GPTs如何与计算机互动?OmniParser解释
微软悄悄发布了OmniParser,这是一个开源工具,旨在将屏幕截图转换为结构化的、易于解释的元素,供视觉代理人使用。该工具的目标是推动使大型语言模型(LLMs)能够与图形用户界面(GUIs)进行交互的新兴领域。最近,Anthropic宣布了一个类似但是闭源的工具,用于与计算机界面进行交互。然而,创建一个类似的系统并不像看起来那么具有挑战性,概念很简单。微软的OmniParser在一份伴随的文件中进行了详细的文档记录,清楚、易于理解地解释了每个组件。本文将探讨如何构建一个类似于Anthropic的工具。
介绍
为了让大家了解我们试图实现的目标,想象一下,如果您在网络上需要 ChatGPT 的帮助来完成一个 UI 任务。例如,如果您想要设置一个 webhook,ChatGPT 不需要“看见”UI。它只是根据来自诸如Stack Overflow等来源的信息,提供指令,如“点击这里”或“导航到那个选项”。
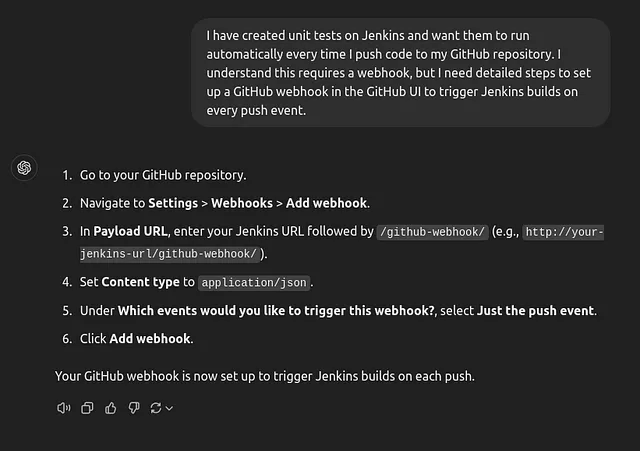
现在,我们希望再进一步。具备视觉功能的代理将能够实际看到您屏幕上的内容,理解界面,并决定下一步的步骤,比如要点击哪个按钮。为了有效地完成这项任务,它需要识别UI元素的确切坐标。
如何使用 OmniParser In OmniParser的工作原理
复杂的UI交互任务可以分解为视觉语言模型(VLMs)的两个基本要求:
- 理解当前的用户界面屏幕状态
- 预测下一个适当的行动以完成任务。
相比于在一个步骤中处理两个要求,OmniParser将这个过程分解为多个步骤。 首先,模型必须了解截图的当前状态,这意味着它必须识别截图中的对象,并预测如果点击每个对象会发生什么。 微软研究人员还使用OCR识别具有文本的可点击元素,以提供更多上下文,并对图标描述模型进行了优化。
采用这种方法,模型可以获取屏幕上不同组件的坐标信息,并理解每个组件的功能。
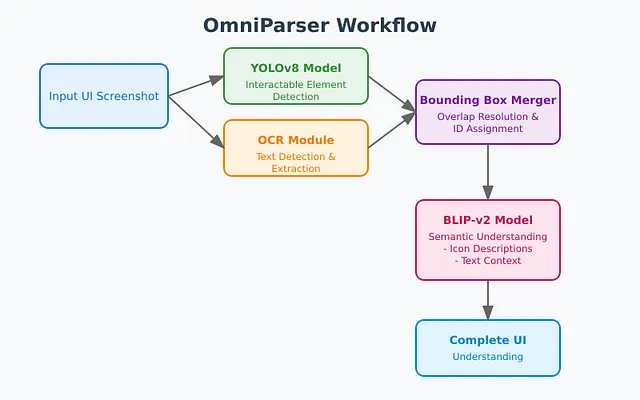
可交互元素检测
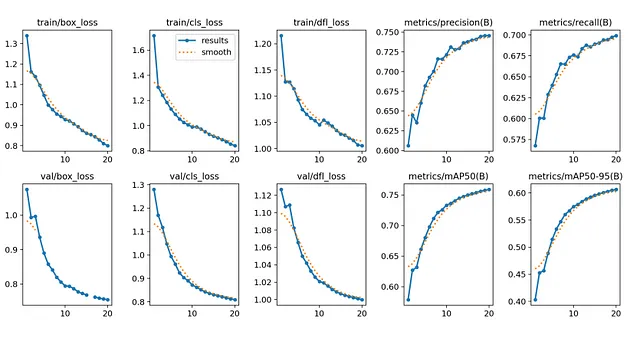
为了完成系统的第一步,微软研究人员在66990个样本上对YOLOv8模型进行了20次训练,达到了大约75%的mAP@50。除了交互区域检测,他们还开发了一个OCR模块来提取文本的边界框。然后,他们将来自OCR检测模块和图标检测模块的边界框合并起来,去除具有高重叠度的框(使用超过90%的阈值)。对于每个边界框,他们使用一个简单的算法为其标注一个唯一的ID,该算法可以最大程度地减少数字标签和其他边界框之间的重叠。
语义理解
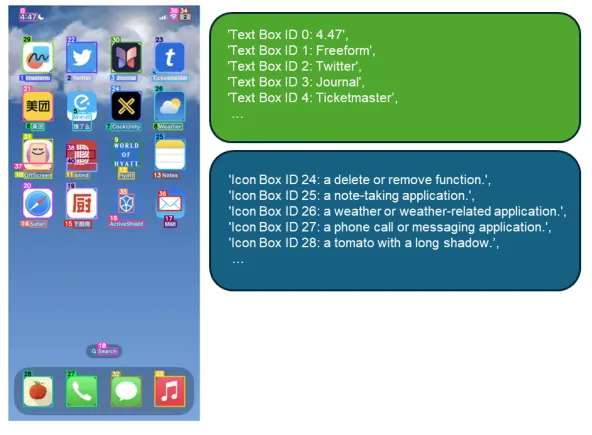
为了处理UI元素的语义理解,微软研究人员在一个包含7,000个图标-描述对的自定义数据集上对BLIP-v2模型进行了微调。这个数据集是专门使用GPT-4策划的,以确保 UI 组件的高质量,相关描述。微调后的模型以不同方式处理两种类型的元素:对于检测到的交互式图标,它生成功能描述,解释它们的目的和行为;而对于 OCR 模块识别的文本元素,则利用提取的文本内容及其相应的标签。这个语义层通过为每个 UI 元素提供明确的功能上下文,让 VLM 不再需要仅从视觉外观推测元素目的,从而为更大的系统提供支持。
系统可能以几种有趣的方式失败,突出了视觉界面交互中潜在改进的领域。让我们探讨这些限制,并讨论可能增强系统可靠性的解决方案。
具有重复元素的挑战
系统在同一页上遇到重复的UI元素时可能会出现故障。例如,当不同部分中出现多个相同的“提交”按钮时,当前实施难以有效区分这些相同元素。这会导致在用户任务需要点击这些重复元素的特定实例时,动作预测出现错误。
# Current approach
description = "Submit button"
# Improved approach could look like:
enhanced_description = {
"element_type": "Submit button",
"context": "Form section: User Details",
"position": "Primary submit in main form",
"relative_location": "Bottom right of user information section"
}
解决方案很可能在于实施“上下文指纹识别” — 给看似相同的元素添加特定于层和位置的标识符。这将使系统能够为重复元素的每个实例生成独特的描述。
在边界框检测中的粒度问题
另一个值得注意的限制涉及边界框检测的精度,特别是与文本元素有关的。光学字符识别(OCR)模块有时会生成过于宽泛的边界框,这可能导致不准确的点击预测。这在超链接和交互式文本元素中尤为棘手。
考虑这种常见情景:
[Read More About Our Services]
^
Current click point (center)
资源:
https://microsoft.github.io/OmniParser/ 微软.github.io/OmniParser/
请访问以下链接以获取更多信息:https://www.microsoft.com/en-us/research/articles/omniparser-for-pure-vision-based-gui-agent/





