LLM创作的三大支柱:一本无技术要求的指南
· 预训练 ∘ 数据收集 ∘ 分词 ∘ 自监督学习 · 微调 · 通过人类反馈进行强化学习 (RLHF)
我们最近都经常使用ChatGPT, Claude和Gemini。这些都是非常有用的大型语言模型(LLMs),它们简化了我们的生活,帮助我们处理工作,教育和日常任务。但你有没有想过这些系统是如何工作的,或者是如何被创建的呢?在这篇文章中,我将用简单的方式解释LLM培训过程。到最后,你将对使这些AI模型如此强大的关键步骤有很好的理解。让我们来探索训练大型语言模型的第一支柱:预训练!
预训练
预训练是训练过程中的第一步,非常重要,也非常昂贵。这是语言模型取得关于词汇、语言以及词汇之间相互作用知识的地方。它帮助他们理解“猫”是什么意思,“帮助”意味着什么,以及为什么“水”和“海洋”这样的词是相关的。那么,预训练是如何工作的呢?以下是三个主要步骤:
- 收集大量数据
- 标记化
- 自我监督学习
数据收集
从各种来源收集了数百千兆字节的文本,如书籍、网站、新闻文章、学术论文、社交媒体等。这些数据集经过筛选和处理,去除低质量内容、噪音和任何潜在有害数据。这一步骤至关重要,因为它决定了模型将拥有的知识“范围”。如果所有训练数据都来自Reddit的回复,那么模型的质量会怎么样... 你知道的 😅
另一方面,仅仅在学术论文上训练的模型会听起来和行为更正式,提供更具学术性的回答,但可能缺乏口语流畅度。
标记化
在将数据输入模型之前,文本必须转换为称为令牌的较小单位。 令牌可以是整个单词,单词的一部分,甚至是一个单一字符,具体取决于方法。 令牌化是至关重要的,因为它有助于模型将语言分解为可管理的部分同时保留含义。
例如,单词“头疼”可能会分为两个标记:“头”和“疼”。每个部分提供宝贵的信息 — “头”与身体部位有关,“疼”与疼痛有关。这种分解有助于模型在类似语境中进行泛化。例如,如果模型遇到“胃疼”,它可以通过识别共享组件“疼”来推断含义。
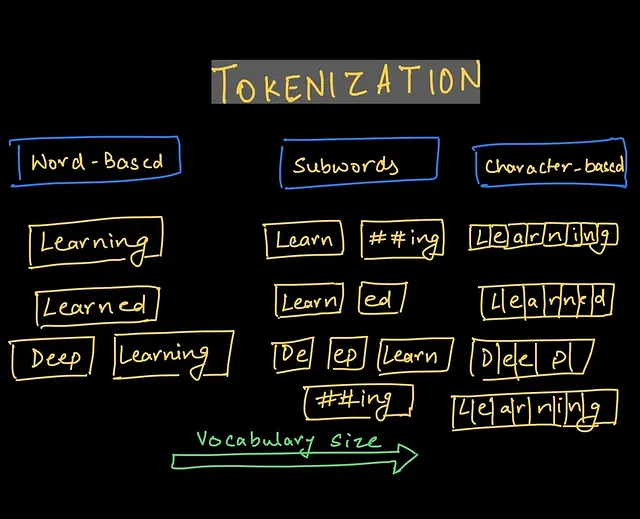
在某些情况下,标记化还可以处理更复杂的语言结构,比如分解缩略语(“didn't” 可以分解为 “did” 和 “n’t”),甚至处理具有复杂语法规则的语言(比如中文或阿拉伯文)。 标记化使模型可以以灵活、精细的方式处理文本,使其更能理解和生成连贯的回应。
自监督学习
收集和标记数据后,模型已准备好进行训练。注意:我正在跳过模型架构工程步骤,因为这更具技术性。基本上,还有另一个步骤,即定义模型:使用哪些函数,数据如何在函数之间流动,以及最终的输出是什么。
在自监督学习步骤中,文本被分割成所谓的“窗口”,窗口大小是预定义的。假设我们的完整文本是:“猫坐在地毯上享受风”。让窗口大小为4,这样会创建包含4个标记的窗口,并且我们会一次将窗口向前滑动一个标记。
- "猫坐在"
- 猫坐在一个
- 坐在垫子上。
- 在一块垫子上
- 一个垫子和
- 垫子和享受
- "并享受了风"
自我监督步骤的目标是在给定一个窗口的情况下预测句子中的下一个单词。因此,如果模型被给出短语“cat sat on a”,它需要预测单词“mat”。
原来,这种训练方法是模型学习单词含义及其相互作用的绝佳方式。此外,它还学会将不同词组进行关联(例如,它学会苹果和橙子相关联,国王和皇后相关联)。
它通过学习单词嵌入来实现这一点,单词嵌入只是一个词语的数字表示,可以绘制出来,可能看起来像这样:
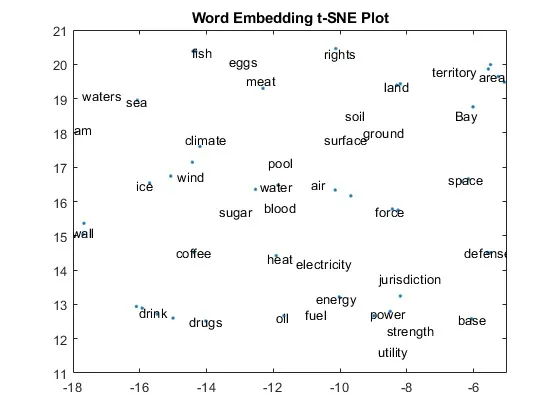
您可以看到相关词语被绘制得更接近。"水"和"海","领土"和"地区","气候","风"和"冰"。
在预训练阶段结束时,模型学会了单词的含义,它们之间的关系,并成为一个“下一个单词生成机”。它还不能回答你的问题。如果你问它一个问题,它可能只会生成类似的问题或在你的问题中添加一些单词,而不是回答它。
精细调节
为了教导模型如何回答问题,实施了微调步骤。基本上,它获取基本的预训练模型以及关于单词的所有学到的知识,并教导它执行特定的任务。
这个步骤包括收集大量的问题和答案数据,文章及其摘要,提示和书面代码或文章等。
然后,这些数据被用来将输入(提示/问题)映射到输出(对问题的人工编写答案),并且被提供给模型进行训练。在此过程中,模型学会了如何响应查询,使其成为一个工作助手。在微调之后,模型应该能够回答人类的问题并执行它接受过训练的其他任务(例如生成代码)。
从技术上讲,模型已经完成训练,可以帮助您处理您的查询。然而,还有另一个步骤可以将LLM提升到另一个水平。
根据人类反馈进行强化学习(RLHF)
RLHF或通过人类反馈进行强化学习是一个人类整合的步骤,它教导LLM生成与人类对齐的答案,使其更加有用、多样化,并且不偏向政治人物(至少他们说他们尝试让LLM这样…)。
这是通过要求模型生成同一问题的几个答案,然后使用人类排名者对每个问题进行排名,然后将数据反馈给模型进行学习,从而形成一个人类反馈循环来完成的。
在这一步中,您可以看到LLM也可以轻松地与负面目的对齐。如果偏见答案总是排名较高,模型将学会生成更多的偏见答案,反之亦然。
这三个支柱——预训练、监督微调和RLHF——共同合作,将原始文本数据转化为我们每天互动的复杂人工智能助手。每个步骤都建立在上一个之上,完善了模型的能力,并使其与人类的需求和期望保持一致。
如果你有任何问题或者对更多关于人工智能或自动化的文章有任何想法,请告诉我!
在X上关注我,获取更多人工智能和自动化内容:https://x.com/NAndriievskyi






