使用 SetFit 轻松实现文本分类…
究竟什么是文本分类?

文本分类就像是教计算机把书面文字分成不同的类别 - 想象一下把电子邮件整理成“垃圾邮件”或“收件箱”。Hugging Face SetFit 框架是一个工具,使这个教学过程更简单和高效。它允许我们用少量示例数据训练计算机理解和分类文本。
这意味着我们可以快速构建模型,帮助计算机理解人类语言的细微差别,即使数据有限。SetFit本质上简化了计算机学习解释和组织文本的方法,使得这项技术更易于获取和更有效。
什么是向量化?
在我们训练文本分类模型之前,让我们先了解一个关键概念,称为向量化。听起来可能很技术化,但实际上很简单。
将矢量化视为将单词翻译成数字,以便计算机能够理解它们。计算机不能像我们一样理解语言 - 它们需要数字来处理信息。
In this example, we will learn how to create a simple webpage using HTML.
- 用数字作为单词:想象每个单词被分配一个唯一的数字或一组数字,就像给街道上的每栋房子分配地址一样。这样,计算机就清楚地知道在哪里找到每个单词。
- 创建一个词语地图:想象一个地图上相似的词语彼此靠近。例如,“快乐”和“喜悦”可能会在地图上成为邻居,而“快乐”和“悲伤”则会相距较远。
- 理解关系:通过这种方式映射词语,计算机可以理解词语之间的关系。它们可以看到“国王”和“女王”是相关的,就像同一个社区中的房子一样。
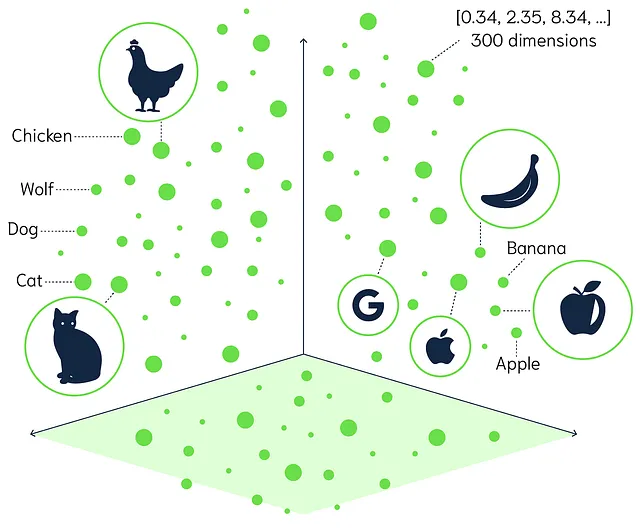
矢量化是帮助计算机“读取”文本的过程,即将单词转换成计算机可以处理的数值格式。这是文本分类中的关键步骤,让机器能够对书面信息进行整理和理解,就像我们一样,只不过是用数字来进行。
理解这个概念可以让我们了解到像搜索引擎、语音助手和垃圾邮件过滤器等技术是如何工作的。它们都依赖于向量化来解释和管理它们每天处理的大量文本。
什么是微调?
想象一下,您拥有一款通用设置适用于所有人的智能手机。但为了使它真正变成您自己的手机,您需要调整设置,比如设置您喜欢的语言、选择壁纸或按照您喜欢的方式安排应用程序。在机器学习中进行微调非常类似。我们采用已经学习了通用语言模式的模型,并稍微调整它,使其在我们特定的任务上表现更好。
从一个预训练的模型开始:
- 把这个当作一个已经完成通识教育的学生。他们对各种学科有广泛的知识。
介绍具体的培训数据:
- 我们提供与我们特定任务相关的示例给模型。例如,如果我们正在建立一个用于检测积极或消极电影评论的模型,我们会提供这些评论的标记示例。
调整模型 — 微调:
- 该模型使用这些例子来调整自己的理解,就像我们的学生参加专业课程成为某个特定领域的专家一样。
结果:
- 具有更高准确性执行我们特定任务的模型。
微调就像给我们的模型提供一个专注的训练课程,关注我们最关心的内容。通过从已经理解语言的模型开始,我们节省了时间和资源。然后,通过具体例子的微调,我们使其成为我们所期望任务的专家。
了解微调帮助我们欣赏现代技术如何可以快速和高效地适应各种需求,使我们与机器的互动更加流畅和有效。
什么是setfit?
现在您已经明白了什么是文本分类、向量化和微调,我们现在来到了这篇博客的主题。
SetFit(即句子转换器微调)旨在简化将预训练语言模型调整到特定文本分类任务的过程。以下是它的帮助方式:
需要更少的数据:
- 传统的微调通常需要大量标记的数据。SetFit 可以只用每个类别很少的几个例子就可以取得出色的结果,有时候甚至只有8个。在您没有太多数据的情况下,这是非常好的。
用户友好的方法:
- SetFit简化了微调过程中涉及的技术步骤。您无需是机器学习专家就可以获得良好的结果。
两步培训:
步骤1:
- 该模型通过一种叫做对比学习的技术学习并理解您特定数据的微妙之处,它能弄清楚文本片段之间的相似性或不同之处。
第二步:
- 然后它就会根据这个理解学习将文本分类到您想要的类别中。
快速结果:
- 因为它需要较少的数据并简化训练步骤,SetFit允许模型比传统方法更快地进行微调。
在标准计算机上运行:
- 您不需要强大的硬件或特殊设备。SetFit被设计为在普通电脑上高效运行。
质量结果:
- 尽管简单快速,但SetFit模型的表现仍然非常出色,通常能够与用更复杂方法训练的模型的准确性相匹配。
把SetFit想象成使用蛋糕混合料而不是从头开始烘培:
- 传统烘焙(精细调整):您收集所有的材料,精确测量每一样东西,并遵循复杂的指导。这需要耗费时间和烘焙技巧。
- 蛋糕预拌粉(SetFit): 大部分工作已经为您完成。 您只需添加一些其他成分,混合并烘烤。 您将获得美味的蛋糕而无需麻烦。
SetFit 使文本分类模型的微调变得简单。减少大型数据集的需求并简化训练过程,让您可以轻松创建强大、定制的模型。无论是对电子邮件进行排序、分析反馈还是监测内容,SetFit 都可以帮助您有效地进行微调,克服常见挑战。
了解SetFit如何简化微调,使您能够以实用和易懂的方式利用先进的人工智能技术。这就像有一个友好的向导,帮助您在机器学习的世界中导航,而不会陷入技术细节。
现在让我们来编写一些代码。 🗲
首先,让我们安装所需的库:
pip install setfit
我们将从setfit库和其他有帮助的库中导入必要的模块。
from setfit import SetFitModel, SetFitTrainer
from sklearn.metrics import accuracy_score
我们将定义我们的示例句子及其对应的标签。
# Sample sentences
sentences = [
"I absolutely loved this movie! The plot was thrilling.",
"The film was terrible and a complete waste of time.",
"An enjoyable experience with outstanding performances.",
"I didn't like the movie; it was boring and too long."
]
# Labels: 1 for Positive, 0 for Negative
labels = [1, 0, 1, 0]
我们从一个未经微调适用于我们特定任务的预训练模型开始。
# Load a pre-trained SetFit model
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
让我们在进行任何微调之前先看看模型的表现。
# Get predictions before fine-tuning
preds_before = model.predict(sentences)
print("Predictions before fine-tuning:")
for sentence, pred in zip(sentences, preds_before):
sentiment = "Positive" if pred == 1 else "Negative"
print(f"Sentence: \"{sentence}\"\nPredicted Sentiment: {sentiment}\n")
Predictions before fine-tuning:
Sentence: "I absolutely loved this movie! The plot was thrilling."
Predicted Sentiment: Negative
Sentence: "The film was terrible and a complete waste of time."
Predicted Sentiment: Positive
Sentence: "An enjoyable experience with outstanding performances."
Predicted Sentiment: Negative
Sentence: "I didn't like the movie; it was boring and too long."
Predicted Sentiment: Positive
现在,我们将使用我们的小数据集来微调模型。
# Prepare the training data
train_data = list(zip(sentences, labels))
# Initialize the trainer
trainer = SetFitTrainer(
model=model, # The pre-trained SetFit model we are fine-tuning
train_dataset=train_data, # The training data (sentences and labels) used for fine-tuning
eval_dataset=None, # Optional evaluation data to assess performance during training
loss_class="CosineSimilarityLoss", # Loss function guiding how the model learns (here, measures similarity)
metric="accuracy", # Metric to evaluate the model's performance (e.g., accuracy)
batch_size=8, # Number of samples processed before updating the model (batch size)
num_iterations=20, # How many times to iterate over the training data (more can improve results)
)
# Fine-tune the model
trainer.train()
让我们看看模型在微调后的表现。
# Get predictions after fine-tuning
preds_after = model.predict(sentences)
print("Predictions after fine-tuning:")
for sentence, pred in zip(sentences, preds_after):
sentiment = "Positive" if pred == 1 else "Negative"
print(f"Sentence: \"{sentence}\"\nPredicted Sentiment: {sentiment}\n")
Predictions after fine-tuning:
Sentence: "I absolutely loved this movie! The plot was thrilling."
Predicted Sentiment: Positive
Sentence: "The film was terrible and a complete waste of time."
Predicted Sentiment: Negative
Sentence: "An enjoyable experience with outstanding performances."
Predicted Sentiment: Positive
Sentence: "I didn't like the movie; it was boring and too long."
Predicted Sentiment: Negative
经过微调后,这个模型准确预测了情绪。
我们还可以查看模型为每个类分配的概率。
# Get probabilities before fine-tuning
probs_before = model.predict_proba(sentences)
print("Probabilities before fine-tuning:")
for sentence, prob in zip(sentences, probs_before):
print(f"Sentence: \"{sentence}\"\nProbability (Negative, Positive): {prob}\n")
# Get probabilities after fine-tuning
probs_after = model.predict_proba(sentences)
print("Probabilities after fine-tuning:")
for sentence, prob in zip(sentences, probs_after):
print(f"Sentence: \"{sentence}\"\nProbability (Negative, Positive): {prob}\n")
Probabilities before fine-tuning:
Sentence: "I absolutely loved this movie! The plot was thrilling."
Probability (Negative, Positive): [0.6, 0.4]
Sentence: "The film was terrible and a complete waste of time."
Probability (Negative, Positive): [0.4, 0.6]
...
Probabilities after fine-tuning:
Sentence: "I absolutely loved this movie! The plot was thrilling."
Probability (Negative, Positive): [0.1, 0.9]
Sentence: "The film was terrible and a complete waste of time."
Probability (Negative, Positive): [0.95, 0.05]
...
在微调之后,概率显示对于正确类别有更高的置信度。
通过用实际代码演示这个示例,我们展示了SetFit如何简化微调过程,使将预训练模型调整为特定的文本分类任务变得简单直接。
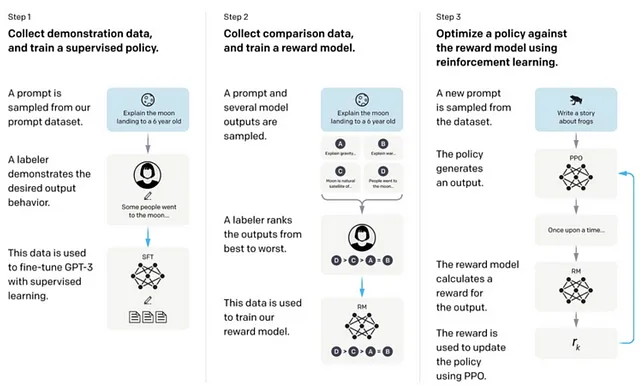
奖励、知识蒸馏,是机器学习中一种强大的技术,可以看看它如何应用于文本分类任务。
什么是知识蒸馏?
知识蒸馏就像是把智慧从教师传授给学生一样。在机器学习中:
- 老师模型:一个经过大量数据训练和学习了复杂模式的大型模型。
- 学生模型:一个更小、更简单的模型,我们希望能够训练它表现几乎与老师一样好。
目标:创建一个轻量级模型(学生),模拟一个重型模型(老师)的性能,但更高效更快速,适合部署在资源有限的设备上,如智能手机或嵌入式系统。
我们将使用Python和Hugging Face transformers库。
pip install transformers datasets torch
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from datasets import load_dataset
我们将使用IMDb电影评论数据集。
# Load the IMDb dataset
dataset = load_dataset('imdb')
# Use a subset for faster training (optional)
train_dataset = dataset['train'].shuffle(seed=42).select(range(2000))
test_dataset = dataset['test'].shuffle(seed=42).select(range(500))
我们将使用一个大型的预训练模型作为老师,比如BERT。
teacher_model_name = 'bert-base-uncased'
teacher_model = AutoModelForSequenceClassification.from_pretrained(teacher_model_name, num_labels=2)
teacher_tokenizer = AutoTokenizer.from_pretrained(teacher_model_name)
在训练数据上对教师模型进行微调。
# Tokenize the training data
def tokenize(batch):
return teacher_tokenizer(batch['text'], padding=True, truncation=True)
train_dataset = train_dataset.map(tokenize, batched=True)
train_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'label'])
# DataLoader
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_dataset, batch_size=8, shuffle=True)
# Optimizer and Scheduler
from transformers import AdamW, get_scheduler
optimizer = AdamW(teacher_model.parameters(), lr=5e-5)
num_epochs = 2
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
name='linear', optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
)
# Training Loop
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
teacher_model.to(device)
teacher_model.train()
from tqdm.auto import tqdm
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = teacher_model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
我们将为学生使用一个较小的模型,例如DistilBERT。
student_model_name = 'distilbert-base-uncased'
student_model = AutoModelForSequenceClassification.from_pretrained(student_model_name, num_labels=2)
student_tokenizer = AutoTokenizer.from_pretrained(student_model_name)
student_model.to(device)
student_model.train()
使用学生分词器对数据进行标记化处理。
# Tokenize with student tokenizer
def tokenize_student(batch):
return student_tokenizer(batch['text'], padding=True, truncation=True)
train_dataset_student = train_dataset.map(tokenize_student, batched=True)
train_dataset_student.set_format('torch', columns=['input_ids', 'attention_mask', 'label'])
train_dataloader_student = DataLoader(train_dataset_student, batch_size=8)
使用教师的输出来训练学生模型。
# Loss Function
loss_fn = torch.nn.KLDivLoss(reduction='batchmean')
# Training Loop for Distillation
temperature = 2.0
optimizer_student = AdamW(student_model.parameters(), lr=5e-5)
num_training_steps_student = num_epochs * len(train_dataloader_student)
lr_scheduler_student = get_scheduler(
name='linear', optimizer=optimizer_student, num_warmup_steps=0, num_training_steps=num_training_steps_student
)
progress_bar_student = tqdm(range(num_training_steps_student))
for epoch in range(num_epochs):
for batch_teacher, batch_student in zip(train_dataloader, train_dataloader_student):
# Move batches to device
batch_teacher = {k: v.to(device) for k, v in batch_teacher.items()}
batch_student = {k: v.to(device) for k, v in batch_student.items()}
# Get teacher's predictions
with torch.no_grad():
teacher_outputs = teacher_model(**batch_teacher)
teacher_logits = teacher_outputs.logits / temperature
teacher_probs = torch.nn.functional.softmax(teacher_logits, dim=-1)
# Get student's predictions
student_outputs = student_model(**batch_student)
student_logits = student_outputs.logits / temperature
student_log_probs = torch.nn.functional.log_softmax(student_logits, dim=-1)
# Compute distillation loss
loss = loss_fn(student_log_probs, teacher_probs) * (temperature ** 2)
# Backpropagation
loss.backward()
optimizer_student.step()
lr_scheduler_student.step()
optimizer_student.zero_grad()
progress_bar_student.update(1)
# Prepare test data
test_dataset = test_dataset.map(tokenize_student, batched=True)
test_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'label'])
test_dataloader = DataLoader(test_dataset, batch_size=8)
# Evaluation Loop
student_model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch in test_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = student_model(**batch)
predictions = torch.argmax(outputs.logits, dim=-1)
correct += (predictions == batch['label']).sum().item()
total += batch['label'].size(0)
accuracy = correct / total
print(f'Student Model Accuracy: {accuracy * 100:.2f}%')
您会得到类似于设置适合基本训练的结果,但预测时间会缩短。
结论:
我们已经穿越了文本分类的基本概念,从计算机如何通过矢量化解释文本开始。我们探讨了如何通过微调预训练模型来定制这些工具以满足我们特定的需求,而无需从头开始。SetFit框架的引入展示了一种用户友好且高效的方式,通过最少的数据微调模型,使得高级文本分类对每个人都可以访问,即使那些没有广泛的机器学习专业知识的人也可以访问。通过实际的代码示例,我们演示了SetFit如何简化过程,实现模型的快速适应,准确预测文本中的情感。
我们还深入探讨了知识蒸馏的概念,说明了它如何帮助创建较小、更快、保留了较大、更复杂模型性能的模型。这种技术对于在资源有限的设备上部署模型至关重要,确保效率而不影响准确性。通过将SetFit的简单性与知识蒸馏的高效性相结合,我们可以利用强大的人工智能技术来构建实用的现实世界应用程序。这些工具不仅使文本分类更加有效,还更易于访问,为各个行业的创新解决方案铺平了道路。