ChatGPT 用于数据分析:初学者指南
使用ChatGPT的高级数据分析工具创建美丽的可视化图表
大多数人认为ChatGPT是一种对话式聊天机器人。 然而,ChatGPT也是一种全面的数据分析工具,可以处理各种数据文件格式,包括Excel电子表格、CVS文件、PDF和甚至JSON文件。
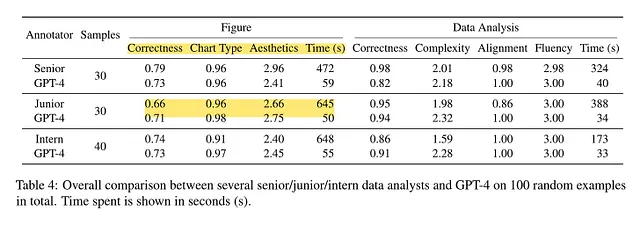
事实上,这篇论文发现 ChatGPT 在各种数据分析任务中实际上能够达到与人类相当的表现。与此同时,它比一名高级数据分析师要快得多,成本也便宜超过200倍!
在本指南中,我将向您展示如何使用ChatGPT在几分钟内执行多个数据分析任务,无需编码经验或昂贵的统计软件。上传您的数据后,您可以使用简单的对话提示清理、转换和可视化数据。
总结
我们将使用最新的《世界幸福报告》数据来:
- 创建可视化图表,如条形图,折线图,箱线图和热力图。
- 分析随着时间变化、国家间以及跨越不同变量的趋势。
- 执行回归分析,甚至探讨预测建模,包括更先进的方法,如潜在分析。
该指南还将包括如何使您的输出更一致和视觉上更吸引人的技巧。
上传多个文件
您可以在单个对话中一次上传多达10个文件,这意味着您可以引入多个数据集,并让ChatGPT帮助您无缝地比较或合并它们。
限制
在开始之前,强调一下高级数据分析功能仍处于实验阶段是非常重要的。它有时可能会混淆,产生错误的陈述或引入数字错误(这在LLMs中很常见)。因此,为了获得最佳结果,请始终仔细验证输出。在创建可视化或模型时,您可能需要多次调整提示,以确保一切看起来正确并且合乎逻辑。
此外,“查看分析”功能可以让您查看ChatGPT用于创建输出的底层Python代码。这是验证所采取步骤并仔细检查计算的绝佳方式。您还可以要求ChatGPT提供可下载的程序文件或新的转换数据集,以便您有记录所有修改的方式。
如何启用高级数据分析工具
高级数据分析功能仅适用于ChatGPT Plus用户(每月$20)。要使用它,只需登录ChatGPT,开始新的聊天,并上传您的数据文件。ADA功能将自动激活,识别您想要进行数据分析的时候。
使用专门的GPTs
虽然您无需进行任何操作即可使用ADA功能,ChatGPT具有由OpenAI开发的专门“数据分析员”GPT。该GPT专门针对数据分析任务进行了微调。要使用它,请在左上角点击“探索GPTs”,然后在开始分析之前选择数据分析员GPT。我将在下面的分析中使用数据分析员GPT。
高级数据分析功能是如何运作的?
- 上传您的数据:通过ChatGPT的聊天界面上传您的数据文件。在聊天中点击“+”按钮附加您的文件,或者拖放它们。
- ChatGPT 分析数据:ChatGPT 使用Python环境处理数据。它使用众所周知的Python库,如Pandas 进行数据处理和Matplotlib用于创建可视化。
- 提供说明:使用自然语言提供说明。您可以要求ChatGPT清理数据,创建特定图表或运行分析,而无需编写代码。
- 实时结果:ChatGPT将您的指令转换为Python脚本,运行代码,并以易于访问的格式(如表格、图表或统计摘要)呈现结果。
为了获得最佳结果,请确保使用结构化数据,行和列必须正确标记。在第二行添加每个变量的描述可以帮助 ChatGPT 更好地理解您的数据集,从而提高分析质量(尽管这并非必需)。
迭代分析
在数据分析中使用ChatGPT最好的部分是它是迭代的。一旦你得到了初始输出,比如图表或摘要,你可以立即进行调整。想要在图表中添加更多国家?改变颜色?添加新的注释?只需询问!您将实时看到所做的更改,这使得探索数据变得简单而高效。
让我们从实际示例开始。
数据集
在这个练习中,我们将使用最新的世界幸福报告中涵盖了2008年至2022年国家幸福水平趋势的数据集 [在这里下载数据]。
点击聊天窗口中的按钮(左下角),上传幸福数据文件(或者直接拖拽文件)。
现在您已经准备好使用简单的自然语言提示与数据进行交互。
数据集概览
如果您对数据集不熟悉,您可以开始探索其结构。您可以让ChatGPT读取数据,描述数据,清理空值并转换数据。我们的数据集已经是期望的格式,但有一些缺失的观测值,因此我们可以让ChatGPT将其删除。以下是一些示例提示,可以帮助您开始。
请分析数据文件并描述所有变量。
展示数据集的前几行。
生成汇总统计表,显示数据集中每个变量的均值、标准偏差和观察数量。
生成幸福、人均 GDP 和预期寿命的直方图,以了解它们在所有国家之间的分布情况。
以下是一些结果。ChatGPT描述了变量并创建了一些直方图。

颜色方案
ChatGPT使用Python代码来生成可视化内容。这个过程可能有些随机。因此,如果您希望生成一致的图表,选择一个颜色方案可能会有帮助。以下是一些您可以使用的颜色映射表。我将在下面的示例中使用其中一些颜色方案。

或者您可以将它们进一步切分。这是将谱色彩图切分为5个部分(下面附有一些十六进制代码)。

‘#5cb7aa’, ‘#97d5a4’, ‘#fff1a8’, ‘#fa9b58’, ‘#ee6445’.
准确性注意事项
检查输出的准确性非常重要。尽管这个系统比大多数人都先进(并且更好),但它可能产生误导性的输出。要求ChatGPT逐步工作,解释输出,并仔细检查工作是迫使其产生更准确输出的好方法。
此外,您可以单击“显示工作”以查看系统用于生成结果的底层Python代码。这样可以让您看到系统生成输出所需的所有步骤。您还可以要求系统为您提供可下载的程序文件或者经过新转换和清理的数据集。
时间序列分析
好的,让我们先来看一下随时间变化的快乐趋势。
全球幸福
首先,让我们看一下随着时间推移全球幸福感的变化。请注意,数据集中没有衡量全球幸福感的变量。GPT-4将自动完成此任务,然后创建图表。
绘制一条线图,显示从2008年到2022年的全球平均幸福感,使用一条趋势线突出整体变化。使用以下颜色表示幸福线:#5cb7aa & 趋势线使用此颜色:#ee6445。确保从2008年开始。
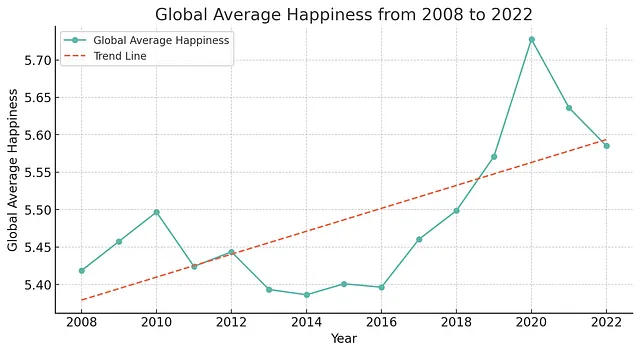
有一点幸福感从2016年到2020年有所增加,然后有所下降,可能是由于新冠疫情引起的。但总体趋势是积极的。
接下来,让我们来看看随着时间变化的一些特定国家的幸福趋势。
生成一幅折线图,展示从2008年到2022年美国、英国、保加利亚、阿富汗和芬兰的幸福感。为每个国家使用不同的颜色。具体来说,使用光谱色的颜色方案,选用更加鲜明艳丽的颜色。
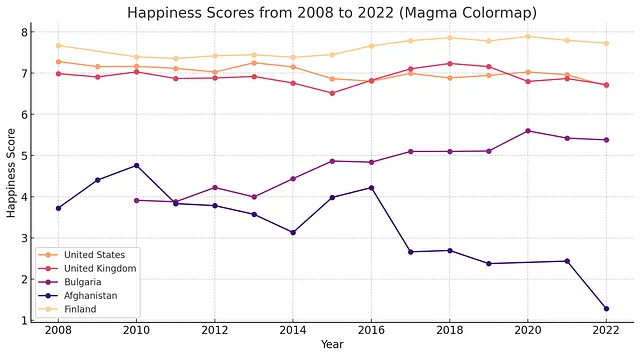
随着时间的推移
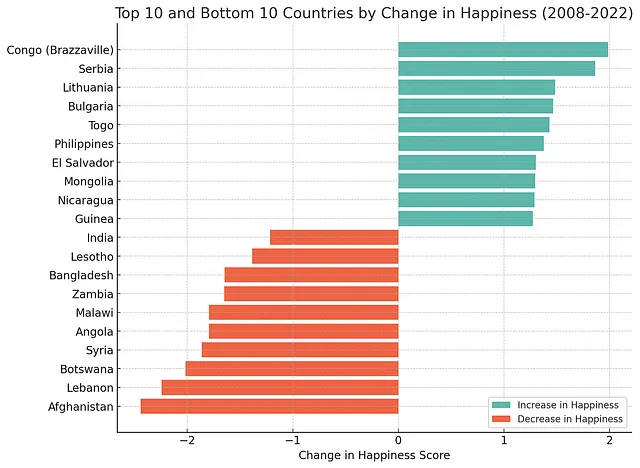
接下来,我们将看看在同一时间段内经历了最大幸福变化的国家。
创建一个柱状图,显示从2008年到2022年幸福指数变化最大的国家。展示增幅和减幅最高的前10个和后10个国家。将幸福度增幅最高的国家放在图表顶部,幸福度减幅最高的国家放在底部。使用增幅的颜色(#5cb7aa)和减幅的颜色(#ee6445)。谢谢!
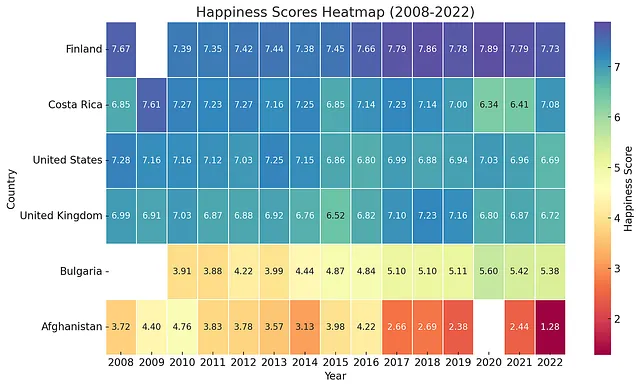
热力图表
我们甚至可以用热力图来表示特定国家的趋势。
生成一个热度图表,包括2008年至2022年的美国、阿富汗、哥斯达黎加、保加利亚和芬兰。将年份放在水平轴上,将国家放在垂直轴上。使用光谱色彩方案。将最幸福的国家放在顶部,不那么幸福的国家放在底部。谢谢!
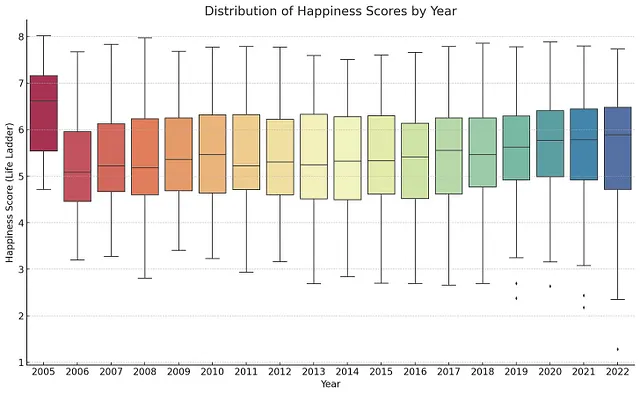
生成箱线图
我们还可以生成一个箱线图,这样可以让我们看到幸福得分随时间的分布,并帮助我们识别异常值。
生成箱线图来探索每年幸福分数的分布。使用彩色方案spectral。谢谢!
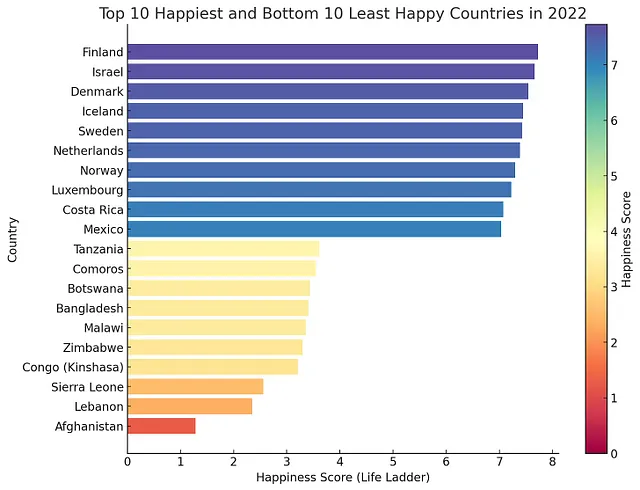
跨国分析
接下来,让我们来看看世界各地的幸福分布。
比较不同国家之间的幸福感
首先,我们将比较不同国家之间的幸福水平。
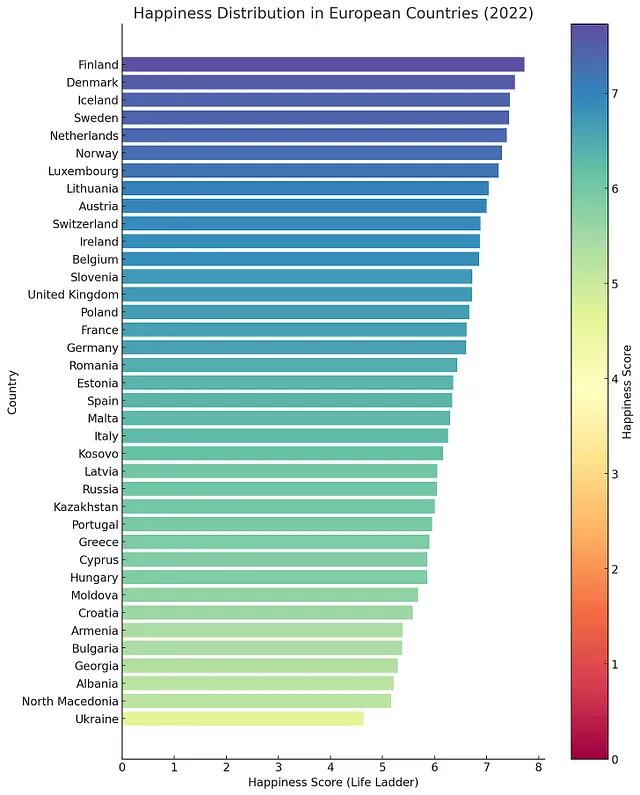
生成一个柱状图,显示2022年最幸福的前10个国家和最不幸福的前10个国家。将国家放在纵轴上,幸福水平放在横轴上。确保最幸福的国家在顶部,所有国家按降序排列(例如,最幸福的国家在图表的顶部,最不幸福的国家在底部)。使用色谱色彩方案。将图例放在图表的右侧。谢谢!
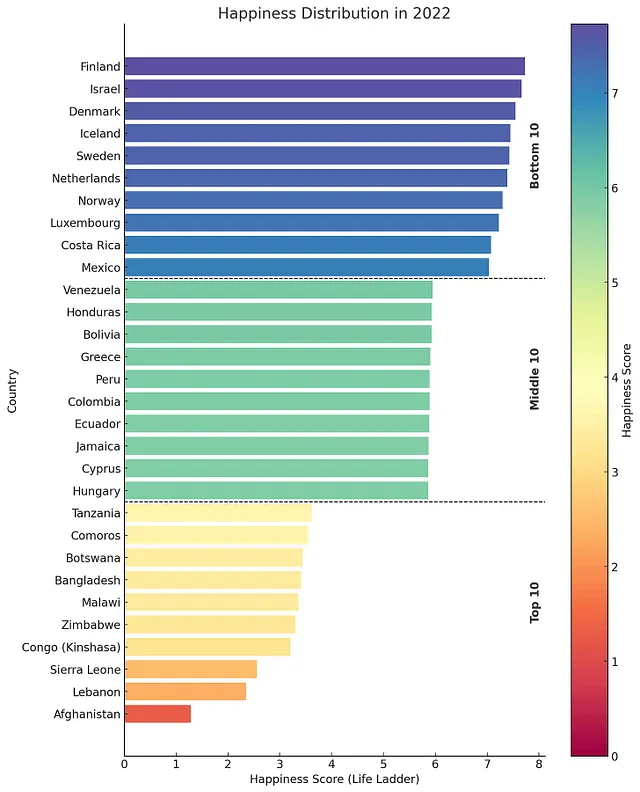
我决定请求ChatGPT将国家包括在幸福分布的中间,并添加虚线和标签以创建前10、中间10、后10的区分。经过几次提示,这是最终结果(完成此任务大约需要3分钟)。
你能为所有欧洲国家制作相同的图表吗?再次使用光谱色彩方案。谢谢!
生成专题地图
现在,让我们尝试在世界地图上可视化幸福。
请您创建一个2022年所有国家快乐水平的区域分布地图。
这是地图的第一版原型。

它无法与它使用的GeoJSON文件中的所有国家匹配。因此,我简单地要求它将国家与geoJSON数据集匹配,然后创建另一张地图,同时修正地图和图例以获得更好的比例。以下是地图的下一个版本。
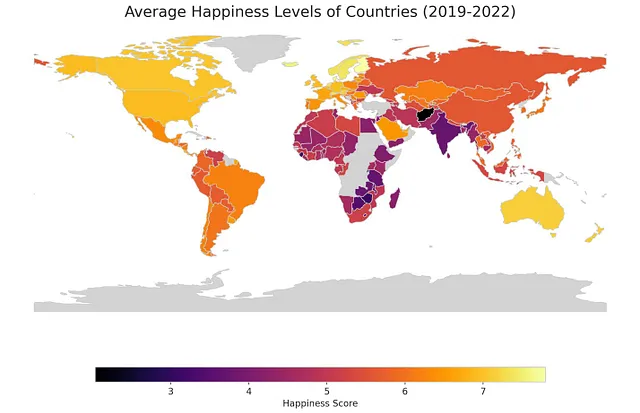
你也可以让ChatGPT创建一张显示幸福感随时间相对变化的地图。
很棒!现在你可以做另一张地图吗?你能分析2008年至2022年的数据,并创建一幅分级色彩地图,展示每个国家在此期间的变化情况(表现更开心还是更不开心)。请调整地图以考虑任何异常值。
创建一张蜘蛛图
我们甚至可以创意地要求ChatGPT为个别国家创建蜘蛛图,然后进行比较。
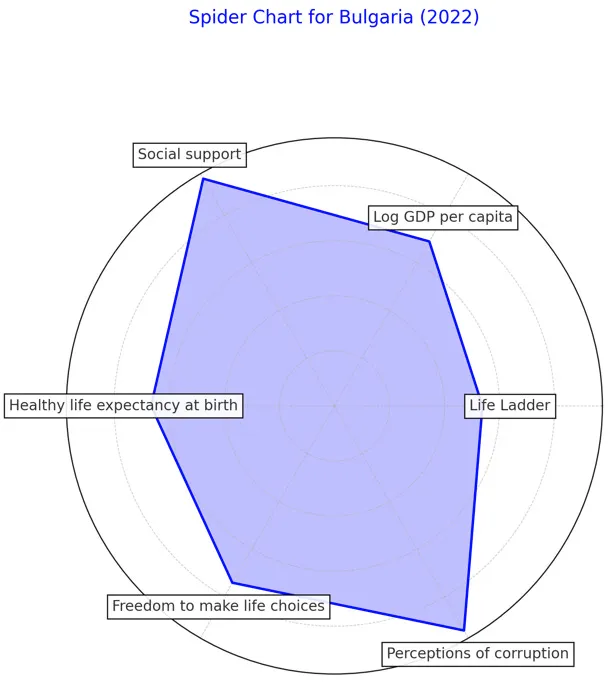
您能为2022年的保加利亚生成一个蜘蛛图吗?使用幸福、人均GDP对数、社会支持、健康预期寿命、自由选择权、对腐败的感知这些维度。标准化每个变量,使图表看起来更一致。使图表视觉上更具吸引力(并且看起来更现代)。使用彩色方案spectral。谢谢!
相关性和回归分析
接下来,我们将探讨不同变量之间的关系,并建立一个简单模型来了解幸福的决定因素。
探索金钱和幸福的关系
让我们创建一个散点图,以便我们可以可视化金钱和幸福之间的关系。
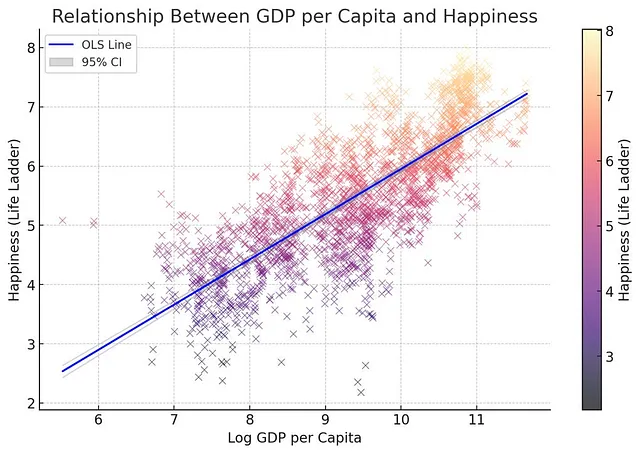
请你创建一个散点图,展示人均GDP和幸福之间的关系。为每个国家使用X(根据幸福水平不同颜色)。拟合OLS线显示95%置信区间,并在图表上显示出来。将置信区间设为浅灰色并适中的透明度。使用magma颜色方案。谢谢!
一个很酷的事情是,这个过程是迭代的。所以这里是同样的图表,采用不同的配色方案,只针对2022年。
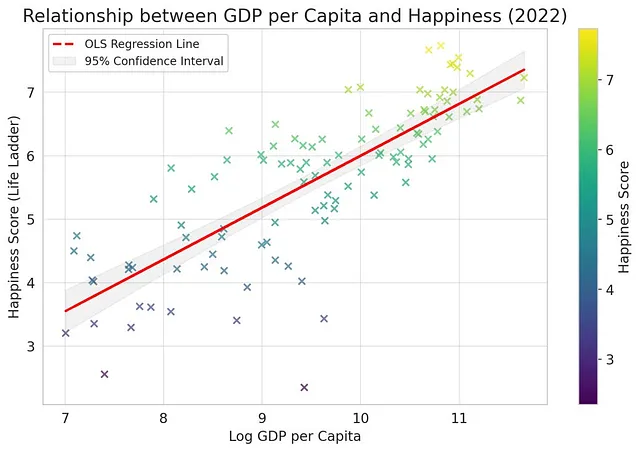
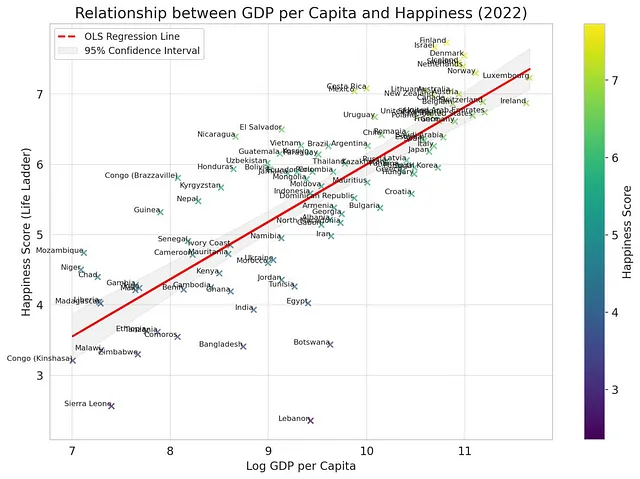
并添加国家名称。
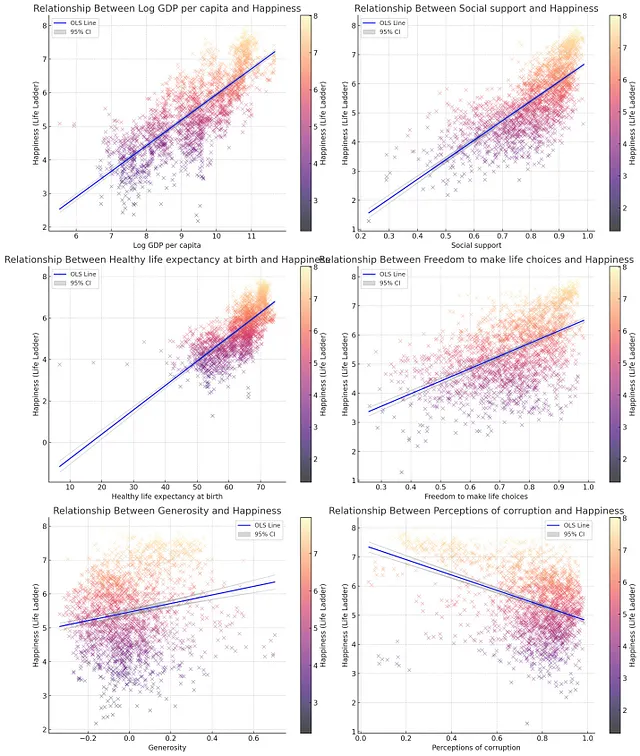
让我们也对数据集中的所有其他变量进行相同操作(人均 GDP、社会支持、健康预期寿命、自由选择、慷慨、腐败感知)。将所有图表合并为一个 2(列)x 3(行)的单个图。
运行线性回归模型
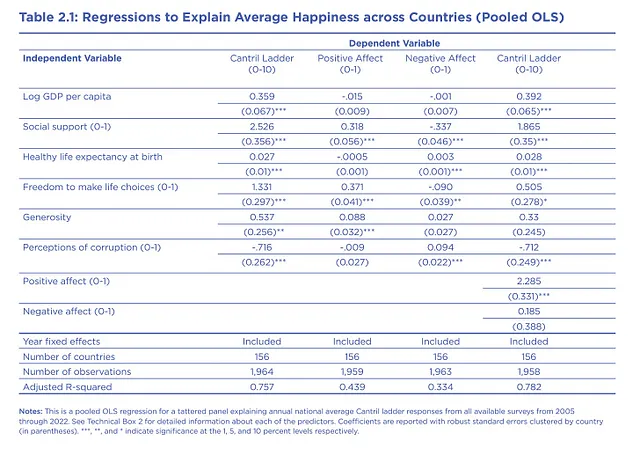
接下来,我们将从《世界幸福报告》中复制图2.1。
你能否进行池化OLS回归,从所有可用的调查中解释2022年的幸福感。将幸福感作为因变量,并将人均GDP对数、社会支持、健康预期寿命、自由选择、慷慨和腐败感知作为控制变量。包括年度固定效应。将所有系数报告在一个表格中,标题为:解释各国平均幸福感的回归。系数报告带有国家聚类的鲁棒标准误差(在括号中)。 ***, ** 和 * 分别表示显著性水平为1、5和10%。报告国家数量、观察次数和调整后的R平方值。谢谢!
以下是部分输出,与《世界幸福报告》中所示的图表相同。您也可以要求ChatGPT将结果导出到Excel文件中,或创建Latex表格,以便进一步编辑。重要的是它相当准确地复制了OLS模型。
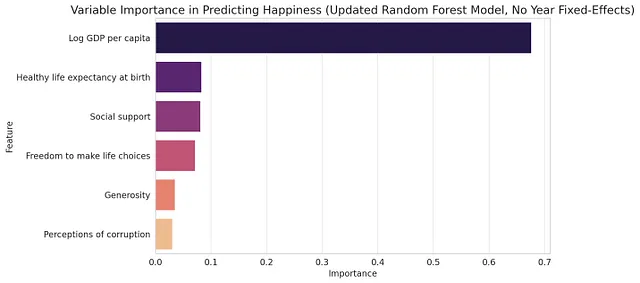
根据结果,在国家层面上,哪个因素对幸福感最重要?你是如何得出这个结论的?你能否创建一个显示每个变量对幸福感相对重要性的图表?排除年固定效应。使用色谱方案magma。
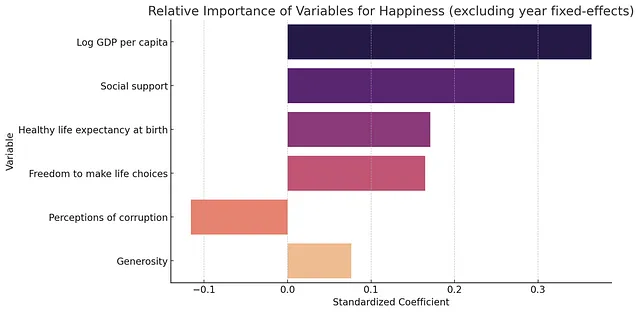
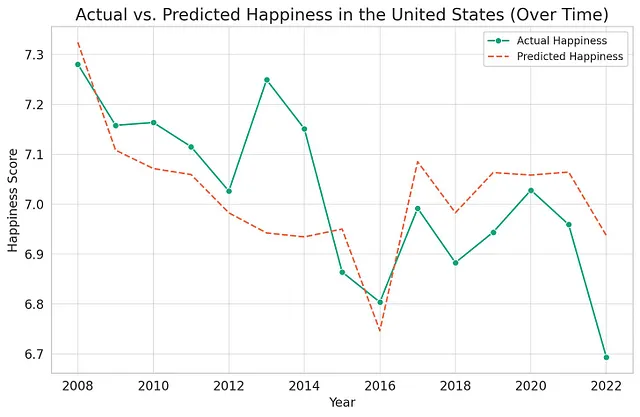
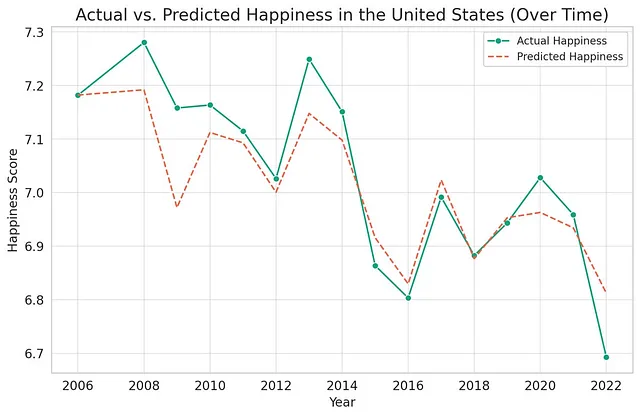
你能否以2022年的所有可用调查数据为基础,运行一个回归模型来解释幸福感?请将幸福感作为因变量,以对数人均GDP、社会支持、健康预期寿命、自由选择权、慷慨和腐败感知作为控制变量。请包括国家和年份固定效应。根据估计的模型,你能否为美国展示一个预测幸福感与实际幸福感的图表?谢谢!
潜在分析档案(高阶)
接下来,让我们尝试更高级的技术,比如潜在剖面分析(LPA),这是一种统计方法,用于基于观察变量在更大人群中识别子群或剖面。 LPA 假设人群中存在几个潜在的(未被观察到的)子群,每个子群中的人们具有共同特征,这些特征使他们与其他子群有所不同。
一个例子是研究大学生的情感健康。您可以测量抑郁、焦虑、自尊和生活满意度等变量。通过对这些变量的LPA分析,可能会识别出三种潜在的群体:一个“健康”群体,抑郁/焦虑程度低,自尊/生活满意度高;一个“中度困扰”群体,各个变量得分都居中;一个“痛苦”群体,抑郁/焦虑程度高,自尊/生活满意度低。这些群体代表着具有不同情感健康体验的学生子群,这些体验虽然不是直接测量的,但通过观察到的变量进行推断。
您可以应用LPA来识别具有不同偏好和行为的客户亚组,从而实现针对性营销策略。或者您可以检测出根据不同目标和风险承受力做出决策的投资者亚组,以支持金融咨询等。
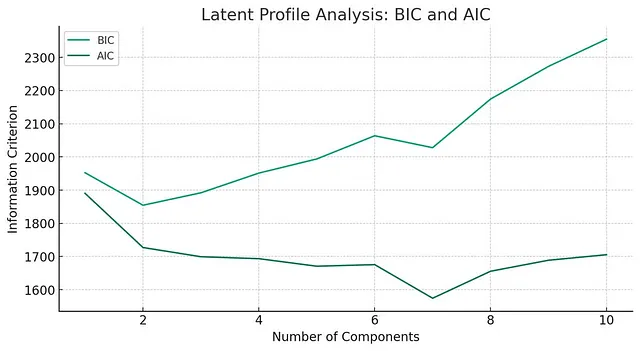
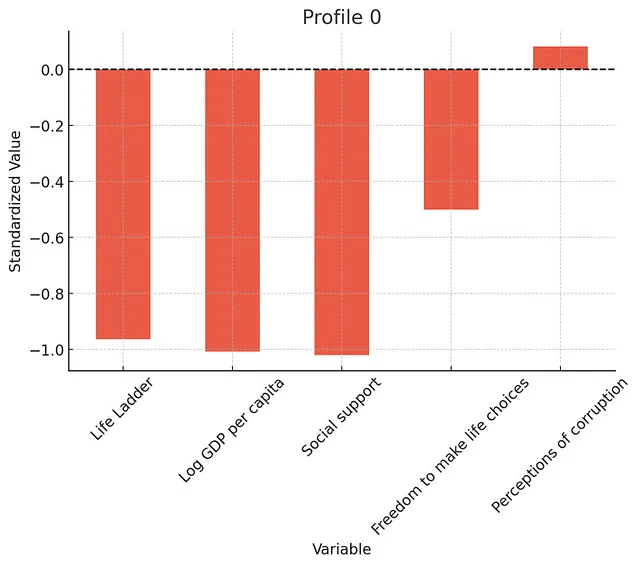
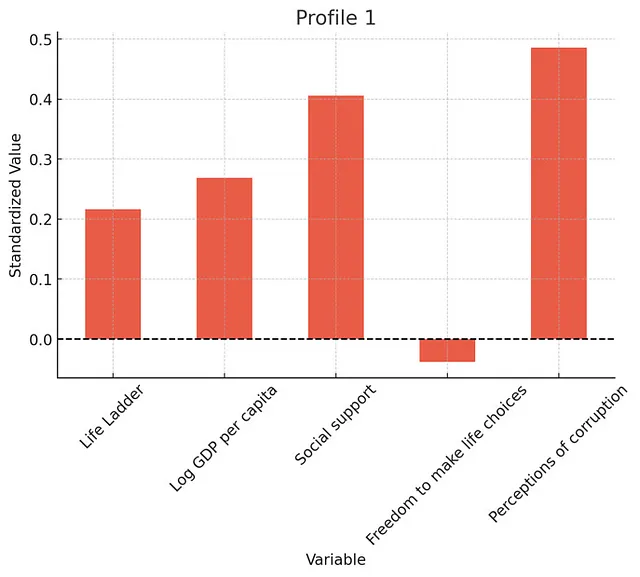
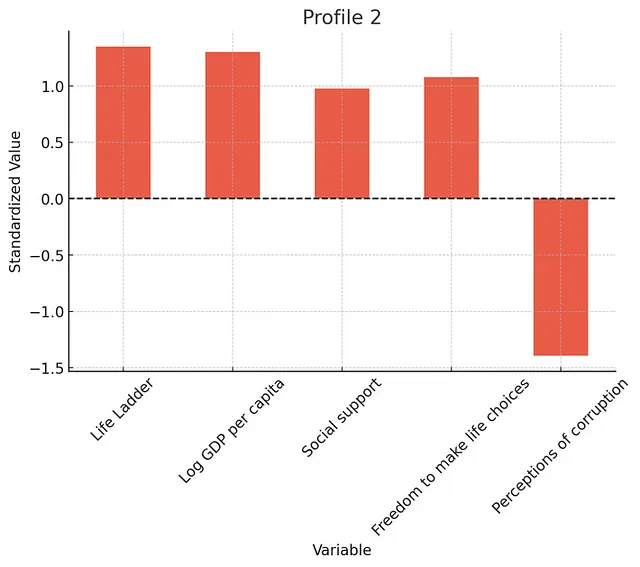
执行潜在分析(LPA),使用我们数据集中所有国家的幸福指数,人均GDP,社会支持,生活选择自由和腐败感知指数数据。目标是识别在这些变量上共享相同特征的国家群集。选择最佳潜在模型数量-在进行此操作时,模型的边际改进(展示一张图)。通过检查熵,平均潜在类概率和正确分类的几率验证生成的模型。报告每个特征的中心值(变量平均数)和分配给每个特征的国家数量。使用条形图可视化每个群集的特征,突出显示每个群集中每个因素的平均水平(在这里使用标准化值)。为每个特征创建单独的图表。为所有图表使用光谱色彩方案。深呼吸,逐步努力。谢谢!
ChatGPT选择了三个档案,这似乎是合理的(超过三个档案的收益仅微小)。
以下是个人资料的详细分析。国家并不是最适合LPA的应用,但是这个想法是您可以相对较好地进行此类探索性分析。
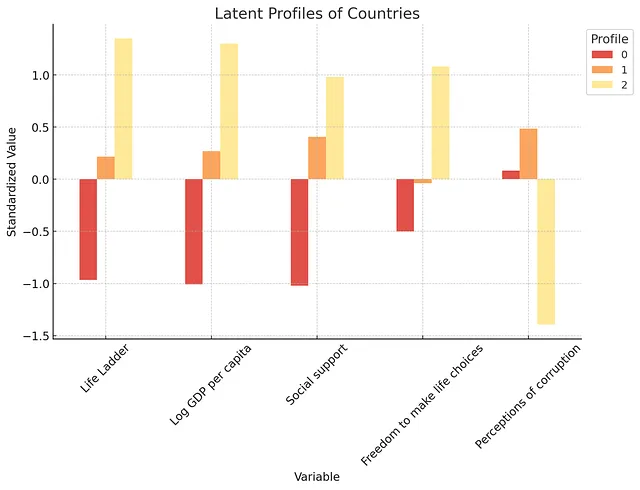
总体而言,分析发现了3个明显的档案。正如你所期望的那样,一个档案反映了较低的福祉和经济发展。另一个具有中等福祉和经济发展水平。最后一个则是具有高福祉和高经济发展水平(以及低腐败感知水平)。
机器学习(随机森林模型)
接下来,我们将使用一个基本的机器学习模型(随机森林)来预测幸福指数。这并不是详尽的描述,需要一些对该方法的基本理解,但是这能展示ChatGPT的能力。
训练一个随机森林模型来预测幸福感。预测因子应包括人均国内生产总值、社会支持、生活选择自由、腐败指数和年份固定效应。使用数据的70%进行训练,20%进行验证,10%用于测试模型性能。展示模型的表现情况。评估每个变量的重要性(展示具体因素的相对重要性图表)。完成分析不间断。根据需要做任何假设。
根据估计的模型,您能展示一个预测幸福感与实际幸福感对比的图表吗?谢谢!
交互式仪表盘(高级)
最后,我们甚至可以使用Python和Streamlit创建一个交互式仪表板来可视化数据集。
使用诸如Plotly、Dash或Streamlit之类的工具创建交互式网络应用程序。
· 包括各种类型的图表,并允许用户对数据进行过滤和交互。
· 将用户输入整合到动态更新的可视化中。
探索性数据分析
最后,即使您不知道从哪里开始,也可以简单地询问ChatGPT自行探索数据,找到一些有趣或反直觉的模式。它通常做得很好。
探索数据,寻找反直觉模式。
你能自己探索数据并寻找有趣的模式吗?如果有的话,有哪些违反直觉的观察?请提供一些可视化图表来帮助我理解你的发现。
希望本指南给你一些如何利用ChatGPT进行数据分析的好点子。ChatGPT并非完美,最好的使用案例是具有一定的数据分析背景,这样您可以对输出进行批判性评价。但是,有效使用时,它可以显著加快您的工作流程,提供新鲜见解,并有助于探索复杂数据集。要记住,结合您的专业知识与ChatGPT的功能,可以实现更高效且更有趣的数据分析。