🚨 复杂表格如何击败即使是先进的企业聊天机器人
🎯 企业关键数据通常存储在表格中:价格和费率、产品规格、报告等。
🔍我们最近的比较揭示了意想不到的结果:
流行的开源解决方案通常在复杂的表格上表现糟糕。
- 流行的Llama解析器API未对齐关键数据
- 即使是Adobe的PDF Extract API(最低承诺金额为25K美元)也无法处理合并单元格
1. 第一个例子:一个具有水平合并单元格的表格.
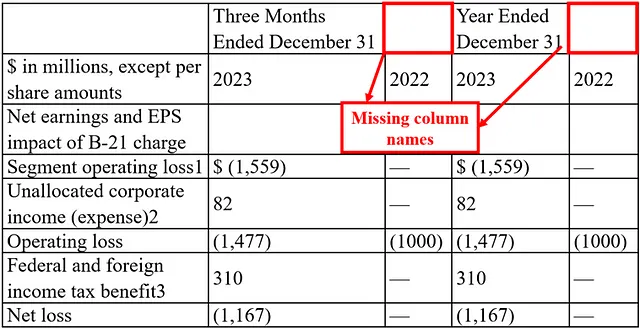
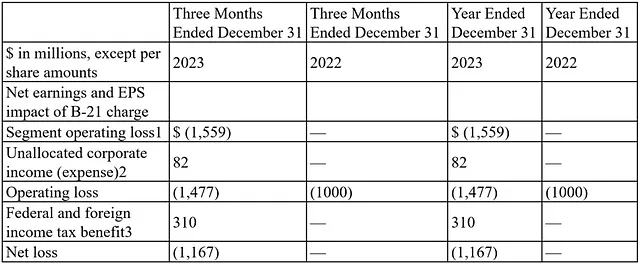
在下面的屏幕截图中(图1),第一行中的表格有两个合并的列名,分别是“截至12月31日的三个月”和“截至12月31日的一年”。

1.1. Adobe解析器
如果我们使用Adobe解析器,生成的表格将包含两个额外的空列名,应分别标记为“截至12月31日为止的三个月”和“截至12月31日为止的年度”(图2)。
1.2. 牧羊驼解析器
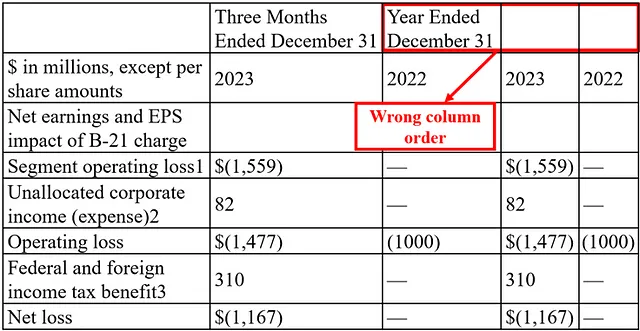
Llama解析器通过将“截至12月31日年度”列向左移动并将最后两列名称留空来搞乱了列顺序(图4)。
1.3. 自定义Varex解析器
与以前的解析器相反,我们的解析器通过复制合并单元格的列名,正确排列了列名顺序(图4):
1.4. 通过LLM响应的解析器比较

如表1所示,LLM只有在给出AssistMe解析器的输出时才能生成正确响应。对于Adobe和Llama解析器,它无法找到答案,可能是因为Adobe的输出缺少列名,Llama的列顺序错误。
2. 第二个例子:一个带有垂直合并单元格的表格。
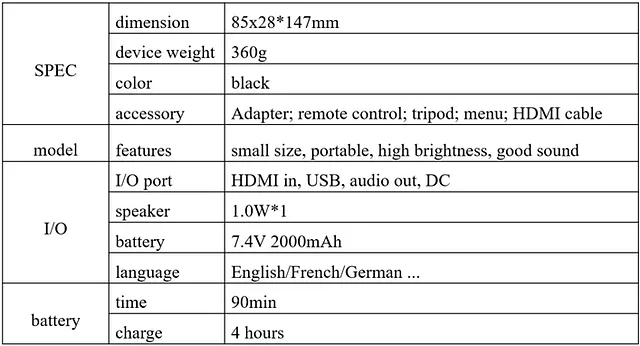
让我们来看一下表格,第一列有多个部分,每个部分描述了特定的设备特征。一些部分,比如“规格”,“I/O”和“电池”占据了多行(图5)。
2.1. Adobe分析器
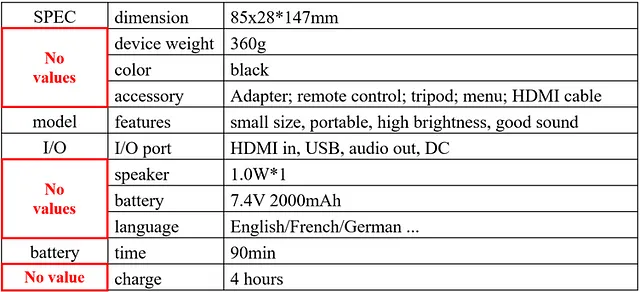
与第一个例子类似,Adobe解析器在跨越多行(单元格)的部分上遇到了困难,在第一列中留下了大量空值(图6)。
2.2. 骆驼解析器
在使用Llama解析器后,表格中包含节名称的第一列已被完全移除(图7)。

2.3. 自定义Varex解析器
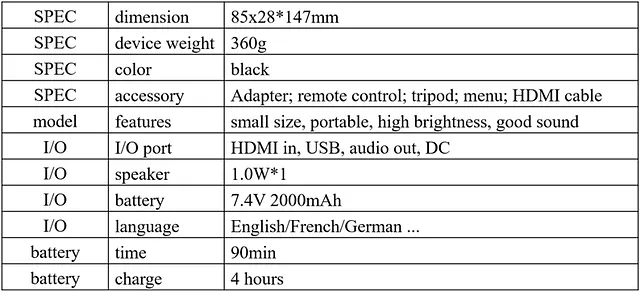
Azure 解析器通过在空单元格的位置复制章节名称来解决 Adobe 解析器的问题(图8)。
2.4. 通过LLM响应进行解析器比较
下表2比较了基于LLM(GPT-4o)响应正确性的考虑的解析器的结果,与与第2张表相关的问题有关。

正如您在表2中所看到的,第一栏中缺失的数值导致LLM在使用Adobe和Llama解析器的输出时生成了不完整的回答。相比之下,LLM在使用AssistMe解析器时产生了准确的答案,成功捕捉了所有列值。
总的来说,Adobe和Llama解析器在具有合并单元格的表格上表现不佳,因为它们未能复制数值,导致LLM应答不完整或不正确,因为缺少数值或列对齐不准确。另一方面,Varex解析器通过分割和复制数值有效地处理了合并单元格,使LLM能够生成更准确的答案。
💥 表格解析不佳的影响:
- 错误的定价/规格让客户感到沮丧
合规风险
品牌损害
- AI信任受损
您可以免费尝试Varex解析器:[https://cloud.assistme.chat/]