利用ChatGPT的力量找到用户需求
如何使用LLM将新闻文章分类为用户需求类别的课程
现代评估数据的方法已经改变了我们对通过观众视角查看相关内容的理解和观点。
因此,在传统方法的基础上,比如评估观众的年龄和地点,分析消费内容的更用户导向的方法是考虑用户的兴趣 - 实质上是他们的需求。这种转变现在专注于用户与相关内容互动背后的意图,我们的情况下是文章。用户需求背后的理念是使用户的兴趣不仅易于获取,而且可量化。
用户需求可按照 Smartocto 在其用户需求模型 2.0 中提出的四个类别(知道、理解、感受和行动)进行细分。
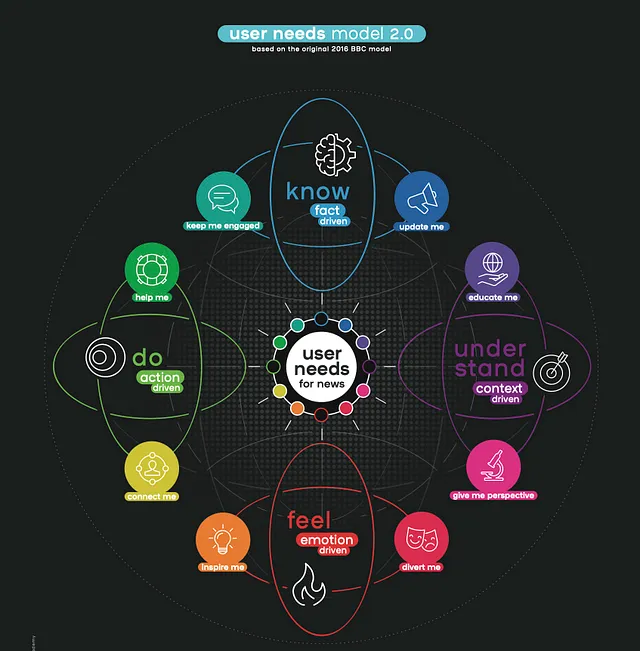
这些类别概括了用户在阅读各自文章后需要知道、理解、感受或做些什么的一般想法。
例如,关于本地新闻的文章可以满足用户对了解事情的需求,而关于光合作用的文章则与理解的需求相关。在万圣节期间阅读恐怖故事可以满足用户对感受的需求,就像关于社区活动如团体跑步或酒吧爬行的文章满足了参与需求。
重要的是要注意,界定用户需求不是一个死板的过程;事实上,根据您的受众、内容或个人评估,分类可以和应该根据需要进行调整或微调为子类别。
这种方法可以增加文章的相关性,提高观众找到有价值内容的可能性,并鼓励读者回来获取更多信息。
从技术角度来看,用户需求还为评估生成的内容与用户实际阅读内容提供了一个框架。通过考虑用户自然的兴趣,我们可以从更广泛的角度分析他们对特定文章的参与意图。这使我们能够确定可能与观众兴趣不符但产量相似的文章是否应该被重定向或重新评估。
手动分类甚至少量文章都是一项耗时任务,因此我们旨在利用大型语言模型(LLM)根据用户需求自动对文章进行分类。因此,为了实现这种自动化分类,我们利用了OpenAI的ChatGPT。这个选择是基于其作为最复杂和可靠LLM之一的声誉,也是广泛的人工智能性能研究的焦点。最终,ChatGPT本身被用来塑造当前的用户需求模型。然而,重要的是要注意,包括那些你可以自己训练的替代LLM,可能更适合满足您的需求,但它们通常需要更多的工作来实现和维护。
为了验证我们决定使用ChatGPT的决定,我们对其回答进行了测试,并将结果与我们手动分类进行了比较。最初,ChatGPT的表现超出了我们的预期,然而当我们只提示它进行一次分类,然后请求更多的分类时,我们观察到其准确性显著下降。幸运的是,我们找到了一个解决方案:在请求文章分类之前每次都启动相关提示,我们能够保持一致的表现。
为了进一步自动化这个过程,我们构建了一个定制的GPT,通过引导一个涵盖了所有相关用户需求的提示,一个明确定义的输出格式以及如何结构化数据的示例。在进行任何分类请求之前重置这个提示,我们确保输出格式保持一致,使我们能够分析数据。我们规定最多有2个用户需求,并将它们分为主要或次要用户需求进行优先排序。使用相应的API执行ChatGPT和我们文章的自动请求。
总之,我们分类过程的最终输出与我们个人的评估相吻合,确保内容与目标受众及其兴趣保持共鸣。我们的目标是不仅在文章之间实施建议,而且还要制定考虑个人用户需求及其主题兴趣的建议。
我们知道在分类过程中可能会出现不准确的情况,但我们相信这些会得到平均化,因为我们的评估支持。通过专注于用户需求,我们可以提高内容的相关性并增强未来的参与度。这种方法使我们能够提供更符合受众偏好的见解。