使用GPT Agent作为虚拟数据科学家
数据科学的世界正在迅速发展,其中最激动人心的创新之一是使用GPT代理来简化和增强工作流程。基于GPT的模型,如OpenAI的ChatGPT,已经成为强大的工具,能够执行各种数据科学任务,几乎像虚拟数据科学家一样。通过利用GPT代理的能力,企业和专业人士可以自动化数据分析过程的部分内容,减少手动工作量,并提高决策速度。
一个GPT代理能够协助数据科学流程的许多阶段,包括数据清洗、探索性数据分析、模型选择,甚至报告见解。例如,它可以自动分析数据集,发现相关性,创建数据可视化,并为机器学习任务建议模型。在复杂情况下,它可以处理跨多个变量的大型数据集,提供智能摘要,帮助团队快速识别模式。
使用GPT作为虚拟数据科学家的一个关键优势是其适应性。无论是处理结构化数据还是非结构化数据,运行情感分析,还是支持先进的机器学习工作流程,GPT代理可以提供动态的,实时的帮助。它作为数据科学家和分析师的合作伙伴,减少了花在重复任务上的时间,让他们能够专注于更高级别的战略和决策。
随着我们继续将人工智能工具整合到数据科学工作流程中,利用GPT代理可以重新定义生产力,并将我们带向一个机器智能和人类智能无缝合作以从数据中获取洞见的未来。通过像主动人工智能这样的概念的进步,这一切达到了一个全新的层次。
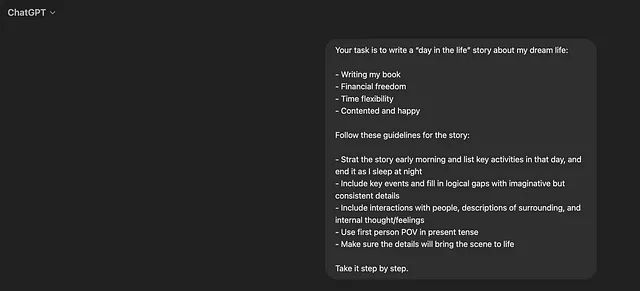
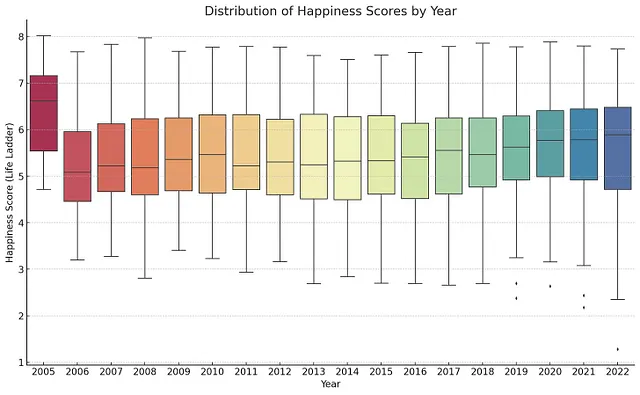
在这里,我在尝试促使ChatGPT充当数据科学家并要求其创建一个Spotify数据集的探索性数据分析,目的是识别最受欢迎的歌曲经验进行分享:https://github.com/RM-RAMASAMY/Using_Chatbots/blob/main/EDA%20on%20Spotify%20Dataset.pdf
让我知道您在评论区的想法!