微软开源1位LLM: 使用BitNet b1.58在单个CPU上本地运行100B参数模型
大型语言模型(LLMs)已经改变了人工智能领域,但它们庞大的尺寸带来了同样庞大的计算成本。如果我们能够在不牺牲性能的情况下使这些模型更加高效,会怎么样?这正是研究人员通过BitNet b1.58所取得的成就,开启了1-bit LLMs时代。

在我们继续之前,如果您喜欢这个主题并且想要支持我:
- 拍我的文章十次,这会帮助我。👏
- 在Medium上关注我,获取我的最新文章 🫶
1比特LLMs的承诺
传统的LLM使用16位浮点数(FP16)来存储它们的参数,这需要大量的内存和计算资源。BitNet b1.58采取了一种激进的方法:它将每个参数减少到只有三个可能的值:-1、0或1。这种简单的改变导致了效率的显著提高,同时保持了模型准确性,从而实现了高效的操作。
- 4.1倍更快的推断速度对于70B参数模型
- 高达7.16倍的内存消耗减少
- 矩阵乘法的能耗降低了71.4倍
- 使用更大的批处理大小,吞吐量提高8.9倍
最好的部分?这些效率提升几乎没有性能方面的妥协。从3B参数开始,BitNet b1.58在各种基准测试中匹配或超过传统LLMs的准确性。
在 BitNet b1.58 中分解量化
在BitNet b1.58中,量化过程旨在将模型权重减少至三元值−1,0,1,从而在极大程度上提高计算和内存效率,而不会对准确性造成很大牺牲。以下是该过程的简要解释:
1. 量化函数
量化函数是将权值从完整精度转换为三元值的关键。它分为两个主要步骤:
A. 权重缩放:权重矩阵W按其平均绝对值进行缩放,表示为γ。这确保所有权重相对于矩阵大小进行了规范化。缩放因子γ使用以下公式计算:
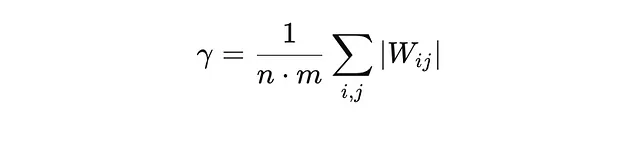
在这里,n和m是权重矩阵的维度,所有权重绝对值之和给出一个缩放因子,代表权重的平均大小。这种缩放使得权重值更加统一且更容易量化。
B. 舍入和裁剪:在缩放之后,每个重量都会被舍入到来自集合 {-1, 0, 1} 中最近的整数值。此操作使用一个名为 RoundClip 的函数执行,确保结果值被限制在这个三元集合内。
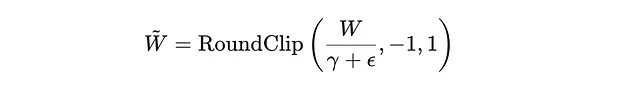
在这里,ε是为了数值稳定性而添加的一个小值。RoundClip函数将按最近的整数将比例权重四舍五入,然后确保该值在-1和1之间。
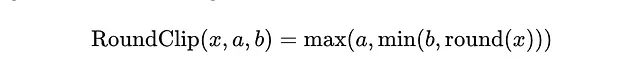
量化过程示例:
想象我们有一个权重矩阵:
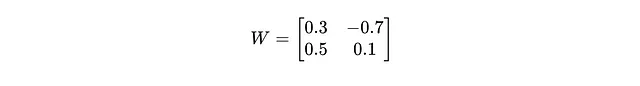
首先,我们计算缩放因子(γ):
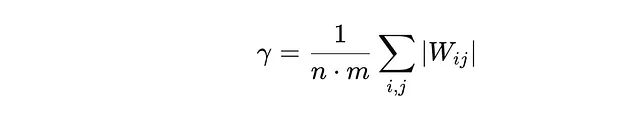
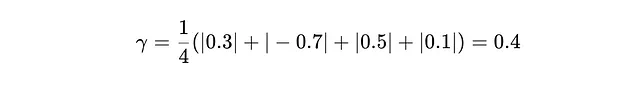
注意:绝对值(写作|x|)代表一个数字在数轴上距离零的距离,无论这个数字是正数还是负数。可以将其看作衡量一个数字距离零有多远。
例如,用|-0.7|:
- -0.7 在数轴上离零点左边0.7个单位。
- 绝对值仅仅给我们距离:0.7个单位,因此:
- |-0.7| = 0.7 (负变正)
- |0.5| = 0.5(正数仍然保持正数)
- |0.1| = 0.1 (正数保持正数)
并且:
γ = 1/4(0.3 + 0.7 + 0.5 + 0.1)
= 0.4
其次:通过γ缩放权重矩阵:
现在,我们通过将权重矩阵W的每个元素除以γ来缩放。这样可以将权重归一化。
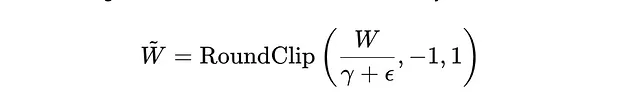
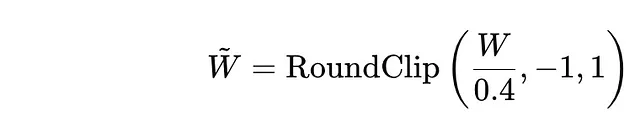

因此,缩放后的权重矩阵是:
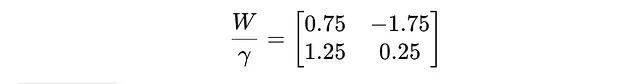
第三:我们应用RoundClip功能:
现在我们将RoundClip函数应用于缩放矩阵的每个元素。RoundClip函数的工作原理如下:
RoundClip(x,a,b)=max(a,min(b,round(x)))
- 首先,将值四舍五入到最接近的整数。
- 然后将结果夹在-1和1之间。
让我们逐个元素地查看:
- 对于0.75,四舍五入得1。由于1在范围[-1,1]之内,我们保持不变。因此,RoundClip(0.75,-1,1)=1。
- 对于−1.75,四舍五入得到−2。由于−2超出了范围[−1,1],我们将其限制在−1。因此,RoundClip(−1.75,−1,1)=−1。
- 对于1.25,四舍五入得到1。由于1在范围[-1,1]内,我们保持不变。因此,RoundClip(1.25,-1,1) = 1。
- 对于0.25,四舍五入得0。由于0在范围[−1,1]内,我们保持不变。因此,RoundClip(0.25,−1,1)=0。
最终量化矩阵:
在将RoundClip功能应用于每个元素后,量化权重矩阵如下:
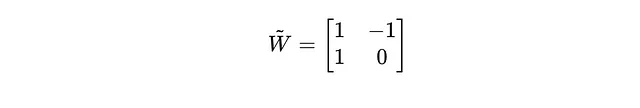
因此,矩阵:
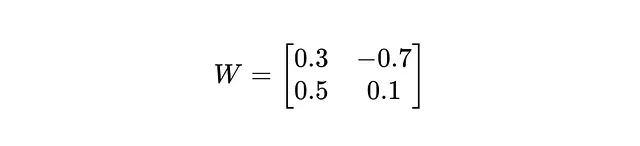
被量子化为:
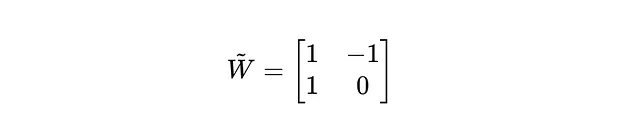
总结:
- 我们通过原始权重矩阵的平均绝对值(γ)来缩放。
- 每个元素都四舍五入到最近的整数,并截取到范围[−1,1],得到一个三元量化矩阵。
在本地运行bitnet.cpp推理框架,用于1位LLMs(例如,BitNet b1.58):
要求
python>=3.9
cmake>=3.22
clang>=18
克隆存储库:
git clone --recursive https://github.com/microsoft/BitNet.git
cd BitNet
安装依赖项
# (Recommended) Create a new conda environment
conda create -n bitnet-cpp python=3.9
conda activate bitnet-cpp
pip install -r requirements.txt
构建项目
# Download the model from Hugging Face, convert it to quantized gguf format, and build the project
python setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s
# Or you can manually download the model and run with local path
huggingface-cli download HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens
python setup_env.py -md models/Llama3-8B-1.58-100B-tokens -q i2_s
基本用法
# Run inference with the quantized model
python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?\nAnswer:" -n 6 -temp 0
# Output:
# Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?
# Answer: Mary is in the garden.
結論
BitNet b1.58 处于高效人工智能的前沿,将 1-bit 精度模型引入主流使用。通过其经过优化的内核、减少的内存占用和显著的节能,BitNet 代表了可持续人工智能部署的未来。BitNet b1.58 所打下的技术基础,从其高效的量化到动态代码生成,使其能够有效地跨越各种硬件架构进行扩展。通过降低计算成本,它为在边缘设备上运行大规模 LLM 或在能源受限环境中运行打开了大门。
合作 🤝:心里有一个有趣的人工智能项目吗?让我们携手合作吧!我愿意参与人工智能和机器学习项目,并且很乐意与其他领域的专业人士建立联系。







