使用FAISS,LangChain和Streamlit创建具有检索增强生成(RAG)的人工智能聊天机器人。

在当今由人工智能驱动的世界中,一种令人兴奋的应用是聊天机器人,它能够根据上传的PDF文档内容回答问题。这种类型的聊天机器人可以应用于各种行业 - 法律、教育和商业 - 其中从大型文档中快速检索信息至关重要。
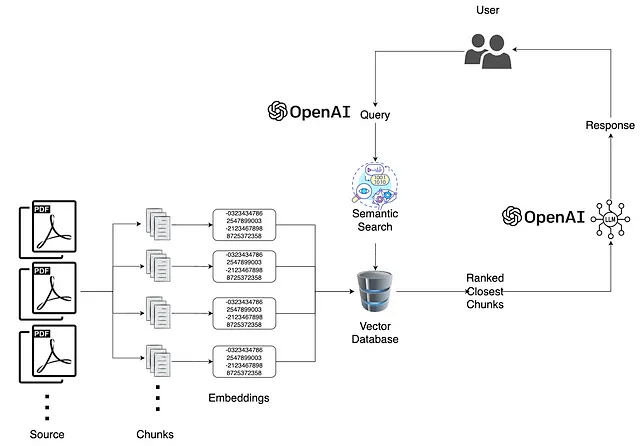
在这篇文章中,我们将介绍如何使用FAISS进行高效搜索、LangChain进行嵌入和语言模型交互、Streamlit进行交互界面开发,以及PyPDF2进行PDF处理,创建一个问答聊天机器人。该聊天机器人将允许用户上传PDF文档,询问其内容,并获取准确的答案。
建筑
重要的图书馆和技术
- FAISS: Facebook的AI相似性搜索(FAISS)是一个专为高效相似性搜索和密集向量聚类而设计的库,非常适合大规模搜索任务。
- LangChain:一个用于构建以语言模型驱动的应用程序的开源库,LangChain简化了对嵌入、链和与语言模型交互的处理。
- Streamlit:一個開源的Python庫,讓你能夠快速構建交互式的 Web應用程序。
- PyPDF2:一个用于从PDF文件中提取文本的Python库。
先决条件
在我们深入代码之前,请确保您已经安装了以下库:
pip install PyPDF2 streamlit langchain faiss-cpu langchain_openai python-dotenv
我们还需要一个OpenAI API密钥来生成嵌入并执行文本处理,我们将通过存储在.env文件中来保持安全。
步骤1:设置项目文件
- 创建一个 .env 文件:这个文件将安全地存储 OpenAI API 密钥,我们将在代码中加载它而不会在版本控制中暴露它。 OPENAI_API_KEY=your_openai_api_key不要忘记将 .env 添加到你的 .gitignore 文件中,以避免将敏感信息提交到你的存储库。
- 创建主要的Python文件:我们将其命名为pdf_chatbot.py,并在这里编写我们的代码。
第二步:代码漫游
这里是带有说明的完整代码:
import os
import PyPDF2
import streamlit as st
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains.question_answering import load_qa_chain
from langchain_community.chat_models import ChatOpenAI
# Load environment variables from .env file
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
# Path to save/load FAISS index
FAISS_INDEX_PATH = "faiss_index"
# Initialize embeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large", api_key=OPENAI_API_KEY)
# Initialize Streamlit app
st.header("Retrieval-Augmented Generation (RAG) based AI-Powered PDF Question-Answering Chatbot")
with st.sidebar:
st.title("Your Documents")
file = st.file_uploader("Upload a PDF file and start asking questions", type="pdf")
# Function to extract text from PDF
def extract_text_from_pdf(file):
reader = PyPDF2.PdfReader(file)
text = ""
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text += page.extract_text()
return text
# Check if FAISS index exists
vector_store = None
if os.path.exists(FAISS_INDEX_PATH):
# Load the existing FAISS index
vector_store = FAISS.load_local(FAISS_INDEX_PATH, embeddings, allow_dangerous_deserialization=True)
st.write("Loaded existing FAISS index.")
# Process uploaded PDF
if file:
text = extract_text_from_pdf(file)
splitter = RecursiveCharacterTextSplitter(
separators="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = splitter.split_text(text)
st.write(chunks)
st.write(f"Total chunks created: {len(chunks)}")
# Create new FAISS index if not already loaded
if vector_store is None:
vector_store = FAISS.from_texts(chunks, embeddings)
vector_store.save_local(FAISS_INDEX_PATH)
st.write("Created and saved new FAISS index with uploaded PDF.")
# Allow question input if vector store is available
if vector_store is not None:
question = st.text_input("Ask a question")
# Perform similarity search when user asks a question
if question:
question_embedding = embeddings.embed_query(question)
match = vector_store.similarity_search_by_vector(question_embedding)
llm = ChatOpenAI(openai_api_key=OPENAI_API_KEY, temperature=0, max_tokens=1000, model="gpt-3.5-turbo")
qa_chain = load_qa_chain(llm, chain_type="stuff")
answer = qa_chain.run(input_documents=match, question=question)
st.write(answer)
else:
st.write("Please upload a PDF to create or load the FAISS index.")
代码说明
环境设置:我们从.env文件中加载OpenAI API密钥,用于生成嵌入。
上传和阅读PDF:
- 用户可以上传一个PDF文件,该文件将会通过PyPDF2进行处理以提取文本。
- 提取的文本然后使用RecursiveCharacterTextSplitter分割成可管理的块。
嵌入和FAISS索引:
- 对于新的PDF上传,使用LangChain中的OpenAIEmbeddings生成嵌入,并创建并保存FAISS索引。
- 如果FAISS索引文件已经存在,则它会被加载,这样用户即使不上传新文档也可以提问。
问题输入和搜索:
- 用户可以提出与上传的PDF相关的问题,这些问题会被转换为嵌入并与FAISS索引进行查询。
- 顶部匹配项被检索并送入语言模型进行回答,回应显示在Streamlit中。
关键特点
- 持久存储:FAISS索引被保存在本地,使得聊天机器人可以在不同的会话中检索答案。
- 安全的API密钥管理:使用dotenv,像API密钥这样的敏感信息可以得到保护。
- Streamlit界面:Streamlit的用户友好界面使非技术用户能够轻松与聊天机器人进行交互。
运行聊天机器人
运行聊天机器人,请使用:
python3 chatbot.py
streamlit run chatbot.py
这个命令将会打开一个本地的Web服务器,在这里您可以上传PDF,提问,并根据文件内容查看答案。
结论
这个由人工智能驱动的PDF问答聊天机器人展示了如何将FAISS和LangChain与Streamlit结合起来,创建一个用于信息检索的有用工具。它具有可扩展性、安全性,非常适合轻松处理大型文档,是处理大量文本数据的任何组织的宝贵资产。
通过添加支持多种文件格式、对话记忆或多文档查询等功能来进一步探索,使您的聊天机器人更加强大。
参考资料
- RAG-based Chatbot: 使用亚马逊Bedrock的5个步骤
- 请访问:https://github.com/manojknit/PDF-AnswerHub-GenAI-ChatBot