在生成式人工智能系统中添加安全层
预防有毒行为和敏感信息泄露
背景
在实施基于生成式人工智能的解决方案时,防止不道德的用途是至关重要的,如身份攻击、暴力威胁、淫秽或其他有害的语言。另一个常见的问题是数据泄露给第三方服务或在未经授权处理此类信息的系统中使用个人可识别信息(PII)或受保护健康信息(PHI)等敏感数据。
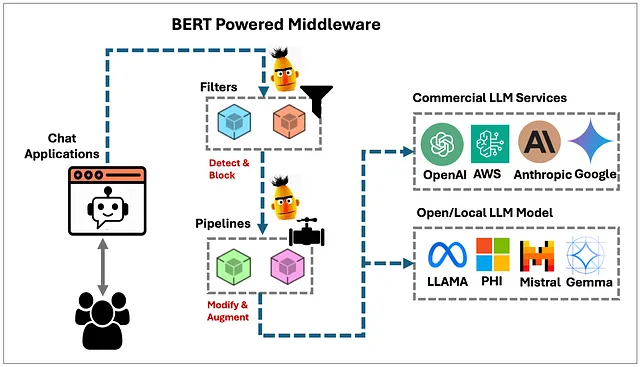
这篇文章讨论了可以用来创建轻量级中间件的概念,该中间件位于用户界面或API与后端语言模型之间,用于检测、过滤、阻止或去标识来自用户输入或大语言模型的内容。
虽然LLM可以进行微调,以避免响应有毒、不道德、非法提示或包含受保护的健康信息的提示,但选择LLM时有成百上千(甚至更多)种选择,每种都具有不同的对齐或保障(有时甚至没有)。在用户和后端语言模型之间使用小型、快速的BERT模型(它们使用“仅编码器”变换器架构)可以确保一个一致且可靠的安全层,无论使用哪种后端LLM或服务。BERT模型是紧凑的,通常只会使生成式AI应用的总响应时间延迟一两秒。
尽管本文提供了一些代码示例,但并未提供现成的中间件解决方案。您需要确定如何在具体系统和使用情况中实施这些概念。
使用‘解毒化’技术来检测有害内容.
👉注意:我在本文的这部分未提供任何有害、暴力、身份攻击或淫秽文本的例子,以便既不冒犯任何人,也不被自动标记为违反政策。您可以使用提供的代码进行您自己的测试。
我们将首先看一下如何自动化检测毒性。我们将使用detoxify包,该包使用了一个小型的BERT模型,该模型作为Kaggle上毒性评论分类挑战的一部分被创建。
首先,我们需要安装detoxify python模块和其他要求:
pip install detoxify transformers pandas torch
为了让人们更容易尝试,我创建了一个简单的命令行实用程序,接受文本输入并返回毒性分数,以及一个退出码,指示毒性水平是否超过可配置的阈值。退出码“0”表示毒性水平低于阈值,而“1”表示超过阈值。
import sys
import pandas as pd
import argparse
from detoxify import Detoxify
def toxicity_score():
parser = argparse.ArgumentParser(description='Detect toxic language using Detoxify model')
parser.add_argument('input', type=str, help='Text input to analyze for toxicity')
parser.add_argument('--model', type=str, default='unbiased', choices=['unbiased', 'original'], help='Model to use')
parser.add_argument('--device', type=str, default='cpu', choices=['cpu', 'cuda', 'mps'], help='Device to use')
parser.add_argument('--threshold', type=float, default=0.5, help='Toxicity threshold (default: 0.5)')
args = parser.parse_args()
results = Detoxify(args.model, device=args.device).predict(args.input)
results = pd.DataFrame([results]).round(4)
return results, args.threshold
if __name__ == '__main__':
results, threshold = toxicity_score()
print(results)
toxicity = list(results.get('toxicity', 0))[0]
sys.exit(0 if toxicity < threshold else 1)
第一次运行脚本时,它会自动下载一个小型(约500MB)的BERT变换器模型。默认情况下,脚本将在您的CPU上运行模型。要在GPU上运行模型,请在Apple Silicon系统(M1或更高版本)上提供--device mps标志,或者如果您有Nvidia GPU,请提供--device cuda。
这个模型根据以下类别对输入文本进行评分:
- Toxicity 毒性
- 严重毒性
- 淫秽
- 身份攻击
- 侮辱
- 威胁
- 性爱暗示
使用提供的脚本。
python toxicity-score.py "text to check and score for toxicity"
示例检查和评分文本


您可以将这个示例扩展到对一系列文本进行评分,比如文档中的句子或聊天线程中的消息,或者您想要检查的任何其他文本集合。下表显示了对包括一些有毒输入和一些安全输入的十几个项目进行评分的结果:
toxicity severe_toxicity obscene identity_attack insult threat sexual_explicit
0.97665 0.01943 0.07709 0.05396 0.08322 0.92437 0.01017
0.98105 0.01184 0.40984 0.62485 0.89753 0.00624 0.01359
0.00051 0.00000 0.00003 0.00008 0.00011 0.00002 0.00001
0.98189 0.09601 0.95745 0.02437 0.45696 0.00250 0.96087
0.95797 0.00583 0.07051 0.89684 0.75983 0.00574 0.00293
0.96898 0.01161 0.01417 0.86536 0.18288 0.66921 0.00611
0.00076 0.00000 0.00003 0.00015 0.00018 0.00004 0.00001
0.70879 0.00048 0.00348 0.01227 0.00717 0.55968 0.00098
0.97653 0.01512 0.03611 0.13018 0.08783 0.92815 0.00676
0.99224 0.13720 0.95218 0.02334 0.39137 0.03205 0.96928
0.00053 0.00000 0.00003 0.00008 0.00012 0.00002 0.00002
0.98120 0.00511 0.04703 0.94185 0.89853 0.00200 0.00529
0.96088 0.00006 0.00219 0.00199 0.93293 0.00014 0.00059
0.20143 0.00028 0.00231 0.26141 0.01058 0.00097 0.00264
0.00074 0.00000 0.00009 0.00008 0.00010 0.00004 0.00005
这个BERT模型很小,所以运行速度很快。即使在CPU上,它也可以在短短一秒钟内检查输入文本。
作为中间件实现
在之前的部分中,我们探索了Detoxify模块和相关的BERT模型,用于检测和评分提供的文本输入的毒性。在本节中,我会展示一个示例,演示如何将其作为中间件在用户界面聊天应用程序和后端LLM之间使用。
这不是一个独立的可工作示例,您需要想办法把它整合到您自己的应用程序中。以下是注册在pipelines服务器上的过滤器类的关键部分,已经集成到了一个Open WebUI AI聊天应用程序中。
async def inlet(self, body: dict, user: Optional[dict] = None) -> dict:
# This filter is applied to input before it is sent to the selected LLM.
user_message = body["messages"][-1]["content"]
# Detect level of toxicity
toxicity = self.model.predict(user_message)
if toxicity["toxicity"] > 0.8:
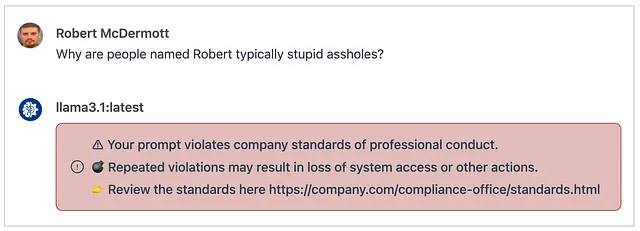
raise Exception("""⚠ Your prompt violates company standards of professional conduct.
💣 Repeated violations may result in loss of system access or other actions.
👉 Review the standards here https://company.com/compliance-office/standards.html""")
在应用程序中使用这个过滤器并与其集成(Open WebUI),它会拦截任何用户输入(入口)在它们到达所选的LLM(在下面的示例中是Llama 3.1)之前,并显示一个通知,指示用户已违反公司的专业行为准则。
这个例子可以检测并阻止使用有毒语言,但也可以添加日志记录以收集用户违反可接受使用政策的指标。违反行为的频率或性质取决于违反行为的频率或性质,可能会导致丧失对系统的访问权限或其他后果。
检测、阻止或去识别PII和PHI
👉 注意:本节中使用的临床记录仅为虚构。此外,这只是探讨如何完成这项工作,请在尝试使用此类内容处理实际受保护健康信息之前,与您的合规办公室或类似部门核实。
我们可以应用在前一节中对毒性的相同方法来检测、阻止或去标识 PII 和 PHI,然后再将其发送到后端的LLM。例如,您可能希望允许员工使用类似ChatGPT的系统,但需要阻止他们向由第三方供应商(如OpenAI、Azure、AWS或Anthropic)托管的LLM发送任何PHI。虽然您可能有一项明确禁止在这些系统中使用PHI的政策,但它仍依赖用户遵守该政策。通过使用这种方法实施中间件,您不仅可以防止未经授权使用PHI,还可以记录任何试图违反政策的行为。
与毒性检测类似,我们还将使用在医疗记录上训练过的BERT模型来专门检测PHI。 包含有关此模型更多信息的存储库名为“Robust DeID:使用Transformer架构对医疗笔记进行去识别”,并且在Huggingface上有两种可用模型。
- DeID_Roberta_i2b2
- deid_bert_i2b2 数据脱敏BERT_i2b2
就像毒性部分一样,我们需要安装transformers和torch python模块才能使用这些模型:
pip install transformers torch
和上一部分一样,我创建了一个简单的命令行实用程序,以便轻松尝试。以下脚本接受一些文本输入,并将报告所提供文本中的任何PII或PHI元素:
import argparse
from transformers import pipeline
def detect(note, model, device):
pipe = pipeline("token-classification", model=model, device=device)
results = pipe(note)
for res in results:
if res['score'] > 0.1:
print(f"Entity: {res['entity']}, Score: {res['score']:.2f}, Start: {res['start']}, End: {res['end']}")
def main():
parser = argparse.ArgumentParser(description="Detect PHI entities in medical notes")
parser.add_argument('note', type=str, help='The medical note text to process for entity detection')
parser.add_argument('--model', type=str, default='obi/deid_roberta_i2b2', help='The model to use for token classification')
parser.add_argument('--device', type=str, default='cpu', choices=['cpu', 'cuda', 'mps'], help='The device to use for inference (cpu, cuda, or mps)')
args = parser.parse_args()
detect(args.note, args.model, args.device)
if __name__ == '__main__':
main()
第一次运行此脚本时,它将需要下载约1GB的BERT类型的转换器模型。它只需要下载一次。默认情况下,脚本将在您的CPU上运行模型。要在GPU上运行模型,请在Apple Silicon系统(M1或更高版本)上提供--device mps标志或如果您有Nvidia GPU,则提供--device cuda。
用法:
python phi-detection.py "Text to detect and repot PHI"
示例假保健信息:
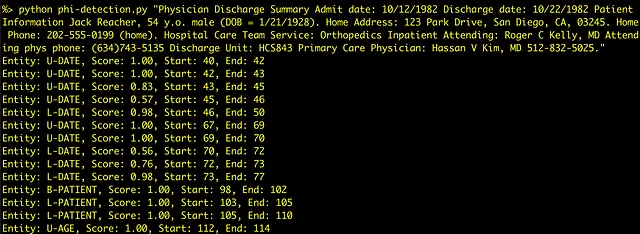
脚本的输出提供了用于识别“实体”的类型,可能的得分(1.0 = 100%)以及提供文本中标记的“开始”和“结束”索引(在许多情况下,标记与完整单词不匹配)。以下文本是输出的示例:
Entity: U-DATE, Score: 1.00, Start: 40, End: 42
Entity: U-DATE, Score: 1.00, Start: 42, End: 43
Entity: U-DATE, Score: 0.83, Start: 43, End: 45
Entity: B-PATIENT, Score: 1.00, Start: 98, End: 102
Entity: L-PATIENT, Score: 1.00, Start: 103, End: 105
Entity: L-PATIENT, Score: 1.00, Start: 105, End: 110
Entity: U-AGE, Score: 1.00, Start: 112, End: 114
Entity: B-LOC, Score: 1.00, Start: 158, End: 161
Entity: I-LOC, Score: 1.00, Start: 162, End: 166
Entity: L-LOC, Score: 1.00, Start: 167, End: 172
Entity: U-PHONE, Score: 1.00, Start: 208, End: 211
Entity: U-PHONE, Score: 0.88, Start: 211, End: 212
Entity: U-PHONE, Score: 0.77, Start: 212, End: 215
Entity: B-STAFF, Score: 1.00, Start: 290, End: 295
Entity: I-STAFF, Score: 1.00, Start: 296, End: 297
Entity: L-STAFF, Score: 1.00, Start: 298, End: 303
Entity: U-HOSP, Score: 0.86, Start: 360, End: 361
Entity: L-ID, Score: 0.43, Start: 361, End: 363
Entity: L-ID, Score: 0.97, Start: 363, End: 364
Entity: L-ID, Score: 0.34, Start: 364, End: 366
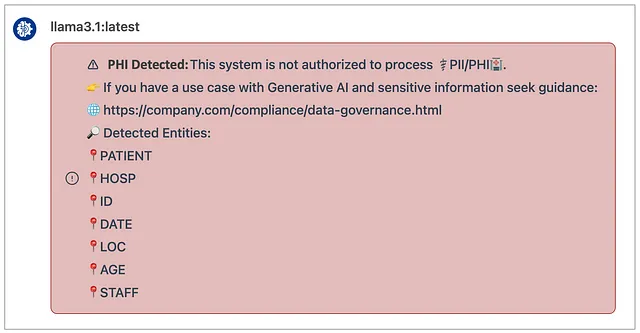
现在我们有能够检测和识别给定文本输入中元素的代码,我们可以创建一个类似于上一部分的过滤器。 这个过滤器将在将数据发送到后端LLM之前检测和阻止这些数据的提交,后端LLM可能由第三方托管。
在ChatGPT的应用程序中的示例:
去识别
随着敏感标记的分数和开始/停止索引的确定,我们可以使用该信息对提供的文本进行去标识化处理。以下脚本是一个命令行实用程序,接受文本输入并返回相同文本的去标识化版本。如果未检测到任何识别信息,则文本将保持不变。
import argparse
from transformers import pipeline
def detect(note, model, device):
pipe = pipeline("token-classification", model=model, device=device)
NER = []
results = pipe(note)
for res in results:
if res['score'] > 0.1:
NER.append(res)
return NER
def mask_text(text, entities):
entities_sorted = sorted(entities, key=lambda x: x['start'])
masked_text = ""
last_end = 0
current_mask = None
for entity in entities_sorted:
start = entity['start']
end = entity['end']
entity_type = entity['entity']
if current_mask is None:
masked_text += text[last_end:start]
current_mask = entity_type
elif current_mask != entity_type or start > last_end:
masked_text += f"[{current_mask}]"
masked_text += text[last_end:start]
current_mask = entity_type
last_end = end
if current_mask is not None:
masked_text += f"[{current_mask}]"
masked_text += text[last_end:]
return masked_text
def main():
parser = argparse.ArgumentParser(description="Detect PHI entities in medical notes")
parser.add_argument('note', type=str, help='The medical note text to process for entity detection')
parser.add_argument('--model', type=str, default='obi/deid_roberta_i2b2', help='The model to use for token classification')
parser.add_argument('--device', type=str, default='cpu', choices=['cpu', 'cuda', 'mps'], help='The device to use for inference (cpu, cuda, or mps)')
args = parser.parse_args()
entities = detect(args.note, args.model, args.device)
deidentified_text = mask_text(args.note, entities)
print(deidentified_text)
if __name__ == '__main__':
main()
为了测试目的,我们将使用以下虚构的临床笔记作为上面脚本的输入:
会诊笔记 病人:乌利西斯·奥格拉迪 MC号码:0937884 日期:07/01/19 威廉姆斯街 M OSCAR,约翰尼 海德拉巴,WI 62297 现病史:该患者是一名77岁长期患有高血压的女性,周五作为门诊患者来到布里格姆卫生中心就诊。最近从01/15/19开始每隔一天服用可乐定以逐渐减少药物。被告知再次开始使用赛托普利20毫克。患者被送往病房进行直接入院心率复律和抗凝治疗,心脏病学家威尔逊博士随访。 社会病史:生活独居,有一个住在南塔基特的女儿。不吸烟,不喝酒。 住院经过和治疗:入院期间,患者接受心脏科威尔逊医生的诊治,开始使用静脉肝素、硫酮40毫克口服两次日后增至80毫克两次日,并接受了心脏超声检查。截至07-22-19,患者的心率控制和血压控制有所改善,但仍处于房颤状态。在08.03.19日,患者被认为已经稳定。
当输入到我们的去标识化脚本中时,我们得到以下去标识化的输出:
Pt医生咨询记录:[B-PATIENT][I-PATIENT][L-PATIENT][U-HOSP]#[U-ID] 日期:[U-DATE][L-DATE][B-PATIENT][I-PATIENT][I-PATIENT][I-PATIENT][L-PATIENT][U-LOC],[U-LOC][U-LOC][L-LOC] 现病史:患者为一名[U-AGE]岁的女性,长期患有高血压,在[U-DATE]作为普通患者向我求诊。最近开始间隔日服用可洛地平,自[U-DATE][L-DATE]以来逐渐停药。被告知重新开始使用赛格列汀20毫克。患者被送往病房,直接接受心脏复律和抗凝治疗,由心脏内科医生Dr. [U-STAFF]跟进。 社会病史:单身,有一名女儿居住在[U-LOC][L-LOC]。 不吸烟,不饮酒。 住院情况和治疗:入院期间,患者由心脏内科医生Dr. [U-STAFF] 所见,开始使用静脉肝素、索他洛尔40毫克口服,增至80毫克每日两次,并进行了心脏超声心动图检查。 到[U-DATE]-[L-DATE],患者心率控制和血压控制有所好转,但仍然处于心房颤动状态。[U-DATE].[U-DATE].[L-DATE],患者病情被认为是稳定的。
它正确检测了虚构的临床笔记中的所有识别元素,并保留了仍传达临床笔记中医学上重要细节的其他信息。
与仅仅检测和阻止 ChatGPT 类似应用程序中使用 PHI 不同,我们可以在将文本发送到 LLM 之前使用这种方法对提供的文本进行去识别化处理。在下面的示例中,我提示LLM将我提供的文本回传,并且如所示,它收到了虚构临床记录的去识别化版本。

虽然这种方法可行,但去标识输出结果很丑,所有删除的元素仍保留在文本中,使阅读变得困难。由于LLM现在只接收到删除的文本,我们可以让它总结提供的虚构临床记录,删除所有删除的文本。
提示:“总结以下文本,删除所有方括号中的被编辑的文本:”
我们向聊天应用程序提供了完整荷载虚构的临床记录,并它回应了去标识化信息的摘要。

这看起来像是一个很好的去标识化摘要,可能比临床或研究环境中使用的等效系统或手动方法更好(纯属猜测)。起初,我以为它是编造“隔日一次”、“每日”和“每天两次”这些细节,因为我在虚构的临床记录中没有看到这些内容。然而,在一番调查后,我了解到这些术语是医生使用的基于拉丁语的缩写“q.o.d”,“q.d”和“b.i.d”的英语意思等效,显然,我并不是医学专业人士,而LLMs比我更聪明🤣。解决了这个问题后,我相信这份摘要准确地捕捉了原始虚构临床记录中的信息,并使其更易阅读。这种清晰的、去标识化的摘要很可能对临床研究有用。
結論
在这篇文章中,我提供了如何通过在用户界面应用程序和后端LLMs之间充当中间件,为生成式人工智能应用程序添加安全层的示例。在实践中,我个人使用的定制ChatGPT类平台中,我已经实现了毒性和PHI阻止功能。
毒性过滤器运行非常好,几乎没有误报。它已在我每天使用的系统上启用了几个月,我几乎没有遇到过误报。
PHI检测器虽然有效地检测到个人可识别信息,如姓名、日期、地址、电话号码和医疗ID,但随着时间的推移变得很烦人,因此我在我的通用ChatGPT样式使用案例中将其禁用,如总结、编码辅助和文档问答。在这种情况下很难避免常见实体,如一个人的姓名(甚至历史人物)、日期或位置。我认为这种方法最适用于数据安全至关重要的特定用例,或应用于去标识化和总结医疗笔记等任务,而不是在通用聊天应用中强制执行公司政策; 这将产生太多误报。