探索NVIDIA的LLM Nemotron的能力-70b-指导:深入探讨基于文本的人工智能技术

英伟达,作为高性能计算的无可争议的领导者,不仅仅是在硬件方面提高标准 - 它正在重新定义AI的可能性。以提供支持当今最具挑战性的AI应用程序的GPU而闻名,英伟达现在正在将这种专业知识应用于大型语言模型,这标志着AI领域的重大进步。
了解“nvidia/llama-3.1-nemotron-70b-instruct”,这是一个设计用于需要精确性、适应性和速度关键的复杂任务的700亿参数巨头。 这款模型以NVIDIA领先的人工智能基础设施为基础构建,它不仅仅是跟上最新的LLM,还优化了体验,平衡技术实力与直观功能,适应了实际的商业和开发需求。
无论您是想增强内容创作、简化客户互动,还是优化编码工作流程,这款型号将 NVIDIA 的卓越性能带入人工智能领域,注重灵活性和可靠性。通过 “nvidia/llama-3.1-nemotron-70b-instruct”,NVIDIA 不仅在硬件方面领先,还塑造了智能、高性能人工智能的未来。
NVIDIA的“Nemotron — 70b — Instruct”:主要特点和能力
高级文本生成
"Nemotron - 70b - instruct"模型能够在各种领域提供连贯、情境准确的回答。它在以下方面表现出色:
- 对话流程:进行友好的用户对话,使其成为客户支持和问答平台的理想选择。
- 内容创作: 起草具有高度语境相关性的文章,营销内容和技术摘要。
- 代码辅助:帮助生成结构化的代码片段,进行错误分析,并能够使用多种编程语言生成伪代码。
使用精细调整的参数进行文本定制
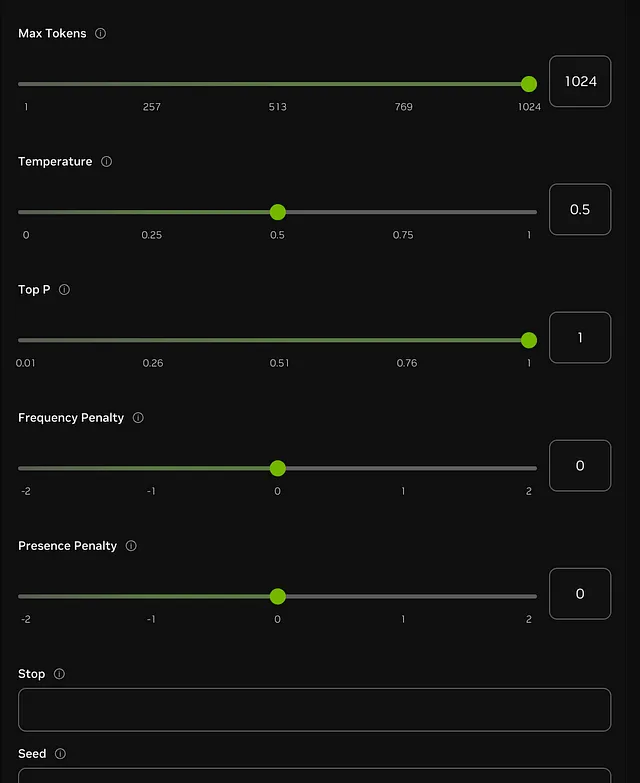
在“Nemotron-70b-指导”中真正发光的是参数控制。利用NVIDIA的API,用户可以精确地定制模型的响应,调整其输出以获得创造力、简洁或特定性。以下是可定制参数的示例:
- 最大令牌数(最多1024):控制响应长度,允许提供简洁或详细的答案。
- 温度(0-1):调整回应的创造性 — 较高的数值产生更加多样化,探索性的文本,而较低的数值则产生聚焦、确定性的回应。
- 顶部P (0.01–1):限制抽样仅针对概率最高的标记,聚焦于最有可能的下一个单词。
- 频率和存在惩罚(-2到+2):这些惩罚减少了重复的短语,并鼓励回答中的新思路。
- 停止序列:自定义停止命令可以防止生成多余的文本,当满足某些关键字时结束响应。
- 种子:此参数确保响应间的一致性,对于需要可预测结果的任务非常有用。
调整这些参数的能力使“nemotron — 70b — instruct”在各种应用中具有独特的灵活性,从创意写作到结构化的技术解释。
“nemotron - 70b - instruct” 的限制及与其他 LLMs 的比较
像所有的LLMs一样,NVIDIA的“nemotron - 70b - instruct”存在一定的局限性,特别是与具有多模式功能或实时知识更新的模型相比。以下是它的主要局限性:
- 单模态(仅文本):与多模型不同,“nemotron-70b-instruct”目前仅限于基于文本的输入和输出,这可能会限制其在视觉或音频应用中的可用性。
- 知识截断:该模型的知识库不涵盖最近的现实世界发展,可能限制其对新兴趋势或最近事件的准确性。
- 有限的低资源语言支持:主要针对高资源语言进行优化,该模型在较少人口使用的语言方面可能提供有限的熟练度。
- 对话细微差别:虽然它能很好地处理结构化对话,但与某些竞争模型如GPT-4或克劳德等相比,有些交互可能缺乏深度和流畅度。
- 与其他LLMs的比较:虽然像ChatGPT或Google的Gemini这样的模型可能会吹嘘最近的更新和多模式能力,“nemotron - 70b - instruct”被优化为一致性和深度定制。对于优先考虑结构化、参数控制文本的应用程序,NVIDIA的模型提供了精确性和灵活性的平衡,许多企业发现它是无价的。
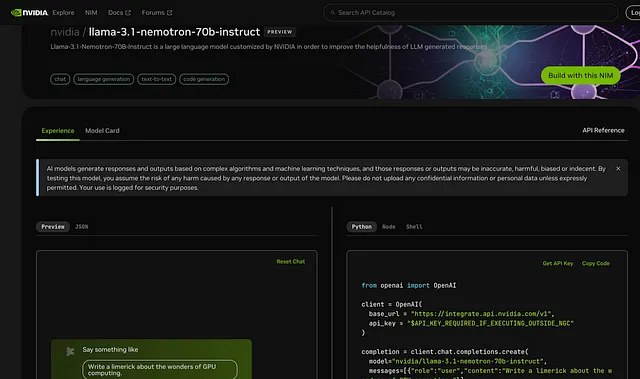
利用NVIDIA的API:示例代码和用例
英伟达的“nemotron - 70b - instruct” API已经可以商用,可供个人和专业用途访问。以下是一个可以帮助您开始使用该API的示例设置,以及用于自定义文本生成的示例代码。
使用NVIDIA API入门
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "$API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC"
)
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-70b-instruct",
messages=[{"role":"user","content":""}],
temperature=0.5,
top_p=1,
max_tokens=1024,
stream=True
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
这段代码演示了如何为实时应用配置模型的输出。这里的参数(如温度和top_p)可以根据特定需求进行调整,无论是生成创意响应还是技术摘要。
实际应用案例和好处
“Nemotron — 70b — instruct” 是一种强大的解决方案,适用于寻找多功能、高度可定制的LLM的企业和个人。以下是一些真实世界的使用案例:
1. 客户支持自动化
该模型可以模拟自然对话,回答常见客户问题,并提供详细的产品描述,使其成为服务为导向平台的宝贵资产。
2. 内容创作
从博客帖子到产品描述,这款模型的创意控制选项使其能够生成具有定向语调的多样化内容类型,确保品牌在营销渠道上的一致性。
3. 编码辅助
开发人员可以利用“nemotron - 70b - instruct”生成代码,提供调试帮助,并提供伪代码解释,使其成为技术支持和开发工作流程中的有用工具。
结论:基于文本的人工智能与英伟达的未来
英伟达的“涅莫特龙-70b-指令”设计具有灵活性、精准和用户控制平衡,非常适用于需要基于参数驱动的响应的应用程序。虽然它可能缺乏多模态功能,但其基于文本的卓越性能,结合英伟达API的详细定制选项,使其成为结构化对话人工智能需求的首选。
尝试今天的NVIDIA“nemotron - 70b - instruct”:API访问链接
随着不断发展和未来增强潜力,这个模型有望成为结构化、文本为基础的人工智能解决方案领导者。无论您是在探索对话人工智能、内容创作还是专门的商业应用,NVIDIA的模型都提供了一个可扩展且可靠的选择,专门针对高精度使用场景定制。