变压器释放: 现代AI语言模型如ChatGPT和Claude背后的突破
2017年标志着人工智能的一场革命,Vaswani及其团队在其论文“注意力机制就是一切”中引入了Transformer模型。 变压器改变了计算机理解和处理语言的方式,开启了一种使用注意力机制集中关注句子的关键部分的模型时代,而不考虑单词的位置。 让我们用简单的语言来解释这种复杂但令人着迷的技术。
什么使变形金刚与老款模型不同?
在变压器出现之前,像RNN和CNN这样的模型面临着重大挑战。它们在处理长序列时遇到困难,经常会忽略远离的句子中关键的词语关系。变压器通过一种称为自注意力的机制解决了这些问题。这种机制使模型能够检查句子中的每个单词,并理解单词之间的关系,即使它们相距很远。这一突破使得模型在处理语言任务时表现更好,无论是翻译文本还是回答问题。
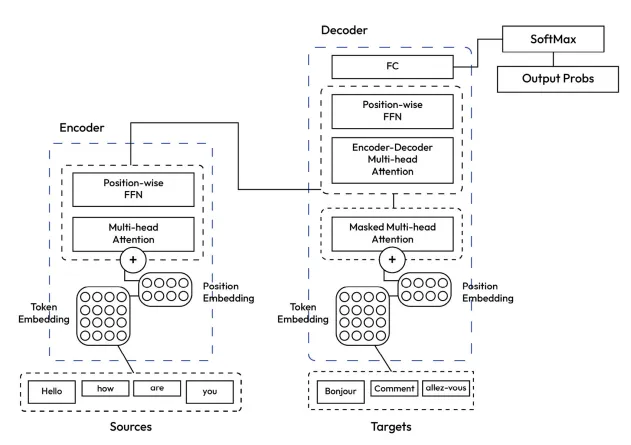
一个变压器是如何工作的?
把变压器想象成一个强大的工厂,有两个主要部门:
- 编码器:接收一个输入句子(例如,英语)并处理其含义。
- 解码器:将那个含义转换成另一种语言(例如法语)。
例如,假设您想要翻译这句话:
你好,你好吗?
变压器遵循两个关键步骤:
1. 编码器堆栈: 理解输入句子
- 标记化:将句子分解为称为标记的部分,例如“你好”,“怎么样”,“你”。
- 嵌入:每个记号被转换为一个数值表示,以捕捉其含义。例如,单词“Hello”可能被表示为 [0.25, 0.56, -0.13]。
- 自我关注 & 前馈网络(FFN):编码器查看句子中所有单词之间的关系。自我关注有助于理解词语如何在问题的背景下与“你是”这样的单词相关。
2. 解码器堆栈:生成翻译
- 解码器使用来自编码器的输出,并逐字翻译。
它以“你好”一词开始,并使用原始的英文上下文预测下一个单词,直到生成完整的翻译:“你好,你好吗?”
主要概念:位置编码
变压器不是逐字逐词地处理句子-它们一次性处理所有内容。为了跟踪正确的顺序,会添加位置编码,使每个词都能了解自己在句子中的位置。这有助于确保变压器知道“你好,你好吗?”不应该被弄乱成“你好,你好吗?”
自我注意机制
变压器的核心是自注意力。这使模型可以关注每个单词及其与其他所有单词的关系。
例如,当翻译“Hello, how are you?”时,“you”这个词从“Hello”,“how”和“are”中获取上下文。该模型分配注意力评分来决定每个词对“you”的影响程度。
为了使事情变得更好,变压器使用多头注意力,这意味着它们并行运行自我注意力多次 - 每次都集中于单词之间的不同关系,从而更好地理解句子。
前馈神经网络和SoftMax:微调和进行预测
一旦注意机制丰富了每个词的含义,前馈网络(FFN)进一步改进这些词嵌入。
在最后一步,SoftMax函数获取嵌入并将其转换为概率,以预测翻译或其他语言任务中的下一个单词。
变压器的行动:培训、掩饰和理解
- 训练数据:变压器(Transformers)通过庞大的数据集进行训练,通过大量例句翻译进行学习。
- 掩盖:在训练过程中,句子的某些部分会被隐藏,以教会模型预测缺失的信息。这有助于防止它简单地记忆模式。
- 并行处理:与旧模型不同,变压器一次处理整个句子,使其速度更快、更强大。
为什么变压器如此强大?
- 捕捉长期关系:自注意力使模型能够了解远距离词语之间的关系。
- 并行处理:与循环神经网络不同,transformers 不依赖于逐个处理单词,从而实现了令人惊叹的加速。
- 处理复杂性:拥有专注于句子关键部分的能力,转换器在翻译、总结甚至回答开放性问题等复杂任务方面表现突出。
摘要
变压器通过使语言处理模型能够理解复杂的词语关系、处理较长的语境,并生成有意义的翻译,彻底改变了语言处理。它们能够一次性处理整个句子并“关注”句子的所有部分,这使它们成为像GPT-3等最先进语言模型的基础。
想要更深入地了解变形金刚的魔力吗?发现关注机制如何改变从客户服务到内容创作的行业,并且为什么人工智能的未来取决于这一突破性技术。