使用ChatGPT o1-preview 进行代码生成:一个人工智能合作故事
一个C++和Python的案例:比较和见解。
概述
本文利用代码生成实验来说明人工智能与人类的合作的重要性,强调人类专业知识如何增强人工智能的效力。通过提供有针对性的知识和背景,可以更好地引导模型的输出朝着实际解决方案发展。这种合作动态展示了人类直觉和人工智能辅助如何能够相互补充,实现产出。
实验
我最近阅读了安德鲁·雷甘(等人)2016年关于“情感分析工具,用于提取书面故事中读者感知的情绪内容”的论文。巧合的是,我刚写了一个短篇故事,很好奇用它作为数据测试他的一些算法。这也是一个评估ChatGPT代码生成能力的绝佳机会,它的能力得到了显著提高。我定期评估大型语言模型以跟踪它们的进展,而这些实验提供了有用的见解。
这也是分享几个经验教训的机会。在最近的Substack帖子中,我讨论了如何通过合作的多提示方法为简单的情感分析工具编写有效的Python代码。与其让ChatGPT在一个单一提示中处理所有事情,通常更有效的方法是迭代 - 逐步审查其输出,提供反馈,改进响应 - 反复。您可以在下面的链接中找到更多关于那个实验的详细信息。
对ChatGPT o1-preview代码生成(substack.com)的想法
最近,我用C++进行了类似的实验,请求ChatGPT o1-preview生成一个基于我之前Python实验的见解的情感分析工具。本文提供了这两个实验的轶事式比较和获得的见识。
虽然两个实验都取得了成功,但细节有所不同。Python 代码生成过程无需调试,只需进行最少量的代码清理,尽管我需要指导其算法和 API 的选择。相比之下,C++ 代码生成过程需要更多的参与——不仅要指导代码生成,还要进行调试和清理代码。
这种差异并不令人意外——有大量的Python代码可用于大型语言模型的训练。与机器学习任务相关的Python代码也受益于大量开源模块的可用性。例如,ChatGPT常常喜欢使用NLTK进行文本标记化,并熟练掌握LangChain用于OpenAI API集成。
- 自然语言工具包(NLTK)- 维基百科
- LangChain — 维基百科
ChatGPT生成的C++版本不依赖外部分词器;相反,它实现了自己的分词器。然而,ChatGPT使用外部的C++集成包来与OpenAI API 进行交互。最终,我引导ChatGPT朝着一个更适合我的评估的解决方案发展。我让它调整应用程序架构,以最小化我需要集成的外部C++包数量。
在这两种情况下,与模型进行逐步对话有助于细化需求,澄清模糊之处,并逐步改进代码。
讨论部分将比较Python和C++代码生成实验的见解。
Python 实验
这些负面性、积极性和戏剧强度的水平是基于文本窗口与预定义的“情感锚”嵌入的语义相似度而确定的。以下情感锚点被使用:
- ‘戏剧性’: “我感觉戏剧性,兴奋并充满肾上腺素冲动。”
- ‘积极’: “我今天感觉非常开心和快乐!”
- ‘中立’:“天气很一般,没有什么特别的事情发生。”
- ‘负面’:“我今天感觉很沮丧和压抑。”
情感或情绪是使用ChatGPT o1-preview生成的Python脚本计算的(附录A)。 我不需要对代码进行调试。 然而,在整个代码生成过程中,ChatGPT和我在算法和设计方面进行了广泛的迭代(附录B)。
在两个实验中,文本相似性基于文本窗口和情感锚点之间的余弦相似度。
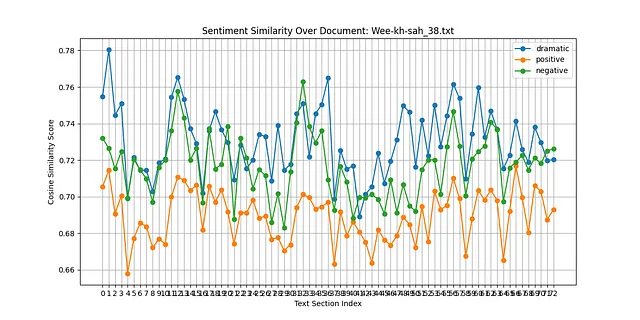
在Python实验中,计算这些情感或心情的工具是由ChatGPT (o1-preview) 生成的一个Python脚本,如附录A所示。虽然我没有需要调试代码,但是ChatGPT和我通过附录B中的提示不断迭代以完善算法和代码设计。
C++ 实验
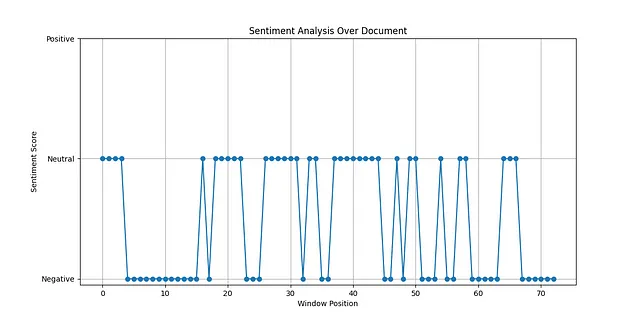
图2展示了C++程序的输出。我没有要求它绘制和图1中相同的细节,但结果是一样的。然而,一个显著的区别是应用程序的架构;它不是单个应用程序或可执行文件。一个前端C++情感分析部分与单独的Python进程交流(使用REST交互)。
- REST - 维基百科(表现状态转移)
我最初让ChatGPT使用一个提示生成C ++代码,该提示汇总了我们在创建Python工具时早期交流中得出的许多结论。 提示中包含的许多元素都在附录B中有记录。
我给ChatGPT提供的初始提示生成C++情感分析工具如下。
Propose a sentiment analysis C++ program based on using OpenAI embeddings and a sliding text window applied over text documents.
For example, it may want to obtain the embeddings for the documents in the following manner:
embeddings_model = OpenAIEmbeddings(openai_api_key=openai_api_key)
texts = [doc.page_content for doc in documents]
embeddings = embeddings_model.embed_documents(texts)
You should use the distance between the embeddings of the input text and predefined embeddings that represent key sentiments (e.g., positive, neutral, and negative). This approach leverages semantic similarity to classify sentiment based on how close the input text's embedding is to these predefined "sentiment anchor" embeddings.
The building block algorithm steps are, per document:
Tokenize text in the document.
Create sliding windows.
Generate embeddings for each window using LLM.
Classify sentiment for each window.
Optional smoothing of sentiments across windows.
Visualize the sentiments as a graph representing the entire document.
Design Guidelines:
The program should be written in C++.
The program should call a REST Python service that uses Python modules to implement the tokenizer and to obtain the OpenAI embedding model.
Constraints:
Do not use libcurl.
Do not use Boost and Boost.Asio
请注意,附录B中的提示不包括最后两节“设计指南”和“约束条件”。这些是新添加的。我特意要求ChatGPT使用Python服务通过HTTP / REST连接到C ++客户端来集成OpenAI API,而不是尝试直接从C ++客户端与libcurl或Boost进行集成。
在以前的实验中,ChatGPT经常使用libcurl或Boost.Asio生成C++代码进行HTTP(S)请求,除非有明确指示要求。设置libcurl或Boost比使用Python功能和模块更复杂。例如,libcurl要求其库专门为Windows构建。为了简化这个实验,我选择让C++客户端通过Python服务依赖于OpenAI API。
- cURL/ libcurl — 维基百科
- 增强(C++库)- 维基百科
图3描述了ChatGPT生成的架构,用于实现C++情感分析工具。情感分析程序(客户端)通过HTTP/REST与Python服务进行通信,使用大型语言模型嵌入。Python RESTful服务通过Python网络资源与OpenAI进行通信,以获取模型嵌入。C++客户端将其结果输出到CSV文件中。ChatGPT生成了一个Python脚本,以图形格式显示这些结果。ChatGPT提供了生成使用Qt的C++可视化的选项(如果我按下),但是为了保持这个实验简单,我选择了Python脚本。
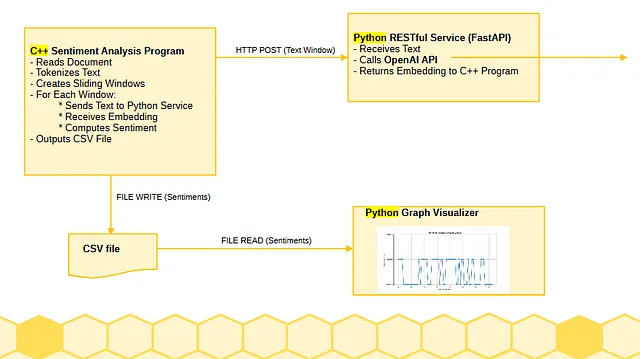
C++客户端是使用Microsoft Visual Studio Community 2022版本17.11.5构建和执行的。Python服务是在PyCharm 2024.1(社区版)的虚拟环境中本地运行的。
- Visual Studio — 维基百科
- PyCharm — 维基百科
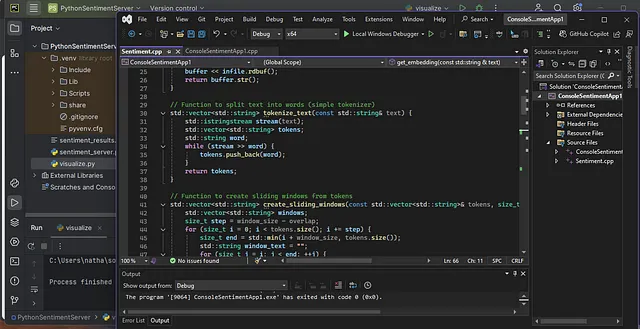
如描述所示,ChatGPT生成的C++代码需要在我编译、连接和执行之前进行“代码工程化”。这些是我遇到的主要问题——
- 与不同版本的C ++存在代码不兼容性。本实验中的代码使用ISO C++20标准进行编译。
- 由于模板实现和版本之间的差异、我尝试过的特定外部模块的相互影响、我使用的生成代码,以及所使用的C++编译器版本,导致了不兼容性。
在一个轻松的话题上,ChatGPT o1-preview可能是有共鸣的。请注意下面一段来自其回应的内容!
很抱歉听到您仍然遇到与stdext::checked_array_iterator
讨论
实验表明,在与AI合作进行代码生成时,迭代式、多提示的方法的重要性。这种方法可以优化算法,识别模糊性,并整体改进生成的代码。
一个关键的洞察是,一个互动、迭代的方法比依靠单一、详细的提示更有效地生成可用代码。在Python的例子中,我通过多个迭代步骤指导了ChatGPT,以生成满足我的特定需求的算法。这一步骤一步的改进使得代码与我的目标更好地对齐。
同样,在C ++示例中,迭代对于解决代码错误和集成问题至关重要。这些发现表明,与模型进行持续交互,而不是从一开始就期望得到完整的解决方案,会导致实用且功能代码。
另一个重要的观点是,你事先了解的或者沿途摸索出的知识 — 无论是从经验还是其他来源获取 — 越多,你就越能加快优化提示来引导一个大型语言模型迈向一个好的解决方案。在 Python 情感分析工具的例子中,我对涉及的算法和 API 的熟悉度让我能够帮助 ChatGPT 迅速收敛到一个干净且有效的实现。
在C ++版本中,我可以操纵ChatGPT远离我发现耗时的外部模块,并提出另一种更合适的应用架构。ChatGPT利用我的指导,最终提供了一个Python REST服务,以弥合C++复杂性和Python API集成的便捷性之间的差距。这是人工智能与人类之间协同作用的实际例证。通过引导人工智能走向更高效的架构,避免了不必要的复杂性,从而导致了一种更简单但令人满意的解决方案。
参考资料
里根,A.J.,米切尔,L.,凯利,D.等。故事的情感弧线由六种基本形状主导。EPJ数据科学。5,31(2016)。https://doi.org/10.1140/epjds/s13688-016-0093-1
附录A
由ChatGPT生成的用于简单情绪分析的Python代码。
import os
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import cosine_similarity
import nltk
# Import necessary classes from langchain
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import TextLoader
from langchain.text_splitter import NLTKTextSplitter
# Download NLTK data files (only need to run once)
nltk.download('punkt')
# Set up OpenAI API key
openai_api_key = ""
# Specify the paths to your text files
file_paths = [
"./data/cyclops_storm.txt",
"./data/Wee-kh-sah_38.txt"
]
# Define the function to read and split the text files
def do_read_text_files(file_paths):
documents = []
for file_path in file_paths:
loader = TextLoader(file_path, encoding='utf-8')
raw_documents = loader.load()
for document in raw_documents:
content = document.page_content
metadata = document.metadata
print(f'File: {file_path}, length of page_content={len(content)}')
text_splitter = NLTKTextSplitter(chunk_size=1000, chunk_overlap=100)
text_content = " ".join([doc.page_content for doc in raw_documents])
text_sections = text_splitter.split_text(text_content)
print(f'File: {file_path}, number of text sections chunked={len(text_sections)}')
documents.append({
'file_path': file_path,
'text_sections': text_sections
})
return documents
# Define the function to generate embeddings
def generate_embeddings(texts, openai_api_key):
embeddings_model = OpenAIEmbeddings(openai_api_key=openai_api_key)
embeddings = embeddings_model.embed_documents(texts)
return embeddings
# Read and split the text files into sections
documents = do_read_text_files(file_paths)
# Define the extended sentiment anchor texts and get their embeddings
sentiment_texts = {
'dramatic': "I am feeling dramatic, excited and on an adrenaline rush.",
# 'non-dramatic': "I am feeling bored, lack-luster, without energy.",
# 'cormac': "In the style of Cormac McCarthy.",
# 'margaret': "In the style of Margaret Atwood.",
# 'king': "In the style of Stephen King.",
'positive': "I am feeling very happy and joyful today!",
# 'neutral': "The weather is average, and nothing special is happening.",
'negative': "I am feeling very sad and depressed today."
}
# Generate embeddings for sentiment anchors
sentiment_embeddings = {}
for sentiment, text in sentiment_texts.items():
embedding = generate_embeddings([text], openai_api_key)[0]
sentiment_embeddings[sentiment] = embedding
# Process each document individually
for doc in documents:
file_path = doc['file_path']
text_sections = doc['text_sections']
# Generate embeddings for each text section
window_embeddings = generate_embeddings(text_sections, openai_api_key)
# Compute similarities for each sentiment for each text section
similarity_scores = {sentiment: [] for sentiment in sentiment_embeddings.keys()}
for embedding in window_embeddings:
for sentiment, sentiment_embedding in sentiment_embeddings.items():
similarity = cosine_similarity([embedding], [sentiment_embedding])[0][0]
similarity_scores[sentiment].append(similarity)
# Visualize the similarities as a graph representing the entire document
plt.figure(figsize=(12, 6))
for sentiment, scores in similarity_scores.items():
plt.plot(scores, marker='o', linestyle='-', label=sentiment)
plt.title(f'Sentiment Similarity Over Document: {os.path.basename(file_path)}')
plt.xlabel('Text Section Index')
plt.ylabel('Cosine Similarity Score')
plt.xticks(range(len(text_sections)))
plt.legend()
plt.grid(True)
plt.show()附录B
这个附录列出了我用来指导ChatGPT o1-preview生成情感分析工具的提示。它突出了高层次概念提示和关于代码、API和算法的具体反馈的结合。
Propose a sentiment analysis algorithm based on LLM embeddings and sliding text windows.
===
Propose a simple sentiment classification layer implementation.
===
Instead of labeled sentiment data and a feed-forward classification layer, can you compute the distance of the embedding from embeddings for key sentiments?
====
Propose a sentiment analysis Python program based on using OpenAI embeddings and a sliding text window applied over text documents.
For example, it may want to obtain the embeddings for the documents in the following manner:
embeddings_model = OpenAIEmbeddings(openai_api_key=openai_api_key)
texts = [doc.page_content for doc in documents]
embeddings = embeddings_model.embed_documents(texts)
You should use the distance between the embeddings of the input text and predefined embeddings that represent key sentiments (e.g., positive, neutral, and negative). This approach leverages semantic similarity to classify sentiment based on how close the input text's embedding is to these predefined "sentiment anchor" embeddings.
The building block algorithm steps are, per document:
Tokenize text in the document.
Create sliding windows.
Generate embeddings for each window using LLM.
Classify sentiment for each window.
Optional smoothing of sentiments across windows.
Visualize the sentiments as a graph representing the entire document.
====
Can you update the code to use the openai 1.0.0 api, example below. def generate_embeddings(documents, openai_api_key):
embeddings_model = OpenAIEmbeddings(openai_api_key=openai_api_key)
texts = [doc.page_content for doc in documents]
embeddings = embeddings_model.embed_documents(texts)
for i, document in enumerate(documents):
document.metadata['embedding'] = embeddings[i]
return documents
====
Can you rework the code so it uses this text reader? def do_read_text_file(file_path):
loader = TextLoader(file_path, encoding='utf-8')
raw_documents = loader.load()
for document in raw_documents:
content = document.page_content
metadata = document.metadata
print(f'length of page_content={len(content)}')
text_splitter = NLTKTextSplitter(chunk_size=1000, chunk_overlap=100)
text_content = " ".join([doc.page_content for doc in raw_documents])
text_sections = text_splitter.split_text(text_content)
print(f'number of text sections chunked={len(text_sections)}')
return text_sections
====
can you update this code to read and plot output for multiple documents (multiple file paths).
====
If I want to extend the sentiments to include more than the three currently in place include some that are overlapping, how might you display it? Consider this example list. sentiment_texts = {
'dramatic' : "I am feeling dramatic, excited and on an adrenaline rush.",
'non-dramatic' : "I am feeling bored, lack-luster, without energy.",
'cormac' : "In the style of Cormac McCarthy",
'margaret' : "In the style of Margaret Atwood",
'king' : "In the style of Stephen King",
'positive': "I am feeling very happy and joyful today!",
'neutral': "The weather is average, and nothing special is happening.",
'negative': "I am feeling very sad and depressed today."
}
附录 C
ChatGPT生成的用于简单情感分析的C++客户端代码。与附录A中的Python脚本不同,C++客户端依赖于一个单独的Python服务用于其嵌入(见附录D)。查看应用程序架构的图3。
// main.cpp
#include <iostream>
#include <fstream>
#include <sstream>
#include <vector>
#include <string>
#include <algorithm>
#include <cmath>
#include <thread>
#include <mutex>
#include <httplib.h>
#include <nlohmann/json.hpp>
using json = nlohmann::json;
// Function to read the entire text file into a string
std::string read_text_file(const std::string& filename) {
std::ifstream infile(filename);
if (!infile.is_open()) {
throw std::runtime_error("Cannot open the file: " + filename);
}
std::stringstream buffer;
buffer << infile.rdbuf();
return buffer.str();
}
// Function to split text into words (simple tokenizer)
std::vector<std::string> tokenize_text(const std::string& text) {
std::istringstream stream(text);
std::vector<std::string> tokens;
std::string word;
while (stream >> word) {
tokens.push_back(word);
}
return tokens;
}
// Function to create sliding windows from tokens
std::vector<std::string> create_sliding_windows(const std::vector<std::string>& tokens, size_t window_size, size_t overlap) {
std::vector<std::string> windows;
size_t step = window_size - overlap;
for (size_t i = 0; i < tokens.size(); i += step) {
size_t end = std::min(i + window_size, tokens.size());
std::string window_text = "";
for (size_t j = i; j < end; ++j) {
window_text += tokens[j] + " ";
}
windows.push_back(window_text);
if (end == tokens.size()) break;
}
return windows;
}
// Function to get embedding from RESTful service
std::vector<float> get_embedding(const std::string& text) {
httplib::Client cli("localhost", 8000); // Adjust host and port if needed
json request_json = { {"text", text} };
auto res = cli.Post("/embed", request_json.dump(), "application/json");
if (res && res->status == 200) {
json response_json = json::parse(res->body);
return response_json["embedding"].get<std::vector<float>>();
}
else {
// Handle error
std::cerr << "HTTP Status: " << res->status << "\n";
std::cerr << "Response Body: " << res->body << "\n";
throw std::runtime_error("Failed to get embedding from REST service");
}
}
// Function to compute cosine similarity
float cosine_similarity(const std::vector<float>& A, const std::vector<float>& B) {
float dot_product = 0.0f;
float norm_a = 0.0f;
float norm_b = 0.0f;
for (size_t i = 0; i < A.size(); ++i) {
dot_product += A[i] * B[i];
norm_a += A[i] * A[i];
norm_b += B[i] * B[i];
}
return dot_product / (std::sqrt(norm_a) * std::sqrt(norm_b) + 1e-8); // Add small value to prevent division by zero
}
// Function to assign sentiment based on similarity scores
std::string assign_sentiment(const std::vector<float>& embedding,
const std::vector<float>& positive_anchor,
const std::vector<float>& neutral_anchor,
const std::vector<float>& negative_anchor) {
float sim_positive = cosine_similarity(embedding, positive_anchor);
float sim_neutral = cosine_similarity(embedding, neutral_anchor);
float sim_negative = cosine_similarity(embedding, negative_anchor);
if (sim_positive >= sim_neutral && sim_positive >= sim_negative) {
return "Positive";
}
else if (sim_negative >= sim_positive && sim_negative >= sim_neutral) {
return "Negative";
}
else {
return "Neutral";
}
}
int sentiment_main() {
try {
// Step 1: Read the document
std::string filename = "C:/Users/natha/source/repos/data/Wee-kh-sah_38.txt"; // Replace with your filename
std::string text = read_text_file(filename);
// Step 2: Tokenize text
auto tokens = tokenize_text(text);
// Step 3: Create sliding windows
size_t window_size = 200; // Adjust window size
size_t overlap = 50; // Adjust overlap size
auto windows = create_sliding_windows(tokens, window_size, overlap);
// Step 4: Get embeddings for sentiment anchors
std::vector<float> positive_anchor = get_embedding("I am happy");
std::vector<float> neutral_anchor = get_embedding("It is a day");
std::vector<float> negative_anchor = get_embedding("I am sad");
// Mutex for thread-safe access to shared data
std::mutex mtx;
// Vectors to store results
std::vector<std::string> sentiments(windows.size());
std::vector<float> positions(windows.size());
// Step 5: Process each window (with multithreading)
std::vector<std::thread> threads;
for (size_t idx = 0; idx < windows.size(); ++idx) {
threads.emplace_back([&, idx]() {
// Get embedding for the window
auto embedding = get_embedding(windows[idx]);
// Assign sentiment
auto sentiment = assign_sentiment(embedding, positive_anchor, neutral_anchor, negative_anchor);
// Store results
std::lock_guard<std::mutex> lock(mtx);
sentiments[idx] = sentiment;
positions[idx] = static_cast<float>(idx);
});
}
// Wait for all threads to complete
for (auto& t : threads) {
t.join();
}
// Optional Smoothing (Simple Moving Average)
/*
// Uncomment to enable smoothing
for (size_t i = 1; i < sentiments.size() - 1; ++i) {
if (sentiments[i - 1] == sentiments[i + 1]) {
sentiments[i] = sentiments[i - 1];
}
}
*/
// Step 6: Output results to CSV for visualization
std::ofstream outfile("sentiment_results.csv");
outfile << "Position,Sentiment\n";
for (size_t i = 0; i < sentiments.size(); ++i) {
outfile << positions[i] << "," << sentiments[i] << "\n";
}
outfile.close();
std::cout << "Sentiment analysis completed. Results saved to 'sentiment_results.csv'.\n";
}
catch (const std::exception& ex) {
std::cerr << "Error: " << ex.what() << "\n";
}
return 0;
}
附录D。
C++客户端代码(见附录C),由ChatGPT生成用于简单情感分析,依赖于Python服务来提供所需的嵌入。下面是Python服务。请参见应用程序结构的图3。
值得注意的是,这个实现基于FastAPI而不是Flask。本文提供更多信息,并对比这两个框架。
# app.py
# uvicorn sentiment_server:app --host 0.0.0.0 --port 8000
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from langchain.embeddings import OpenAIEmbeddings
import os
app = FastAPI()
# Set your OpenAI API key
openai_api_key = os.getenv("OPENAI_API_KEY")
# Alternatively, you can set the API key directly
openai_api_key = "api-key"
# Initialize the embeddings model with specified model
try:
embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002", openai_api_key=openai_api_key)
except Exception as e:
print(f"Error initializing OpenAIEmbeddings: {e}")
raise
class TextData(BaseModel):
text: str
@app.post("/embed")
async def embed_text(data: TextData):
try:
# Use embed_query for a single text input
embedding = embeddings_model.embed_query(data.text)
return {"embedding": embedding}
except Exception as e:
print(f"Exception occurred during embedding: {e}")
raise HTTPEx
附录 E
C++客户端(见附录C),由ChatGPT生成用于简单情感分析的,输出一个包含故事情感的CSV文件。下面是用于可视化CSV文件的Python工具。请参见图2查看其输出。请参见图3查看应用程序架构。
# visualize.py
import pandas as pd
import matplotlib.pyplot as plt
# Read the CSV file
df = pd.read_csv('sentiment_results.csv')
# Map sentiments to numeric values for plotting
sentiment_map = {'Positive': 1, 'Neutral': 0, 'Negative': -1}
df['SentimentScore'] = df['Sentiment'].map(sentiment_map)
# Plot the sentiment scores
plt.figure(figsize=(12, 6))
plt.plot(df['Position'], df['SentimentScore'], marker='o')
plt.title('Sentiment Analysis Over Document')
plt.xlabel('Window Position')
plt.ylabel('Sentiment Score')
plt.yticks([-1, 0, 1], ['Negative', 'Neutral', 'Positive'])
plt.grid(True)
plt.show()