LLM实用工具 - 文档查询
安东尼奥-韦拉斯科/llm_utilities (github.com)
LLM实用工具是由基于Streamlit开发的LLM(大型语言模型)支持的一组简单技术和应用程序,用于演示目的。
在本文中
- 文件查询

以前的更新
- 代理人聊天机器人
- 文本摘要生成器
未来更新
- 非结构化数据提取—(待更新和记录)
- 表格代理人 — (待更新和记录)
- 具有记忆功能的文本编写工具 —(进行中)
我开始开发其中一些作为学习练习,供我个人使用,或作为行业可以实现的演示示例。它们可以提高生活质量和/或改善日常办公任务的效率,或解决行业的不足之处和使用案例。
我的意图是整理它们并写关于每一个展示,并分享存储库作为示例。今天,对长篇文档进行索引,使LLM能够从中检索相关信息并相应地回答用户查询。
工具描述
🤔 文档查询
文档查询接受拖放PDF文件或PDF链接。它使用Azure的文档智能技术提取所有文本并分割成页面,然后使用ChromaDB进行索引。用户可以提出有关文档内容的任何问题。查询将与索引页面匹配,包含答案的页面将作为上下文被带到LLM。用户将收到答案并显示页面进行事实核实。
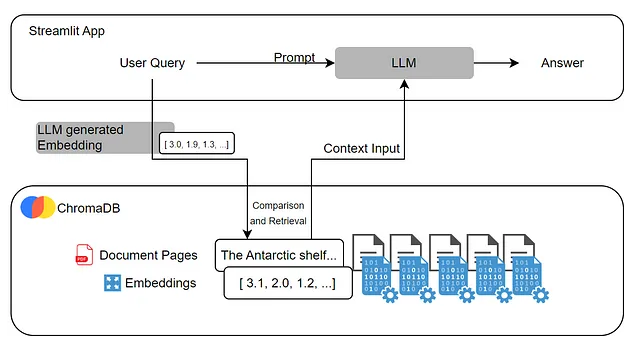
索引工作是通过使用我们的LLM为文档的每一页创建一个向量。这被称为嵌入。创建嵌入是快速和资源有效的。通过使用它们来找到相关内容,而不是将整个文档提供给LLM,我们避免了过度消耗或遇到模型的限制。
嵌入是一种将单词或文本块表示为矢量的方法,共同语境的元素会在矢量空间中靠近。这些矢量存储在ChromaDB数据库中,在提示时将与用户查询嵌入匹配,只会提取相关页面。
Chroma DB 是一个用于存储和检索向量嵌入的开源向量存储库。它的主要用途是保存嵌入以及元数据,以便稍后被大型语言模型使用。
最后,相关页面和用户查询一起发送给一个LLM,这将回答用户。这是一种检索增强生成解决方案,允许LLM轻松从给定的长文档中提取知识,并有效利用资源。
结果
该演示可以接受指向PDF文件的URL或拖放PDF或DOC文件。用户可以在框中写入查询,然后单击“询问文件”。经过一段时间的处理后,将出现一个答案,该答案已经从文件中获取了知识和信息。在下方,LLM使用的上下文页面将被显示出来。这允许对长文档进行事实检查或内容定位任务。
如何使用
在这里找到存储库:Antonio-Velasco/llm_utilities (github.com)
安装
- 在您的本地机器上Git克隆。
- 使用以下内容创建一个'.env'文件:
秘密_OPENAI_API_密钥=您的密钥在这里
秘密_表单_键=您的文件智能键在这里
秘密_表单_终点=文件_INT_终点_在这里
- 创建一个虚拟环境(pipenv文件可用),并安装在“requirements.txt”中的库。在终端中运行以下命令:
pip install -r requirements.txt 用pip install -r requirements.txt安装
- 在终端中运行以下命令(任选一个):
运行 streamlit run code/Home.py
pipenv run streamlit运行代码/首页.py
就是这样!一个类似html的应用程序将在您的浏览器中打开,在其中您可以导航到侧边的聊天工具并使用它。
未来更新
- 非结构化数据提取 —(待更新和记录)
- 代理人表 - (待更新及记录)
- 具有记忆功能的文本编辑器 — (待完成)