ChatGPT是如何工作的?[详细分析和见解]
大型语言模型,GPT,LLM 参数,提示,注意力

如何成为AI、机器学习和生成性AI方面的专家权威?
我将于十月开始AI/ML直播课程,请提前预订您的座位。
你已经听过很多关于大型语言模型(LLMs)的噪音,其中之一是GPT。
GPT代表生成预训练变压器。
第一个变压器是谷歌的BERT(双向编码器来自变压器),但它没有类似人类的回应。
在2020年,GPT-3推出,比其他任何LLM都具有更好的回应。
你和我将深入探讨,并在ChatGPT周围建立我们的直觉。
为了了解它是如何运作的,让我们先了解它的其他技术部分。
让我们走吧!
究竟是什么是GPT(生成预训练变换器)?
我正在把一切都分解 -
- 生成的
- 预训练
- 变压器
生成的
“生成”一词源自统计学。
当我在读硕士时,有一门叫做统计建模的课程。
在统计建模中,你会发现生成建模的一个分支。
生成建模意味着根据先前的数字和概率生成/预测数字。
无论您生成图像还是文本,机器最终都是生成数字。
Pre-Trained 预训练
作为人类,你是如何学习的?
通常在基础知识之前不要马上跳到复杂的主题。
你首先学习国际象棋的基本步法,了解棋子的移动方式,进行练习,然后和其他玩家进行比赛。
同样,预训练模型也起作用。

您可以在基础任务上训练这些模型,并将它们用于优化复杂任务。
这些模型创建他们的记忆称为参数,这些参数基于它们从数据中学到的进行优化。
不必再次训练模型,您可以使用已经训练好的模型,并对其进行微调以适应您的特定用例。
要训练这些模型,你需要大量的数据。
GPT-3经过训练,使用包括Common Crawl,WebText2,Books1,Books2和维基百科在内的5个数据集中的大量文本。
这些数据集包含约五百万亿字,足以训练模型以理解单词之间的关系、语法、句子的构成,下一个单词将是什么等。
变压器
变压器是一种神经网络架构。
要与机器进行交流,你需要学习二进制语言。
以后,我们推出了一种编程语言,你可以学习Python并向机器发出指令。
但现在您可以直接用英语语言发出指令。
人类和机器之间的差距在缩小,您无需学习编程即可与机器互动。
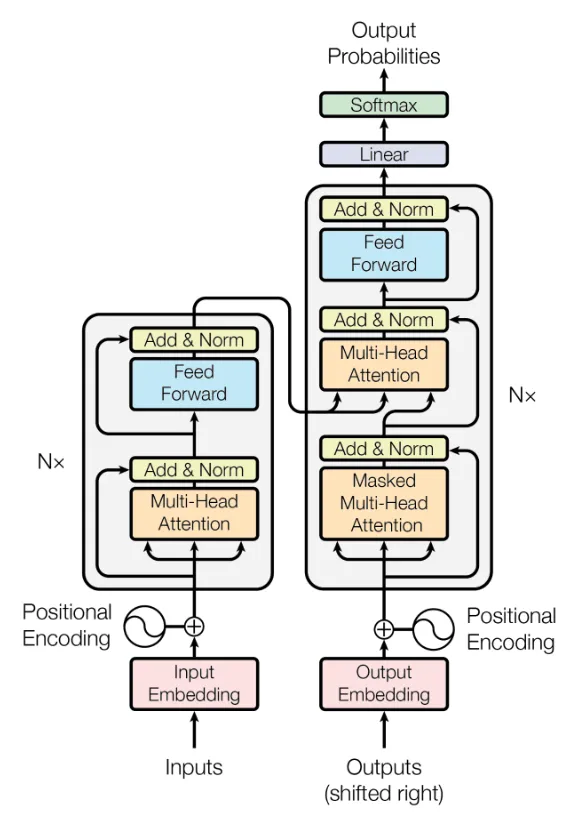
变压器是由谷歌研究人员在2017年的一篇名为“注意力就是一切”的研究论文中介绍的。
GPT是如何生成回复,并且与普通的Google搜索有何不同?
谷歌搜索是一种语义搜索,它根据用户查询的上下文、意图和关键词搜索数据库,并提供相关的结果。
您以可扫描的方式阅读文本,不是逐字记忆文本,而是只记住重要信息。
同样,语言模型只保留以参数形式表达的重要信息。
GPT-3是在前文提到的5个数据集的文本语料库中训练的,包含了5000亿个单词。
训练结束后,提取了1750亿个重要参数(参数可视为模型的记忆)。
当您查询大型语言模型时,它会根据参数(其内存)生成响应,而不是根据它训练的数据。
就像人类一样,如果我问你:“什么是电脑?”,你不会像教科书中逐字阅读定义那样回答,而是会以你理解“电脑”含义的方式回应。
LLM参数是什么?
每个参数影响模型对自然语言的理解。
由于LLM只是一个神经网络,它具有权重和偏差。
那就是参数的作用,权重会显示单词和短语之间的联系有多强。
偏差是作为模型对数据理解的起点的联系值。
它还包含了单词的数值嵌入的向量表示。
随着时间的推移,GPT会变得更好吗?
答案是:不。
你必须在新数据上再次训练模型。
这对语言模型来说是一个挑战,因为它只训练到了2022年3月的数据集,所以在当前日期获取不到回应。
每次您查询ChatGPT时,它都会将您的问题和其回复存储在数据库中,但GPT模型并不是通过这些用户互动不断学习并变得更好。
它是根据从庞大的5000亿令牌中生成的学习的1750亿参数为您提供响应。
GPT 是根据数据训练而成的,并创建了一个我们称之为参数的庞大复杂的 n 维矩阵。
类比 -
当我们作为人类学习东西时,我们试图获得所有可以分解成标记的信息(数据),然后我们创建我们的理解,并记住关于它的重要事情(参数)。
注意 — 为了让LLM与外部数据源连接,以更好地响应当前信息,您可以使用RAG策略。 (将在后续版本中介绍RAG)
ChatGPT 如何运作?

有171,476个单词在英语中,你可以为每个单词分配一个概率作为下一个句子“天空是......”。
具有最高概率的字词将赢得这个位置,在这种情况下是“蓝色”。
LLMs 不会随着时间改进,它们总是从头开始。
我们人类是如何想出“蓝色”这个词的?
我们已经多年阅读英语,我们不记得句子字字相对,但是我们理解短语、词语之间的关系以及我们的知识告诉我们答案下一个词将是“蓝色”。
什么是提示?为什么重要?
您输入到LLMs中的是提示。
为了获得更好的反应,您应该给出更好的提示。
您应该适应LLM的工作方式。
更清晰地定义提示,您将得到更好的回答。
因为LLM根据前一个单词预测下一个单词,您在提示中提供的单词越多,模型就会越容易找到单词之间的模式并生成更好的回复。
注意力机制
LLM在关注机制上进行工作。例如-
在这个句子中,“Himanshu”和“他”之间存在一种关系,作为人类,你理解在文本中,“他”是用于“Himanshu”的,这需要注意。
变压器可以将这些注意力信息保留在长文本中,这就是为什么在ChatGPT中你会看到在新的聊天中,如果你问一些你之前在聊天中提到过的事情,ChatGPT会知道你在谈论什么。
ChatGPT works forward, not backward. 聊天GPT向前工作,不向后。
无论何时,您提示ChatGPT时,它将生成下一个单词。
这只是一个实时的下一个词预测器。
让我们假设我输入了:“印度的首都是什么?”
ChatGPT 将回复:“印度的首都是……“
每次预测下一个单词时,该单词将成为输入序列的一部分。
ChatGPT如何生成类似人类的回复?
GPT-3是一个基础模型,它是在一个庞大的数据集上训练的。
基础模型的问题在于,它能够理解文本中的模式,并根据这些模式生成响应。
例如 -
如果你问2个这样的问题:
什么是印度的首都?什么是中国的首都?
它将检测模式并生成类似这样的响应:
什么是印度的首都? 什么是中国的首都? 什么是斯里兰卡的首都?
作为用户,您不希望得到这样的回应,如果您问了2个问题,您必须得到2个答案,而不是另一个问题。
这就是基础模型的问题。
为了解决这个问题,OpenAI 提出了一个指导手册。
他们对这份说明书中的基本模型进行了微调,就好像你问2个问题,就会得到2个答案。
他们雇用人手来手动标记最佳答复。
因此,
- ChatGPT 不知道任何东西。
- 它没有自我意识。
- 它没有意识。
为什么当我向ChatGPT提出同样的问题时,我会得到不同的回答?
当它生成下一个词时,关于主题的实际信息将是相同的,但句子的构成和模式会有所不同。
LLM 生成下一个单词的概率分布,每次这个分布都会不同。
ChatGPT 使用称为抽样的技术,通过概率方法生成响应。
非确定性概率分布抽样(表示可能有多个结果)。
从可能的下一个词的概率分布。
通过温度引入随机性(控制选择下一个单词时的随机程度)。
- LLMs 将永远从头开始
- LLMs不会随着使用而改善。
- 为了获得更好的回应,你必须适应LLM
结论
大型语言模型不会改变你的生活,它只是一种你要学习并继续前进的技术。
LLMs不是魔法,其中有一个技术部分。
这也不是你组织中所有问题的答案。
在某些商业场景下,机器学习会发挥最佳效果。
使用LLMs的时机是您需要了解的。
人工智能世界发展迅速,没有先发优势,而是快速行动的优势。
学得快,建设得快,赢得快,行动得快。
直到下次再见。
快乐的人工智能
预订人工智能,机器学习和生成式人工智能现场课程
解锁人工智能资源,免费课程和您的直播课程座位。
https://embeds.beehiiv.com/909363d2-9abc-4c70-a4f8-298eaebe9213