在大型语言模型中扩展知识
预先脚本:本帖中的技术经过同行评审并发表在一本期刊上。您可以在这里阅读预印本。
在这个系列中,我们将分解训练具有数百万参数的模型的过程 - 正好适合笔记本电脑GPU或Colab笔记本电脑。
我们的目标很明确:了解这些LLMs的行为,并探索可以塑造它们响应的调整和技巧。我们不使用庞大的预训练模型,而是专注于构建可管理的模型,让您有机会亲自了解在训练、微调或实现检索增强生成(RAG)时真正发生的事情。让我们一起揭开这个过程的神秘面纱。
问题陈述
这是我们的问题声明:
- 我们有两个不同的数据集,数据集A(小故事示例)和数据集B(食谱示例),它们之间的重叠很少。
- 目标是开发一个语言模型或者多个模型的设置,可以根据输入提示生成相关内容。
期望的结果:
- 解决方案应根据与故事相关的提示,利用数据集A中的知识生成故事。
- 解决方案应在提供与食谱相关的提示时生成食谱,并利用来自数据集B的知识。
- 根据提示生成连贯和相关的输出。输出无需原创也可以。
我们不是在寻找数十亿参数模型,而是只需要小型模型可以产生连贯的输出。灵感来源于Andrej Karpathy训练了一个拥有1.1亿参数的TinyStories LLM,因此我们认为,如果它可以产生连贯的输出,那么它可以帮助我们以一种细致的方式理解LLMs,而这是使用大型模型不可能做到的。
问题听起来似乎很简单,这也是我们了解不同模型行为的地方。我们并不是在训练生产级模型,只是在进行实验,以了解可能性以及如何解决可能的问题。
在接下来的几篇文章中,我们将回答:
- 如何准备数据来训练LLM?
- 令牌化器:如何训练一个,如何使用现有的,以及为什么错误的令牌化器会毁掉一切?
- 训练模型 - 一旦您拥有数据和分词器,训练的过程是什么样的,为什么要做出某些决定等等。我们训练多个模型而不是一个。
- 域适应——你可以如何向模型添加另一个域的知识,使其适应新的提示/输出示例。
- 经过整个序列的RAG,LoRA,完全微调,模型合并,组合,扩展。 (我会在帖子本身解释所有这些意思)。
- 结合模型训练 - 我们只需结合这两个数据集并训练一个模型。在这里,我们可以看到一个拥有22M参数的模型的输出与一个拥有220M参数的模型的输出有何不同。
- 最后,突破。看到魔术自己。
有用的链接
- 小故事数据集 — Hugging Face 由 Ronen Eldan 创建
- 食谱数据集 — Hugging Face 由Kyle Corbitt提供(在YC期间向我们提供了极大的帮助)
- Karpathy’s TinyStories LLM repo — Github and you can also see the model he trained on hugging face.
策略
我们考虑了多种方法来解决这个问题。一个简单的方法是将两个数据集合并起来,训练一个联合模型,可以根据提示生成故事和食谱。我们稍后会涵盖这一点,但从学习的角度来看,一个更有趣的维度是看看是否可以向现有模型添加更多知识。也就是说,如果我们被要求生成故事并为此训练了一个模型(或食谱),然后发现它还需要生成食谱,我们可以如何做到呢?
第一本能是通过RAG来做,但这样做是行不通的。在上下文学习和检索中,典型的RAG设置依赖于此,只有在LLM之前见过这些令牌时才有用。
那么,这让我们只剩下其他技术了 —— 完全微调、持续学习、QLoRA,或者我们可以尝试的其他一些工程技巧。
在我开始之前,现实世界的意义是什么?
正如我们在培训中学到的那样,语言模型在生成训练数据之外的任何内容时都显得很愚笨。当你的训练数据是开放网络时,这并不是一个巨大的问题,但当私人和公开可用的数据混合在一起时,就有可能出现问题 - 这是许多企业都观察到的情况。如今,许多人在努力让它运转,同时容忍相对较高的失败率,并将其归咎于RAG策略或无效的微调,而实际上,问题在于这些领域特定的数据集在模型训练期间没有被看到。
这并不意味着数据集应该逐字匹配,而是应该在训练集中存在相关概念。否则,模型将基于提供的上下文进行猜测并在预训练期间学习。
培训设置
这里是一个简单的例子。我们训练了一个大约有20M参数的小型语言模型(SLM)。GPU是Nvidia的RTX 3xxx系列。后来我们转用A10和A100(感谢Azure)因为我们需要更快的迭代速度,但在游戏笔记本上完成这项任务花了大约2天的时间。
标记器
Karpathy制作了一部4小时的视频,但这还不够。我们犯了一个错误,即仅训练故事,而将其扩展到有许多未被看到的令牌的食谱是困难的。如果解决了这个问题,我们将写两篇论文而不是一篇。也许下一个实验?
我们切换到了拥有约50,000个字词的GPT-2分词器。拥有一个好的分词器非常重要。我认为如果使用Llama-3.1的分词器,更有可能已经看过你的数据集中的所有标记。(GPT-2的分词器并没有在两个数据集中都有所有的标记)。
小故事LLM
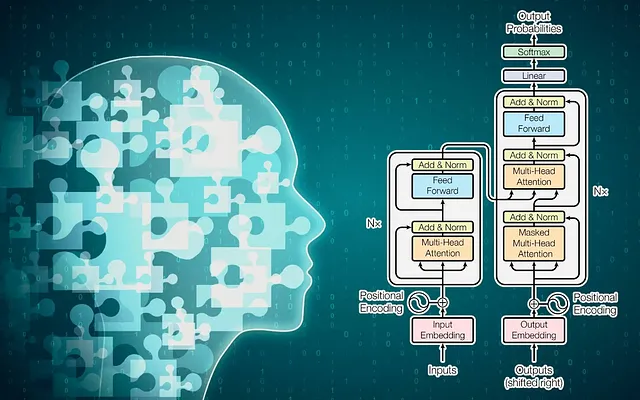
选择一种架构是一项容易的任务。你可以选择任何你喜欢的,只要确保在卡住时可以找到足够的支持材料。我们从Llama-2[3]中复制了结构。我们的结构看起来像这样:
dim = 288
n_layers = 6 # the more layers you have, the bigger the model
n_heads = 6
n_kv_heads = 6
multiple_of = 32
dropout = 0.0
max_seq_len = 350 tokens
可能是最直接的一个。我们跟着Karpathy做的,然后做了一次指令调整。基本上,将数据集换成了一个经过指令调整的数据集。
为简单起见,我们将在培训中只使用一个提示。目标是学习和理解,而不是发布一个生产级别的故事生成器。
这是我们典型的训练示例的样子:
Write a story. In the story, try to use the verb “play”, the noun “sea” and the adjective “polite”.
Possible story: Once upon a time, there was a polite crab. The crab lived in the sea. The crab had many friends. One day, the crab met a new friend. The new friend did not know how to play. The crab wanted to help the new friend. The polite crab showed the new friend how to play. They played all day. They had lots of fun. The new friend was happy. The polite crab was happy too. They were best friends forever.
这个训练数据非常基础,你也可以从中获得基础的生成结果。
这是我们训练模型的输出:
prompt = "Write a story. In the story, try to use the verb "fight", the noun "king" and the adjective "brave"."
Output:
Once upon a time, there was a brave boy named Sam. Sam lived in a small village ruled by a king.
One day, a big giant came to the village and started to cause trouble. The king asked, "Who will fight and save our village?"
Sam wanted to help, but he was young and small. His friends said, "Sam, you are brave! You can do it!"
Sam took a deep breath and went to the giant. Instead of fighting, he talked to the giant and found out he was just lonely.
Sam invited the giant to be friends with the villagers. The giant agreed, and the king was happy. Everyone cheered for brave Sam, who didn't have to fight after all.
我们最终训练的模型大约有6层和2000万个参数。当我们停止训练时,损失为0.7。
使用我们定制训练的标记器(约30,000个词)重新建模大小为15M。使用GPT-2标记器后,它增加到20M。
食谱LLM
几乎相同的设置,以及非常相似的训练数据。我们想要进行指令调整,所以相应地进行了训练。
在训练中的典型示例(调整食谱数据集)。
Write a recipe with following ingredients: 1 box powdered sugar - 8 oz. soft butter - 1 (8 oz.) peanut butter - paraffin - 12 oz. chocolate chips You can create Buckeye Candy. Directions: - Mix sugar, butter and peanut butter. - Roll into balls and place on cookie sheet. - Set in freezer for at least 30 minutes. Melt chocolate chips and paraffin in double boiler. - Using a toothpick, dip balls 3/4 of way into chocolate chip and paraffin mixture to make them look like buckeyes.
训练模型的典型输出:
Ingredients:- 2 tablespoons butter- 2 tablespoons flour - 1/4 cup boiling water - 1/4 cup vinegar- 1/3 cup brown sugar- 1/8 teaspoon ground cloves - 2½ cups diced, cooked beets
Directions: - Melt butter and stir in flour.- Gradually add boiling water and cook until thickened, stirring constantly.- Add vinegar, brown sugar, and ground cloves.- Mix well until sugar dissolves.- Add diced, cooked beets and cook until thoroughly heated.- If canned beets are used, substitute 1/4 cup liquid from the can of beets for the water.- Makes 6 servings.
You make Harvard Beets.
许多时候这仅仅是对训练数据的纯记忆和复述。如果我们更加重视并更好地注释训练数据,我们可以改进这个模型。这是另一天的任务。
在这里,有时候对于食谱,一代人就是将所有的材料一次混合在一起。我们可以接受这点。当我们停止训练时的最终损失大约为0.6-0.7。模型的结构仍然保持不变,大小也是一样的。
我们可以直观地区分出两个模型的输出,毫不费力。这一清晰可辨的特点是我们实验的关键,因为当我们混合数据集并使用微调或任何其他方法时,我们可以轻松看到输出并确定该数据集来自哪里。
您可以通过更多地处理训练数据和指示集,使训练示例更连贯,从而获得高质量的输出。
现在,到了实验部分:
在 TinyStories LM 上的 LoRA with Recipes 数据集
它没有给我们任何结果。这个模型忽略了故事,但也没有生成食谱。
我们的起始假设是LoRA无法为模型增加任何新的知识,而事实证明在这里是正确的。它还忘记生成故事的另一个方面也让人惊讶,但这是有道理的,因为LoRA改变了输出模式,但没有改变核心权重。当它在学习一个与其训练内容不同的提示模式时,它应该生成垃圾,然后具有完全不同数据集的嵌入。
损失从7点开始,并迅速下降。它从未低于2.3,并稳定在那里。
事实上,LORA/QLoRA并不改变模型的核心权重,只对顶层进行更改,因此这与我们的理解是一致的。然而,这消除了LoRA是否能为模型添加新知识的任何困惑。另一个方面是,如果您希望模型能够生成旧模式和新模式,您必须对两者进行训练。或者也可以像苹果那样,为不同的任务使用适配器,并根据手头的任务来切换它们。
在TinyStories LM上使用配方数据集进行全面微调
全面微调会改变模型各层的权重。这基本上就是重新训练,但使用不同的超参数。(不是完全正确,但从理解的角度来说是正确的)
结果:
好的部分是,该模型开始正确生成食谱。
这是一个输出:
Ingredients: - 2/3 cup sweetened condensed milk- 2 tablespoons lemon juice- 8 ounces fruit yogurt- 6 sugar cones (the hard type)- 1/2 cup whipped cream or Cool Whip
Directions:- In a mixing bowl, combine sweetened condensed milk and lemon juice. Mix well.- Add yogurt and mix thoroughly.- Spoon the mixture into sugar cones.- Set the cones upright in glasses or jars and place them in the freezer.- Freeze for 3 hours.- Top each cone with 1 tablespoon of whipped topping. You make Frosty Pudding Cones.
坏处是它再也无法生成故事了。:(
在我们的设置中,这个模型的最终损失大约是1.6-.17。表明比QLoRA更好,但仍远远低于原始模型。
在神经网络中有一个灾难性遗忘的概念,看起来这正是这里发生的情况。我们的模型忘记了旧的训练内容,并能够基于新获得的知识进行回答。
训练组合模型
这有点棘手,因为这两个数据集并不相等。你会无意中使模型对一种提示更有偏见。我们的结果在某种程度上展示了这种情况是如何发生的。
我们训练了两个结合模型——一个有22M个参数的模型,另一个有220M个参数的模型。令人意外的是,对于结合数据集,22M个参数的模型产生的输出要比220M个参数的模型更好[2]。当模型在某个数据集上过拟合时,就会发生这种情况。
22M综合模型的输出:
提示:写一个故事。在故事中,尝试使用动词“舞蹈”,名词“蝴蝶”和形容词“色彩缤纷”。
输出是
Once upon a time, there was a colorful butterfly who loved to dance. Every morning, she would spread her wings and dance through the garden. The other insects watched in wonder as she twirled and spun.
One day, she met a sad little caterpillar who couldn't dance. "Don't worry," said the butterfly. "Soon you will change, and we can dance together!" The caterpillar waited patiently, and when she became a butterfly too, they danced together.
菜谱:
提示:使用面粉、鸡蛋和巧克力豆制作巧克力曲奇饼的食谱。 步骤: 1. 将2杯面粉倒入一个碗中。 2. 打入2个鸡蛋。 3. 加入1杯巧克力豆。 4. 搅拌至均匀。 5. 在烤盘上放置小圆形曲奇饼,放在预热至350°F的烤箱中烤10-12分钟。 6. 取出并让其冷却后即可享用。
输出 (为了清晰格式化)
Ingredients:
- 1 cup butter, softened
- 1 cup white sugar
- 2 large eggs
- 2 1/4 cups all-purpose flour
- 1 cup chocolate chips
Directions:
- Preheat oven to 375°F.
- Cream butter and sugar until smooth.
- Beat in eggs one at a time.
- Stir in flour gradually.
- Mix in chocolate chips.
- Drop by rounded tablespoons onto ungreased baking sheets.
- Bake for 10 to 12 minutes until edges are lightly browned.
- Cool on wire racks.
Makes about 24 cookies.
相同提示的由 220M 参数组合模型输出:
Ingredients:
- Butter
- Flour
- Sugar
- Eggs
- Chocolate chips
Directions:
- Mix all ingredients together.
- Mix well.
- Bake until done.
- Makes cookies.
Note: Mix ingredients. Bake the cookies. They will be good cookies. Chocolate chip cookies are good. Everyone likes cookies.
我们确实可以从一个组合模型中获得故事和食谱的生成。
在最后,22M型号的损失为0.9。220M型号的损失为0.7。这说明损失并不能完全反映全部情况。220M型号的困惑度为2.03,而22M型号的参数模型的困惑度为2.29。
模型合并
这是一个很有前途的开始。您在两个不同模型中有两种技能,将它们结合起来,这两种技能形成一种联盟,合并后的模型擅长于这两个独立模型的技能。我们遵循了Maxim Labonne的指导,但并未成功。当要求生成食谱时,合并模型却只产生了胡言乱语。我们将故事指定为父模型。
那么,什么会起作用呢?
一个更简单的方法是训练一个分类器,然后只将食谱生成发送到那个SLM,同时将其他提示都发送到TinyStories SLM。一个更优雅的方法是训练一个交叉注意力路由器,采用基于合成的增强。这两种方法都是巧妙的方式,在大多数情况下都能起作用,只要界限清晰明确。不过缺点是你会很难同时使用两种模型来解决问题,只能一次使用其中一种。
我们做了另一件事,我们称之为“知识扩展”。这更多是工程方面的,基于理解变压器。它帮助我们实现我们的目标,即输出模型能够根据给定的提示生成故事和食谱。我将在接下来的博客帖子中详细介绍。在较高级别上,我们采用了tinystories LM,然后添加了更多层级,然后在食谱数据集上训练它,以便新知识存储在不同的块中,而不是覆盖现有权重。我们的最终损失约为0.8 ——比结合的2200万模型好,远远优于我们所做的所有微调测试。请密切关注后续发布的内容。
从扩展模型中得到的示例输出。
提示:编写一个使用意大利面、豌豆和切达奶酪的切达奶酪意面食谱。
切达奶酪意面食谱
材料:
- 意大利面
- 豌豆
- 切达奶酪
步骤:
- 先把意大利面煮熟。
- 在另一个锅里煮豌豆,直至变软。
- 把煮熟的意大利面和豌豆混合在一起。
- 在意大利面和豌豆中加入切达奶酪,搅拌直至奶酪融化。
- 食用前可以加入盐和胡椒调味。
Cheddar Pasta Toss Ingredients:
- 1 1/2 cups tri-color spiral pasta, uncooked
- 0.5 (10 ounce) package frozen green peas
- 1 (8 ounce) package cheddar cheese, cubed into small cubes
- 1/2 cup chopped celery
- 1/2 cup sliced ripe olives
- 3 green onions, green parts only, chopped
- 1/4 cup mayonnaise
- 2 tablespoons mayonnaise
- 2 tablespoons red wine vinegar
- 1 tablespoon olive oil
- 1/4 teaspoon garlic powder
- 1/4 teaspoon dried oregano
- 1 pinch salt (to taste) (optional)
- 1 pinch ground black pepper (to taste) (optional)
- 1 (4 ounce) jar pimentos
Directions:
- Cook rotini according to package directions, during the last 5-7 minutes of cooking time add peas to rotini.
- Drain pasta and peas, rinse pasta and peas in cold water, then drain again.
- Combine pasta/peas with the next five ingredients. Toss gently to combine.
- In a small bowl combine all of the mayo with the next 4 ingredients and the salt and pepper if using. Whisk together until smooth and uniform.
- Pour dressing over the pasta mixture and stir gently to combine until the pasta mixture is evenly coated.
- Cover and refrigerate at least 2 hours before serving. Overnight is best.
结论
一些免责声明:
- 一些在这里看不到的属性会在拥有上百亿参数的情况下显现出来。这里学习的不一定都是正确的,但大部分会成立。
- 您的损失可能会根据所使用的技术而有所不同。
- 我们将模型上传到 Hugging Face,他们的库倾向于以不同方式压缩权重,尤其是因为我们遵循了 Llama-2 架构。它在上传时会删除 lm_weight,其库和推理代码存在一些问题,需要花时间来解决。因此,最好根据您拥有的数据集和架构自行训练模型,然后进行比较。
我们成功地为现有模型添加了新知识,并使其达到足以产生与合并数据集可比的输出。对于许多目前正在部署Llama并寻求增强其人工智能产品的企业来说,这可能是一个改变游戏规则的举措(当你最终将其投入生产)。总体而言,我们学会了典型模型的行为、tokenizer的重要性以及数据准备的细微之处。更重要的是,我们发展了对LoRA、全面微调、模型合并、RAG等的直觉,这对其他应用也会有所帮助。
保持关注后续的帖子。
关于我:我经营一家初创公司Clio AI,我们为企业训练定制模型。我们不断尝试不同的技术,以使不同公司受益。我对科技非常感兴趣,不断尝试围绕生成式人工智能的新概念,因为这有助于提高我们的理解。
您可以通过ankit@clioapp.ai与我联系。
[1]: 这是一个模型遇到未知令牌的情况。它没有预先学习的令牌嵌入,难以生成连贯的文本。缺乏上下文理解,注意力权重计算不佳,价值向量也是如此,输出要么重复,要么是胡言乱语。另一个博文留待今后再说。
[2]: 这是出乎意料的,我们做了两次。一次是在家用GPU上,另一次是在A100上,以确保这不是因为训练不足。
[3]:这让我们花了很多时间构思,并且我们在Meta发布羊驼-3之前就开始了。