数据获得更好的结果,因此参数也会更少。
一个具有高归纳偏差(即在假设上是正确的)的模型是具有更少参数但能提供完美结果的模型。
选择一个神经网络作为您的架构,就相当于选择一个明确的归纳偏见。
在类似CNNs的模型中,通过使用滤波器(特征检测器)并在图像上滑动它们,体系结构中存在隐含的偏见。这些能够检测事物如对象的滤波器,不管它们在图像的哪个位置,都是应用了先验知识,即一个对象无论在图像中的哪个位置都是相同的对象,这就是CNNs的归纳偏见。
正式来说,这被称为平移独立的假设,即在图像的一个部分使用的特征检测器,在检测图像的其他部分相同特征可能是有用的。您可以立即看到这个假设如何为我们节省参数,我们使用相同的滤波器,但是在图像周围滑动它,而不是在图像的不同角落可能使用不同的滤波器来检测相同的特征。
卷积神经网络中内在的归纳偏差之一,是假设在图像的小区域中查找特征就已经足够了,一个单独的特征检测器无需覆盖整个图像,而只需覆盖其中的一小部分,你也可以看到这种假设如何加快了卷积神经网络的速度并节省了大量参数。下面的图片展示了这些特征检测器如何在图像上滑动。
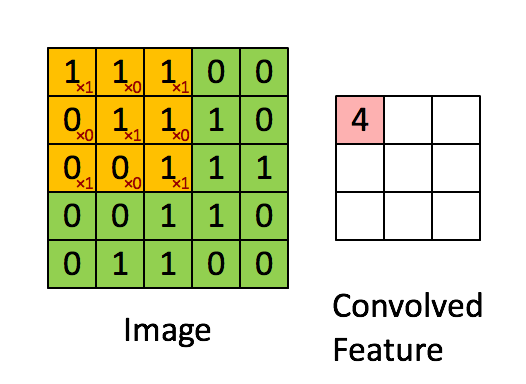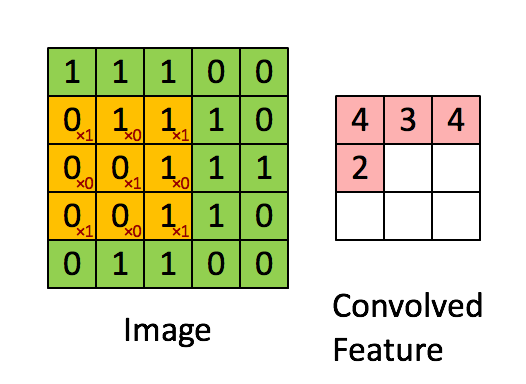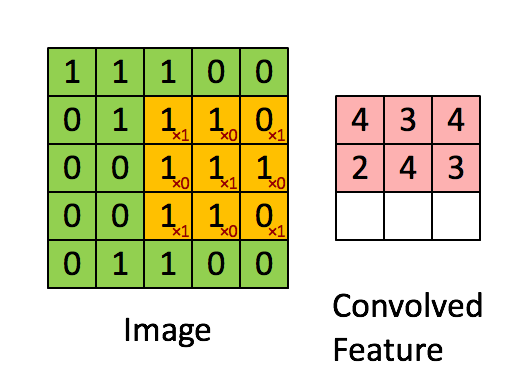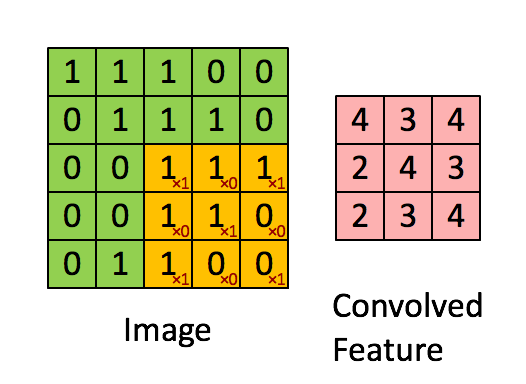
这些假设来自我们对图像和计算机图形的了解。从理论上讲,密集的前馈网络可以学习相同的特征,但它需要更多的数据、时间和计算资源。我们还需要希望密集网络为我们做出这些假设,假设它正在正确地学习。
对于循环神经网络(RNNs)而言,理论大致相同,隐含的假设是数据以时间序列的形式相互链接,在某个方向上流动(从左到右或从右到左)。他们的门控机制以及处理序列的方式使得它们更偏向短期记忆(这是RNNs的主要缺点之一)。
变压器及其低感应偏置
希望在我们已经建立起来的深入背景之后,我们能立即看到变压器与众不同的地方,它们对数据的假设几乎没有(也许这就是为什么它们对许多类型的任务如此有用)。
变压器架构对序列没有显著的假设。 也就是说,变压器擅长随时关注输入的各个部分。 这种灵活性来自自注意力,使其能够并行处理序列的所有部分并捕获整个输入的依赖关系。 这种架构选择使得变压器在不考虑地域性或时序依赖关系的情况下有效地跨任务泛化。
因此,我们可以立即看到这里没有像CNN那样的局部性假设,也没有像RNN那样的简单短期记忆偏差。这就是赋予Transformer所有威力的原因,它们具有较低的归纳偏差,并且不对数据做任何假设,因此它们学习和泛化的能力很强,没有任何假设会妨碍Transformer在相关领域深刻理解数据。
这里的缺点显而易见,变压器很庞大,拥有难以想象的参数数量,部分原因是缺乏假设和归纳偏见,直接暗示也需要大量的数据进行训练,在训练期间,它们可以完美地学习输入数据的分布(由于低偏差导致高方差,存在过拟合的倾向)。这就是为什么一些LLMs看起来好像只是在训练期间看到的东西在叨叨。图像清楚地展示了自我注意力的一个例子,以及完成这项任务所需的大量权重和维度。
变压器真的是人工智能的最终边界吗?还是有更聪明、更好的解决方案,具有更高的感应偏差,只等待被探索?这是一个开放式问题,没有直接答案。也许存在隐含的需要低感应偏差,才能拥有擅长多种任务的通用人工智能,或者也许有一条捷径可以沿途采取,不影响模型泛化能力如何。
我会把这个留给你作为读者自己的思考。
结论
在本文中,我们从头开始探讨了偏见理论,说明了transformer作为一种架构是一种可以对数据进行非常少假设和处理的工具,并且这就是使其优于卷积神经网络和循环神经网络的原因,但也是其最大缺点的原因,即尺寸和复杂性。希望本文能以新的视角揭示机器学习中的深层主题。