用Python编写的带有消息历史记录的简单LangChain聊天机器人。

该指南遵循langchain内部文档:
https://python.langchain.com/docs/how_to/message_history/ https://python.langchain.com/zh/docs/how_to/message_history/
什么是Langchain?
LangChain 就像一个工具包,帮助您构建智能聊天机器人。 想象一下,您正在与一台机器人对话。 通常,在您问问题并获得答复后,机器人会忘记一切。 但是使用 LangChain,机器人可以记得您之前说过的话,使对话更加自然,就像与记得事情的人交谈一样。
它的工作方式是通过连接不同的部件:
- 留言:您或AI说的话。
- 记忆:聊天机器人储存过去对话的地方,以便稍后能够回忆起来。
- 状态管理:这有助于聊天机器人了解对话中发生的事情并跟踪一切。
如何将消息历史记录添加到 langchain 聊天机器人?
让我们开始安装正确的库
pip install -qU langchain-openai
pip install python-dotenv
在.env文件中保存你的OPENAI_API_KEY
OPENAI_API_KEY = 'your-api-key'
现在创建一个main.py文件,并导入您的密钥,作为第一步,我们将导入正确的库并定义一个新的Llm模型。
from langchain_core.messages import HumanMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, MessagesState, StateGraph
from langchain_openai import ChatOpenAI
import os
from dotenv import load_dotenv
load_dotenv()
# Create a ChatOpenAI model
llm = ChatOpenAI(model="gpt-4o-mini", api_key=os.environ["OPENAI_API_KEY"])
LangChain 使用一种称为“状态图”的技术来管理对话的流程。在这里,我们定义了一个名为workflow的新StateGraph,它将处理用户和人工智能之间的消息。对话的状态(包括过去的消息)由MessagesState来管理。
workflow = StateGraph(state_schema=MessagesState)
这个函数,call_model,是聊天机器人的大脑。它接收对话状态(到目前为止的消息)并调用GPT模型生成回复。该函数然后返回更新的消息列表,包括来自人工智能的新回复。
def call_model(state: MessagesState):
response = llm.invoke(state["messages"])
return {"messages": response}
在这里,我们为对话定义了一个简单的流程:
- add_edge(START, “model”): 这告诉LangChain通过调用模型开始对话。
- add_node(“model”, call_model): 我们添加一个单节点,其中调用模型以生成响应。此节点使用我们之前定义的call_model函数。
workflow.add_edge(START, "model")
workflow.add_node("model", call_model)
聊天机器人使用记忆来保留过去的对话。我们添加了一个记忆组件(MemorySaver)来保存对话历史。然后,我们将工作流程编译成一个包含这个记忆的应用程序。
配置允许我们将特定设置传递到工作流程中,例如一个 thread_id,这可能对跟踪对话很有用。
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "abc123"}}
注意,如果您更改“thread_id”,聊天机器人将不会了解当前对话的任何内容。
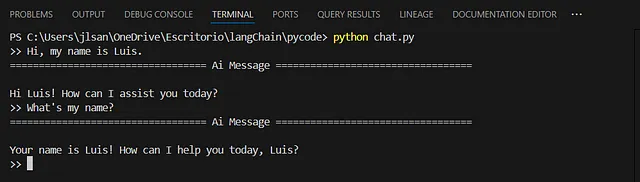
这是聊天机器人运行的主循环:
- > “): 该程序等待用户输入消息。
- HumanMessage(query):用户的消息被包装在一个HumanMessage对象中。
- app.invoke(): 应用程序(编译后的工作流程)处理用户的消息,GPT模型生成响应。
- pretty_print():用户将看到打印的最后一条消息(AI的回应)。
while True:
query = input(">> ")
input_messages = [HumanMessage(query)]
output = app.invoke({"messages": input_messages}, config)
output["messages"][-1].pretty_print()
完整代码
from langchain_core.messages import HumanMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, MessagesState, StateGraph
from langchain_openai import ChatOpenAI
import os
from dotenv import load_dotenv
load_dotenv()
# Create a ChatOpenAI model
llm = ChatOpenAI(model="gpt-4o-mini", api_key=os.environ["OPENAI_API_KEY"])
# Define a new graph
workflow = StateGraph(state_schema=MessagesState)
# Define the function that calls the model
def call_model(state: MessagesState):
response = llm.invoke(state["messages"])
# Update message history with response:
return {"messages": response}
# Define the (single) node in the graph
workflow.add_edge(START, "model")
workflow.add_node("model", call_model)
# Add memory
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "abc123"}}
while True:
query = input(">> ")
input_messages = [HumanMessage(query)]
output = app.invoke({"messages": input_messages}, config)
output["messages"][-1].pretty_print() # output contains all messages in state
工作原理
这个机器人会通过MemorySaver不断与您进行互动,并记住您说的每句话。每次新的用户输入都会被添加到记忆中,并且随着每次新的互动,状态也会更新。这个工作流程确保了流畅的对话,AI利用记忆来给出具有上下文意识的回复。
这个指南应该帮助您理解代码的关键部分以及LangChain如何构建一个智能的、具有记忆功能的聊天机器人。
https://santiago-marquez.com/ https://santiago-marquez.com/






