解锁人工智能的未来:基础模型是什么,为什么它们是游戏改变者?
索引:
- 什么是基础模型?
- 概述和关键概念。
基础模型的组成部分:
- 神经网络架构
- 数据需求
- 基础模型任务
3. 为什么我们称它们为“基础模型”?
- 术语背后的解释。
4. 基础模型的阶段:
- 预训练
- 对齐阶段
- 微调
5. 为什么基础模型很重要?
- 在人工智能中的重要性。
6. 基础模型的类型:
- 基于语言的基础模型(文本数据)
- 基于视觉的基础模型(图像数据)
- 多模基础模型(图片和文本数据)
- 特定领域基础模型(针对特定领域数据)
7. 基础模型涉及的风险:
- 偏见
- 道德问题
- 错误信息
- 安全
- 可解释性
- 环境影响
在2022年之前:-

2022年是人工智能之旅中的"改变游戏规则的一年"。在2022年之前,我们拥有的人工智能系统相当基本——"特定任务",只做被编程要求的事情(就像一个非常聪明的烤面包机,但用于数据)。
现在,到了2022年之后,AI模型变得更快、更多功能,可以做更多事情。
2022年发生了什么事情改变了人工智能的格局?🤔
在2022年之后:
啊,我看到你对像 CHATGPT、生成式人工智能、LLM、人工智能工程等等流行词感兴趣。
好了,准备好深入其中的核心——这些进步将人工智能从一个酷炫的工具变成让即使是最懂科技的人都会赞叹不已的东西。
基础模型

这是所有那些流传的时髦词汇的“支柱”。一旦基础模型出现,人工智能的旅程就进入了涡轮模式,并开始朝着更加光明的未来飞驰。
这些模型为像CHAT GPT、LLM和生成式AI等的进步铺平了道路,使它们成为可能,并让AI能够做比我们想象的更多事情。
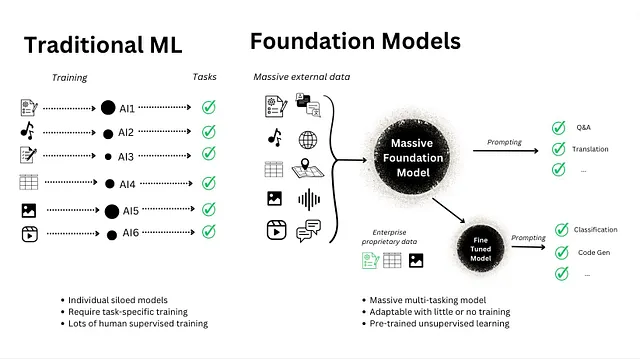
基础模型是什么?

基础模型是巨大的神经网络架构,通过大量数据训练,以解决特定问题或任务。
制作基础模型的组件:-
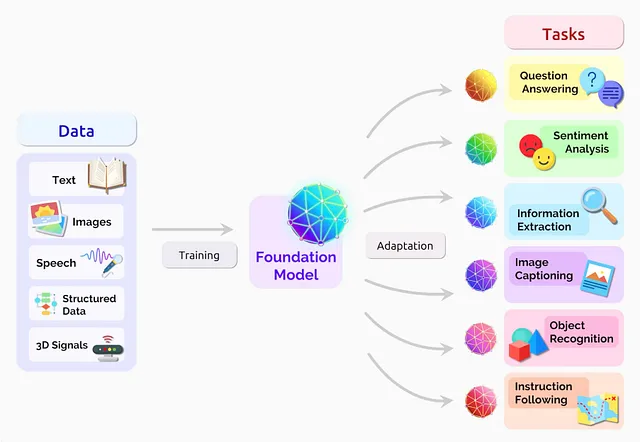
神经网络架构
数据
任务
神经网络架构 -
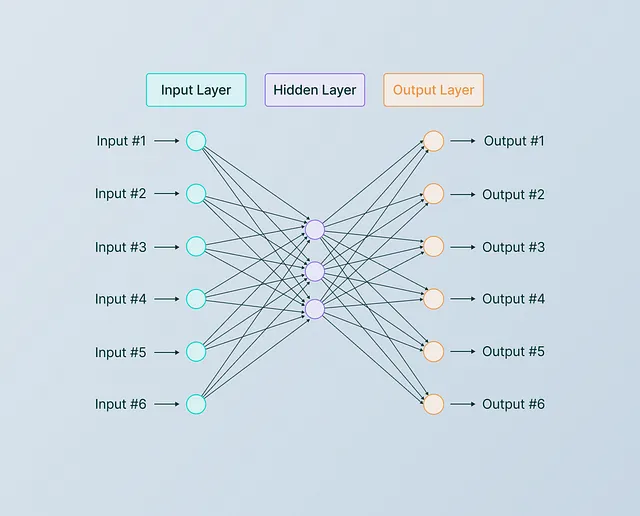
一些基础模型架构的重要方面是:
A- 巨大的参数
B-可伸缩
C-现代艺术状态
A- 巨大参数:-
模型需要很大-充满大量的参数(权重和偏差),可能有数百万。越大越好! 😄
但是为什么我们需要如此庞大的神经网络架构呢?🤔
让我们根据一点时间顺序来分析一下:
每个生物都有一个大脑,但大小各异。蚂蚁有大脑,人类也有(庆幸😄)。但是,谁的大脑可以学习和思考得更快?当然是人类!😊 我们的大脑比蚂蚁大,意味着更多的神经元,更多神经元之间的连接,最终,更多的大脑功率用于创造力、学习和思考。
大脑大小 — 更多的神经元 — 神经元之间的连接更多 — 学习历史越多
B-可伸缩:-
神经网络架构还需要可伸缩性。如果它无法处理大量数据,就无法有效地在巨大的神经网络上进行训练。想象一下:如果您的模型无法随着数据增长,就好像试图把一个巨大的大脑塞进一个蚂蚁大小的颅骨里 - 它根本塞不进去! 😅
您需要一个可以随着您输入的数据量不断增加而扩展的架构,持续学习和改进。
C- 最先进技术
神经网络架构应该提供有影响力的性能。一些最著名的架构包括组建基础模型的支柱。
变压器 / GAN / 自编码器
- 变形金刚
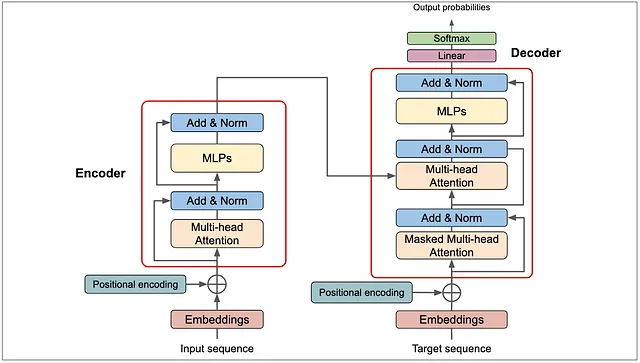
变压器于2017年推出,彻底改变了人工智能,并在基础模型的创建中被广泛使用。现在,在2024年,变压器及其变种已广泛应用于各种人工智能应用中。然而,它们并非我们依赖的唯一基础架构。
2. GAN(生成对抗网络)
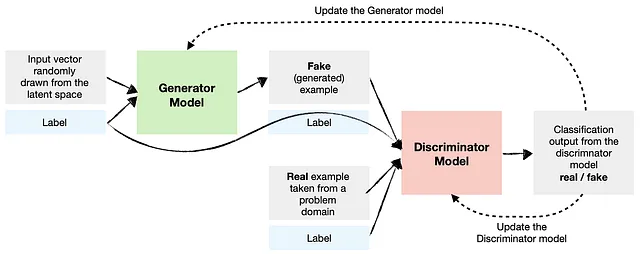
GANs主要用于构建基于视觉的模型。它们通过让两个神经网络相互对抗来生成新数据(如图像),特别适用于像图像合成这样的任务。
3. 自编码器
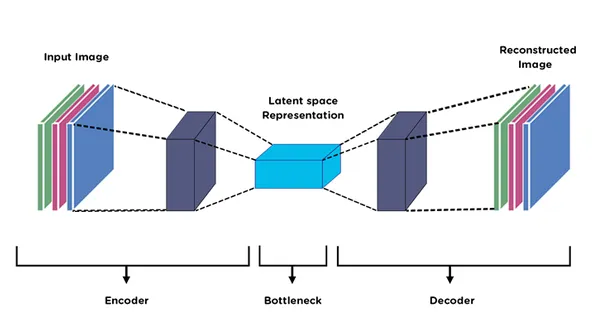
自动编码器也被用于构建基础模型,特别是用于任务如降维和无监督学习。它们帮助压缩数据,学习表示,以及重建输出。
数据
我们需要大量的数据(约100GB)来训练基础模型。
如果说建筑是大脑,那么数据就像书籍,我们从中获取知识,因此我们输入的数据越多,学习的范围就越广。这就是为什么我们需要大量的数据。
收集数据时需要遵循一些规则:
多样性:

- 数据应该是多样化的。这意味着我们必须拥有数据集的各个方面,否则将会产生偏见。
B- 方式:

- 这意味着我们想要展示什么样的数据,这取决于我们正在构建哪种基础模型。我们建立在语言、图像、音频、视频、视觉等基础上,所以基本上根据领域提供数据。
- 在模态下,我们也可以使用最具体的数据进行训练。例如-今天我们可以问CHATGPT医学答案,因为ChatGPT也是在医学数据上进行训练的,因为它是在各种数据上进行训练的。但由于它是在整个互联网数据上进行训练的,它不会提供具体的答案。因此,如果我们打算创建任何医学专用应用程序,那么我们只需向模型提供与医学相关的具体数据,而不是整个互联网数据。
任务 -
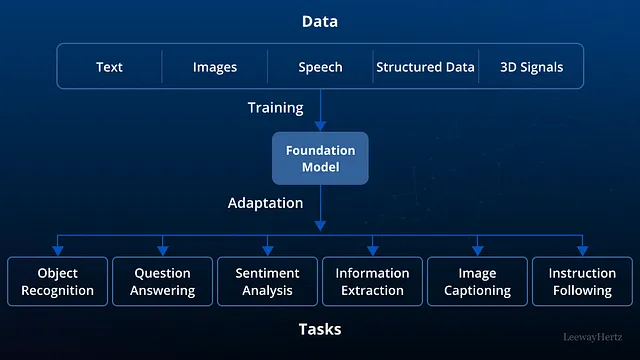
任务是构建基础模型的重要方面。
我们想要给模型什么任务是最关键的部分。就像在机器学习中,我们有不同的算法,基于这些算法,我们决定任务。在线性回归中,我们想要预测数字,在分类任务中,我们想要区分不同的类别,以此类推。
- 在基础模型中,我们试图提供一些不同的任务。事实上,我们试图提供的任务是“一般性或广泛性的”。
- 这意味着我们交给模型的任务,除了解决任务之外,模型的学习也是“可转移的”
- 可以转移意味着当它学会做任务时,模型不仅能解决任务,而且在学习的帮助下还可以解决另一个任务。这是关键点。
示例:
下一个单词预测:
这是基础模型中最著名的任务之一。在这个任务中,我们用一句话来训练一个模型,并要求它预测下一个词。对于这个任务,模型需要理解语言的运作方式。
如果神经网络架构学习语言的内部结构,它不仅可以轻松预测下一个词,还可以处理需要语言理解的其他任务。
- 例如,在情感分析中,如果我们给予文本相同的模型,并要求它确定情感是积极的还是消极的,模型可以完成这个任务,因为它已经学会了理解语言。
B. 图片标题:

假设我们有一张女孩在玩球的图片。现在,我们希望我们的模型能够生成一段描述这张图片的内容,比如“一个女孩正在玩球”。
这个任务特别有趣,因为在模型训练过程中获得的学习是可转移的。为了让模型能够用文本描述图像的内容,它必须理解图像和语言。
一旦模型学会了这一点,它还可以执行其他任务,比如识别图像中的人是男孩还是女孩等。
简而言之,基础模型就是庞大的神经网络架构。
为什么我们称它们为“基础模型”🤔
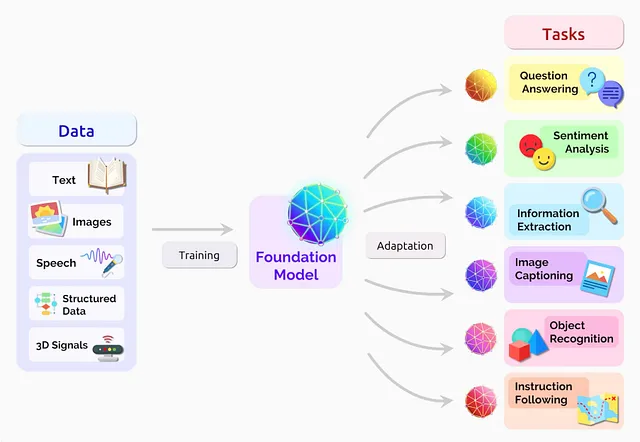
为了理解为什么基础模型被称为“基础”,我们需要了解它们是如何工作的。
基础模型分三个阶段工作:
Pre- Training, 对齐阶段, 微调
1. 预训练:
- 从架构开始,这些神经网络架构应该是庞大、多功能和最先进的。
- 我们分配一个任务给架构师来解决,这个任务应该是一般的、广泛的、可转移的。
- 提供一个巨大的数据集来解决任务。整个培训需要大量时间和计算资源。这是基础模型的最重要阶段,被称为预训练。
在这个阶段,我们的基础模型获取了关于任务的很多知识。它学习了与任务相关的基础知识,并变得具有适应性。
2. 对齐阶段:
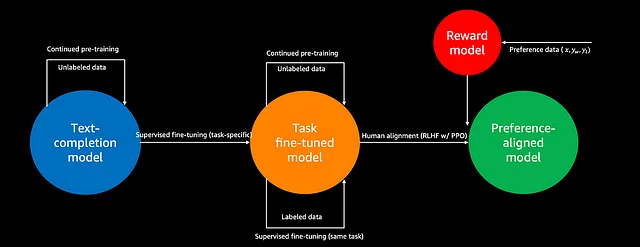
在预训练后,我们获得了一个模型,我们称之为基础模型。
- 然而,模型的数据输入可能存在一些错误,这可能会影响模型的输出。
- 一个基于图像的模型可能无法为目标受众提供正确的图像。
- 在这种情况下,我们需要使用技术重新训练模型,以过滤基础模型的输出。
一些著名的技术包括:
RLHF (强化学习与人类反馈)
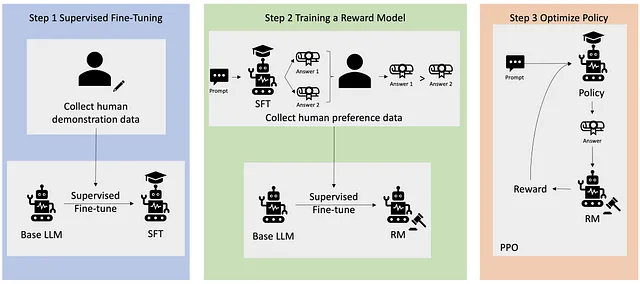
在这种技术中,我们给模型奖励和惩罚。随着时间的推移,模型学会了哪些输出是好的,哪些是坏的。这就是为什么现在当我们使用ChatGPT时,我们不再得到不好的回答 — 它已经学会了很多。
3. 微调:
在这个阶段,我们使用基础模型来完成任何所需的任务。例如,一个基于语言的基础模型学会预测下一个单词意味着它理解了语言。
现在,我们可以使用这个基础模型来完成诸如文本分类、文本摘要或问题回答等任务。
在微调阶段的一个挑战是我们通过提供新数据对基础模型进行微调。这意味着,如果我们使用一个文本预测基础模型进行文本分类任务,我们会向模型展示一些文本分类数据,并向模型解释这些数据。这有助于模型更清晰地对给定数据进行分类。
这是精调过程。在精调中,我们解冻神经网络架构的最新阶段参数并重新训练它们。基本上,我们向我们的预先训练的模型添加更多知识。
在大学里,我们学习各种科目,通过阅读所有这些科目,一个人在特定领域变得全面。然而,当一家公司雇用他们时,公司需要重新培训这个个体按照公司的程序,然后这个人开始工作。
因此,大学学习是“预备培训”计划,而公司的培训则是“微调”计划。
总结:-
我们使用Foundation模型来进行文本分类、文本摘要和文本预测等任务。为了实现这一目标,我们首先在大型数据集上对模型进行预训练。这使得模型能够全面地理解数据,从而能够后续进行其他任务的微调。
由于这个模型作为我们进行微调和重训练以完成各种特定任务的基础,因此它被称为“基础模型”。
为什么基础模型如此重要?
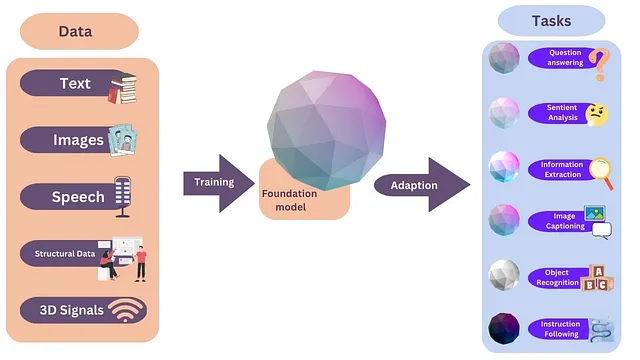
基础模型的重要性在于它们正在带来行业的范式转变。在基础模型出现之前和现在建立AI模型的方式有着巨大的不同。
让我们来理解一下:
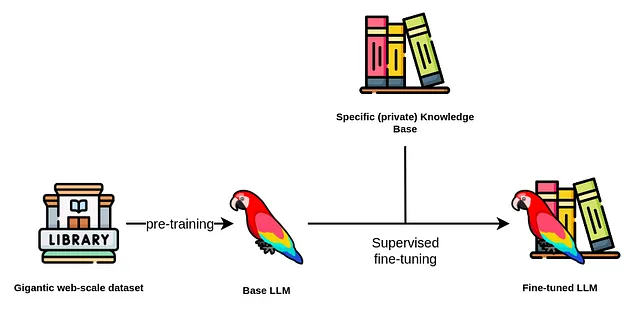
在基础模型出现之前,我们建立了特定任务的人工智能模型。例如,作为一名数据科学家,如果你正在构建一个用于处理客户查询的聊天机器人,你需要收集所有与客户相关的电子邮件数据,并使用该数据来训练一个模型。然后,你将应用自然语言处理和深度学习技术来创建聊天机器人。
然而,由于数据通常不足,并且训练一个大型深度学习模型需要大量资源(金钱、时间和大量的数据科学家团队),我们通常只能生产出次优模型。
但是当基础模型出现时,我们不再需要从头开始构建模型或创建特定任务的模型。相反,我们可以使用预训练的基础模型来处理各种任务。我们可以通过提供与我们任务相关的数据,例如客户邮件,来微调这些模型,然后使用微调的模型创建一个聊天机器人。
好处是基础模型已经由大公司在大量数据集上进行了预训练,因此它们能够立即表现良好。通过用我们特定的数据调整模型,它变得更加适应我们的要求。这意味着我们不需要大量的资源(资金和人力)来创建一个高效的模型。仅进行微调就足以构建一个强大的模型,使其比从头开始构建更加高效。
基金会模型类型
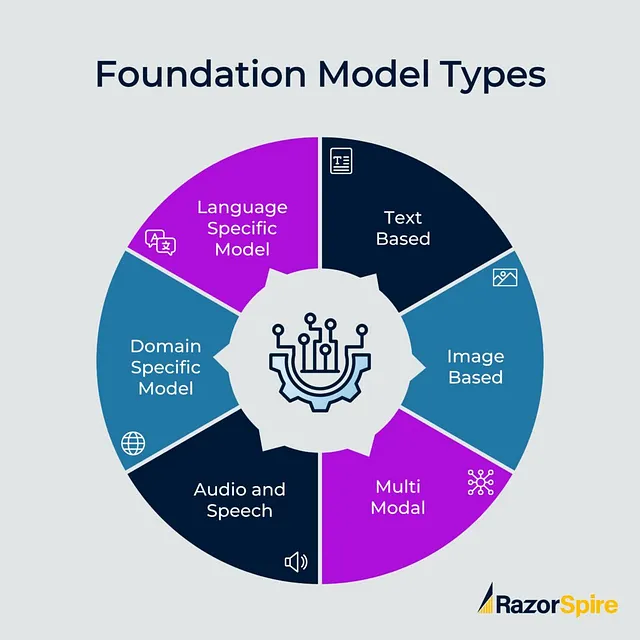
- 基于语言的基础模型(文本数据)
- 基于视觉的基础模型(图像数据)
- 多模式基础模型(图像和文字数据)
- 特定领域基础模型(用于特定领域数据)
基于语言的基础模型(文本数据):

这些模型可以处理文本生成、文本摘要、文本分类和问题回答等任务,还被称为LLM(大型语言模型)。例如:GPT、BERT是一些最著名的LLM模型。
基于视觉的基础模型(图像数据):

这些模型能够进行图像生成、物体检测、视觉问答和图像分割等任务。著名的例子是DALLE,是一个著名的基于视觉的模型。
多模基础模型(图像和文本数据):
这些模型跨越多种模态,处理诸如图像描述生成和视觉问题回答等任务。最佳示例:OpenAI的CLIP,在多模态任务方面表现出色。
领域特定基础模型(针对特定领域数据):
这些模型是为特定领域设计的。例如:
- 彭博 GPT:一种以金融为基础的模型,在其领域中表现优秀。
- 代码参考 by OpenAI:该模型是专门用于生成软件代码和调试问题的。它是在大量代码数据集上训练的,用于解决与编码相关的问题。
- GitHub Copilot是由CODEX OpenAI基金会模型驱动的知名产品。
基础模型的风险
到目前为止,基础模型似乎是我们得到的最好的模型,也是我们需要的唯一模型。但是,任何事物都有其利弊。基础模型也存在一些风险,我们应该了解。
1. 偏见
在大数据上训练的基础模型,有时我们会有一些数据可能会产生偏见。
一些公司使用基于智能的招聘系统模型,这种模型存在偏见,会因性别和年龄而拒绝合格的人选,因此数据应该没有偏见,这是一个难以实现的任务。
2. 道德关怀
有时,在我们提供数据时,可能会将某些个人的私人数据输入模型,因为基础模型是在整个互联网数据上进行训练的,这意味着现在模型可以访问有关某些个人的敏感信息,我们可以想象这有多么危险,任何人使用ChatGPT并找到他想要了解的任何人的敏感信息,那么这些数据会如何被滥用。
3. 错误信息
大型语言模型有“产生幻觉”的倾向。
这意味着,即使模型没有答案,它们也会制造答案并提供给用户。这是有问题的,因为如果我们将基础模型用于研究并依赖其结果,那么它可能会有多危险,试想一下。
4. 安全
由于我们可以用任何语言与基本模型交谈,所以如果我们以某种方式与基础模型交谈并入侵它,就会入侵整个系统。例如——在一家公司中,假设有一个系统,通过查看照片来决定是否给予该人员访问权限,如果该模型是基于基础模型的,并且有人入侵了基础模型,那么这将是一个严重的安全漏洞,任何人都可能进入安全系统。
5. 可解释性
基础模型是建立在“黑匣子”模型之上的,我们能得到答案,但我们不知道模型是如何生成特定答案的。
因此,在关心模型可解释性和解释性的情况下,基础模型并不实用,因为它是基于黑盒模型的。但希望在未来的五年里,我们也会得到基于白盒模型的基础模型,它将告诉我们为什么模型会给出这个输出。
6. 环境关注
基础模型庞大,训练基于大数据,因此需要超级计算机和过度授权,因此碳足迹将很高,这对环境不利。
你也可以在这里找到我-
https://www.linkedin.com/feed/
人工智能大脑的消息

感谢您成为我们社区的一部分!在您离开之前:
- 👏 为故事鼓掌,关注作者 👉
- 📰 在AI Mind出版物中查看更多内容
- 🧠 轻松免费地改进您的AI提示
- 🧰 探索直观的人工智能工具




