BERT- 一场对 NLP 的革命

介绍
语言一直是计算机难于理解的,其中一个主要原因是需要一个更基本的语境。每个自然语言处理任务都可以通过为每个任务创建的单独模型来解决。
在2018年,谷歌发布了一份名为《BERT: 深度双向Transformer的预训练用于语言理解》的论文,其目的是预先训练一个模型,以便通过添加层来轻松进行微调,从而创建一种用于各种任务(如问题回答和语言推理)的最新模型,而无需进行实质性的任务特定架构修改。
在这篇文章中,我们将看到彻底改变自然语言处理领域模型的模型,并了解它的工作原理。
BERT是什么?
BERT是一个开源的机器学习框架,用于更好地理解自然语言。 BERT代表来自变压器的双向编码表示;正如其名称所示,BERT基于变压器架构,其使用编码器表示来学习令牌在训练阶段的左侧和右侧的上下文/信息。这就是为什么它被称为双向或单向的原因。
让我们通过一个例子来看看,双向性如何帮助理解语言的含义:
正如我们在上面的例子中所看到的,词语“bank”在两个句子中有不同的含义。因此,如果模型不考虑双方的上下文,它将在至少一个句子中犯错误。
为什么我们需要BERT?
直到BERT出现之前,模型的一个主要局限性是它们是单向的,这限制了在预训练期间可以使用的架构选择。
例如,其中一个著名模型GPT使用从左到右的架构,其中每个标记都可以访问前一个标记。
BERT 是如何工作的?
为了更好地了解BERT的工作原理,我们将看到以下内容:
- 模型架构 - 在这里,我们将看到BERT的架构,这是一个Transformer
- 文本预处理/嵌入 - 它解释了BERT如何以单词为输入并将其转换为向量。
- 训练 — BERT 通过两阶段过程进行训练: 预训练和微调。
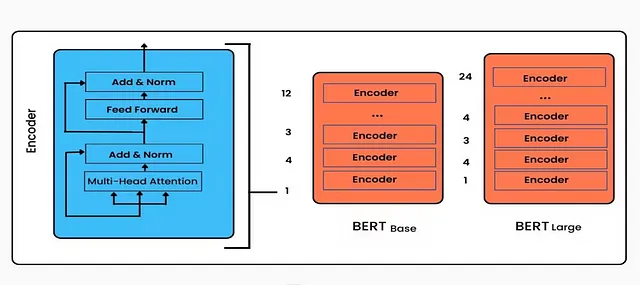
模型体系结构
BERT架构建立在transformer的基础上。BERT模型中所有的transformer块都是仅编码器。在最初版本中,有两个变体:
- BERT基本型:12层(transformer块),12个注意力头,110M参数
- BERT Large:24 层(transformer 块),16 注意力头和 340M 参数
嵌入
我们无法向模型提供单词,我们首先将单词转换为向量,这个过程称为嵌入。在BERT中,有三种类型的嵌入,用于将单词转换为数值表示向量,如下所述:
- 位置嵌入:就像BERT或transformer中一样,我们不按顺序传递数据,因此我们使用位置嵌入来表示序列中每个标记的位置。这与我们在transformer论文中看到的情况相同。
- 段落嵌入:由于BERT也将句对作为输入进行各种任务,因此对每个标记添加了段落嵌入,表示它是属于句子A还是句子B。这使得编码器能够区分句子之间的差异。
- Token Embedding: 一个[CLS] token被添加到第一个句子的输入单词tokens的开头,一个[SEP] token 被插入到每个token的末尾。
对于给定的令牌,它的输入表示是通过将相应的位置嵌入、段落嵌入和令牌嵌入相加而构建的。
培训:
BERT是通过两阶段过程进行训练的: 预训练和微调。 预训练包括使用MLM和NSP目标在大型未标记文本数据语料库上进行训练,使BERT学习上下文化的词表示。
通过微调将预训练的BERT模型适应于特定的下游任务,使用任务特定的标记数据,优化任务特定的损失函数。这种预训练和微调的组合使BERT在理解和解决各种自然语言处理问题方面表现出色。
预训练:
在训练语言模型时,一个挑战是确定预测目标。许多模型预测序列中的下一个词(例如,“The child came home from ___”),这是一种有方向性的方法,自然地限制了上下文学习。为了克服这一挑战,BERT 使用了两种训练策略:MaskedLM(MLM)和Next Sentence Prediction(NSP)。
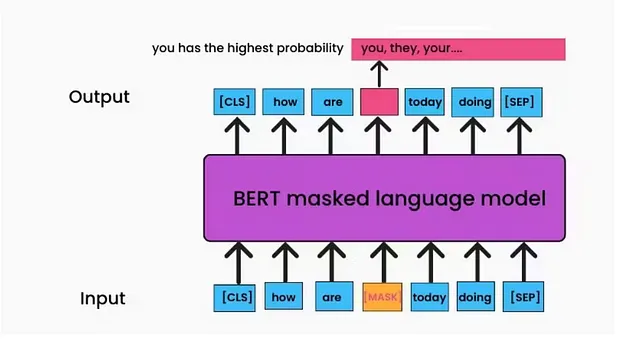
遮罩语言模型(MLM)
这是一种无监督的训练模型的技术,MLM会用[MASK]标记替换输入令牌的一定比例,然后模型尝试根据序列中单词提供的上下文来预测被标记的令牌的原始值,如下图所示。
在多层次营销中最重要的收获:
- BERT损失函数只考虑对被屏蔽数值的预测,而忽视未被屏蔽的单词。
- 由于MLM仅对每个批次中的15%令牌进行预测,与标准语言模型训练相比,它需要更多的预训练步骤才能收敛。
- 在从编码器得到输出后,它会通过嵌入矩阵进行乘法操作,将其转换为词汇维度,并使用Softmax计算每个单词的概率。
- 在这篇论文中,作者80%的时间用[MASK]替换单词。在10%的情况下,单词被随机替换,另外10%的情况下,原单词保持不变。这种方法确保编码器无法确定需要预测哪个单词模型,或哪些已被随机替换。因此,每个令牌的分布上下文表示被保持。
下一个句子预测(NSP)
在MLM期间,句子之间的关系在诸如问题回答等任务中也起着重要作用,因此我们使用NSP来训练一个能理解这种关系的模型。
在训练阶段,我们选择一对句子作为输入,并学习预测这对句子中的第二个句子是否是原始文档中的后续句子。
在训练期间,我们选择输入数据,使得50%的输入是原始文档中标记为“isNext”的一对句子,另外50%是来自语料库的随机句子,标记为“Not Next”。这将转化为一个有2个标签的分类问题。
我们只是计算输入序列,它经过基于transformer的模型,并且[CLS]标记的输出通过一个简单的分类层转换成一个2*1的向量,并使用Softmax分配一个标签。
模型同时训练了MLM和NSP,以最小化来自两种策略的组合损失函数。
精调:
在预训练之后,BERT 使用标记数据对特定任务进行微调。
在微调训练中,大多数超参数与BERT训练中保持一致。
微调的目标是通过调整其参数以更好地适应数据来优化BERT模型在特定任务上的表现。例如,对于在大型文本语料库上预训练的BERT模型,可以在较小的电影评论数据集上进行微调,以提高其准确预测给定评论情感的能力。
结论:
通过实现双向训练,BERT已经改变了自然语言处理,并使模型能够理解单词在完整语境中的含义。基于Transformer架构的BERT在各种自然语言处理任务中表现优于先前的单向模型。它提高了自然语言处理性能的水平,因为可以在大型数据集上进行预训练,并在不需要进行重大架构更改的情况下调整为特定工作。由于其适应性和效率,BERT已成为一个改变计算机理解和处理人类语言方式的基础模型。