使用RAG/Gen AI和Selenium构建一个求职申请机器人
申请工作是一个漫长而繁琐的过程。最让我们感到厌烦的是重复性。然而,这种可预测性使其成为自动化的典型用例。如果我们的简历正在被人工智能扫描,为什么不使用人工智能来申请工作呢?
项目概述:
该项目的范围仅限于可以使用 LinkedIn 的 EasyApply 功能申请的工作。方法可以广义地分为两部分:
1. 与网页互动和自动化。
2. 一个动态查询引擎,用于回答有关申请人的任何问题。
Web交互由Selenium管理。查询引擎使用哈希和RAG的组合实现。然后将查询引擎打包成一个API,使用FastAPI在Uvicorn服务器上运行。
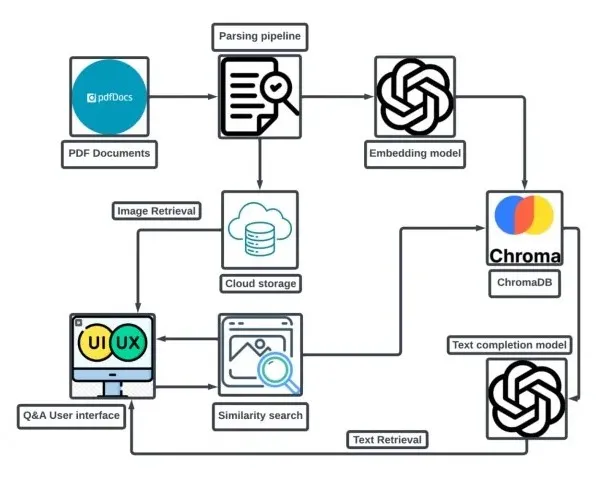
这里有一个流程图,可以提供项目的高层概述。

先决条件:
• Python 3, pip 软件包管理器,和 Jupyter Notebook。
• Ollama(用于本地推理)。您可以从这里下载它。如果您打算使用GPT,可以跳过此步骤。
在命令行中运行:
Ollama run phi3:3.8b-mini-4k-instruct-q4_K_M
• 对于本地推理,建议使用支持CUDA的GPU设备。
• 拥抱面孔和OpenAI API键(注意:OpenAI需要积分)。
请创建一个虚拟环境(推荐)以避免与当前的Python环境发生冲突,因为需要安装许多依赖项。
•WebDriver: 我使用了Edge的WebDriver,但任何流行浏览器的WebDriver都可以使用。
游戏攻略:
有了必要的工具和包,让我们一起来看代码和实现过程:
1. 使用Selenium进行网络交互和自动化
Selenium的功能对于搜索和与网页元素交互是直截了当的。真正的挑战在于管理动态网页元素并准确地预测下一步是什么。我通过将挑战分解为以下步骤来解决这个问题:
- 登录领英并搜索工作。
- 应用过滤器,如果过滤器没有结果,则重置它们。
- 应用程序有几种类型的元素。在审查多个应用程序后,这些元素可以被归类为单选按钮,复选框,单行文本字段,多行文本字段,自动填充文本字段和下拉菜单。每种输入类型都需要一个专门的函数来识别元素,检索相关问题的响应,并以兼容格式插入响应,比如填写文本或选择按钮。
- 一个应用函数,通过一个应用程序并使用之前定义的函数来实际填充应用程序。
- 一个迭代器函数,通过访问apply函数来循环浏览页面上的工作列表,同时也循环浏览搜索结果中的所有页面。
- 用于提交申请、关闭申请、跟踪进度状态、记录申请的工作和其他必要的小任务的特殊功能。
另外,我在操作之间增加了随机等待时间,以避免被LinkedIn的机器人检测系统标记。
为简洁起见,我没有包含自动化代码。可以在Git存储库中查看。
继续到较不无聊的部分。
2. 在应用程序中回答问题:
尽管求职申请表中的许多问题是重复的,但它们不能被推广到所有的申请表上(我尝试过),因为每份工作招聘信息都有其独特的要求和问题。
这可以通过结合对频繁重复问题的本地缓存和RAG系统来处理,来回答以前未遇到的问题。让我们首先看看缓存部分。
本地缓存使用哈希和模糊匹配:
尽管高级LLMs很强大,但没有什么能比得上O(1)搜索的简单。由于大多数重复性问题具有相同的措辞,它们可以作为键值对存储在JSON记录中,并通过简单的哈希搜索来访问。对于措辞相似但不完全相同的问题,可以将模糊匹配应用于JSON中键的列表,使用90%的匹配阈值来找到现有答案。尽管比直接哈希搜索慢,但由于其相对较低的计算复杂度,这种方法仍然比查询语言模型快。
模糊匹配是使用Levenshtein距离或最小编辑距离比较字符串的方法,这种方法衡量了将一个字符串转换为另一个字符串需要多少编辑。匹配的百分比是1 - (需要的编辑次数/两个字符串的最大长度)。可以使用fuzzywuzzy包来实现这种方法。与使用常规匹配比率不同,WRatio在给字符串评分之前对字符串执行转换,如小写化、按字母顺序对标记进行排序、将标记视为集合,这使得匹配更加稳健。
json 文件在每个应用程序后不断更新,更新后的文件会被提供给RAG系统。
def qna_engine(question):
questions_list = list(qna_dict.keys())
question = str(question)
if question in qna_dict:
answer = qna_dict[question]
else:
threshold = 90
matches = process.extract(question, questions_list, scorer=fuzz.WRatio, limit=3)
filtered_matches = [match for match in matches if match[1] >= threshold]
if not filtered_matches:
answer = rag_query(question)
qna_dict[question] = answer
else:
# Corrected to use the matched question string
matched_question = filtered_matches[0][0] # Get the actual question from the tuple
answer = qna_dict[matched_question]
print("THERE IS A MATCH")
return answer
如果上述方法没有产生结果,则将查询转交给RAG系统。
具有LlamaIndex的主动式RAG:
RAG(检索增强生成)结合了信息检索和文本生成。当查询被进行时,系统从文档存储或数据库中检索相关数据,通常是预先索引的。这些检索的数据作为上下文传递给语言模型,该模型使用查询和上下文来生成更准确和知情的响应。
为构建RAG模型,我使用了LlamaIndex,这是一个为构建基于LLM的应用程序而设计的开源框架。
以下是RAG工作流程的步骤:
数据准备和摄入:
输入数据集包括用户的pdf格式简历,包含常见问题及答案的Json文件,以及简历的详细版本的.txt文件。由于简历包含大量信息,语言模型可能会忽略部分信息。因此,简历被输入到GPT-3.5中,以生成更详细描述的详细版本。
然后使用LlamaIndex中的SimpleDirectoryReader软件包将数据摄取,该软件包可以获取给定目录中的所有文件,并处理大多数流行的文件格式。
文档被分割成更小的块,以便索引,并确保它们保持在LLM的令牌大小限制内。然后使用预训练嵌入模型将这些块转换为嵌入。这些嵌入被存储为索引数据库,使系统能够根据与查询的语义相似性检索相关的块。
docs = SimpleDirectoryReader(docs_path).load_data()
splitter = SentenceSplitter(chunk_size=1024)
documents = splitter.get_nodes_from_documents(docs)
使用 phi-3-mini-instruct 进行 RAG
要在本地实施RAG,选择只限于少数较小的LLM。 对于这种用例,使用的模型是微软的Phi-3-mini,它是一个拥有大约38亿个参数的小型高效模型。
该处使用的具体大语言模型(LLM)是phi3:3.8b-mini-4k-instruct-q4_K_M,通过Ollama包加载。该模型使用4位量化,使其在较小设备上运行效率高。所使用的嵌入模型是由HuggingFace提供的BAAI/bge-small-en-v1.5。
如前所述,首先,在摄入的数据上创建一个向量索引。可以使用as_query_engine()函数从向量索引创建查询引擎。索引可以存储在持久目录中供将来使用。响应可以通过提示工程来改善。LlamaIndex提供了覆盖默认系统提示的选项,这就是我所做的。
qa_prompt_tmpl_str_phi3 = """\
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge,
it is very important that you follow the instructions clearly and answer based on the given information.
Answer the query in the format requested in the query.
If there are options in the query, answer by choosing one or more options as required.
Try to read the document thoroughly to extract more info from the document.
When asked for city, return the city name along with the state.
Return only one answer, do not return multiple answers or list of answers unless specified.
For queries like "how many years of experience do you have with some tool", return just the integer.
For queries like "how many years of experience", the answer should always be an integer.
.
Keep the answers concise and to the point, do not answer long sentences unless necessary or specified.
Keep the answers concise. Answer in one or two words wherever possible. Keep the answers short, do not elaborate unless necessary, do not explain or elaborate.
Query: {query_str}
Answer: \
"""
phi3_llm = Ollama(
model="phi3:3.8b-mini-4k-instruct-q4_K_M",
temperature=0.01,
request_timeout=400,
system_prompt=system_prompt,
context_window=2000
)
phi3_embed = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en-v1.5")
splitter = SentenceSplitter(chunk_size=1024)
documents = splitter.get_nodes_from_documents(docs)
Settings.llm = phi3_llm
Settings.embed_model = phi3_embed
if check_persist(vector_index_dir):
storage_context = StorageContext.from_defaults(persist_dir=vector_index_dir)
vector_index = load_index_from_storage(storage_context)
else:
vector_index = VectorStoreIndex(documents)
vector_index.storage_context.persist(vector_index_dir)
vector_query_engine = vector_index.as_query_engine(response_mode='compact', use_async=True)
qa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str_phi3)
vector_query_engine.update_prompts({"response_synthesizer:text_qa_template": qa_prompt_tmpl})
Phi-3-mini在简短的问题和答案方面表现得很好,但在长篇摘要式问题方面表现不佳。对于这些任务,我们可以使用基于GPT-3.5-turbo的额外RAG模型。这两个模型可以结合在一起用于一个主动型RAG系统。
RAG使用GPT-3.5-turbo:
这个设置类似于phi-3-mini设置。这里使用的LLM是GPT-3.5-turbo,嵌入模型是text-embedding-ada-002,两者都可以通过OpenAI包访问。我们生成一个SummaryIndex,它可以访问每个查询的整个数据集,适用于长篇回答。与之前的模型类似,可以从SummaryIndex创建一个查询引擎。默认提示被覆盖以提供更具体的上下文,提高模型的性能。
gpt3_5_llm = OpenAI(model="gpt-3.5-turbo")
gpt3_5_embed = OpenAIEmbedding(model="text-embedding-ada-002")
Settings.llm = gpt3_5_llm
Settings.embed_model = gpt3_5_embed
if check_persist(summary_index_dir):
storage_context = StorageContext.from_defaults(persist_dir=summary_index_dir)
summary_index = load_index_from_storage(storage_context)
else:
summary_index = SummaryIndex(documents)
summary_index.storage_context.persist(summary_index_dir)
summary_query_engine = summary_index.as_query_engine(response_mode="refine", use_async=True)
qa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str_gpt4)
summary_query_engine.update_prompts({"response_synthesizer:text_qa_template": qa_prompt_tmpl})
结合两个RAG模型;AgentRAG:
一个主动型的RAG模型指的是一个整合了可以自动做出决策的代理的RAG系统。这些决定在检索和生成过程中引导模型的行为。在这种情况下,代理被用来确定根据问题将查询路由到phi-3-mini模型还是GPT-3.5模型。
代理可以使用LlamaIndex的RouterQueryEngine模块来实现,它使用LLM (在这种情况下是GPT-3.5) 来路由查询。为此,各个RAG模型 — phi-3-mini 和 GPT-3.5 — 必须被打包为查询引擎工具,并集成到RouterQueryEngine中。路由器可以配置为同时使用一个或两个模型。然而,由于大多数工作申请问题都很直接,一次只使用一个模型就足够了。
summary_tool = QueryEngineTool.from_defaults(
name="coverletter_tool",
query_engine=summary_query_engine,
description="for long answer and summary based questions about the profile"
)
vector_tool = QueryEngineTool.from_defaults(
name="vector_tool",
query_engine=vector_query_engine,
description="Useful for retrieving specific context from the documents."
)
docs = SimpleDirectoryReader(docs_path).load_data()
# Get the summarization and vector tools
summary_tool = get_summary_tool(docs)
vector_tool = get_vector_tool(docs)
# Now you can use summary_tool and vector_tool for your queries
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[summary_tool, vector_tool],
verbose=True
)这个模型需要在后台运行,并且可以被代码的自动化部分访问。最好的方法是将其打包成一个API,并将API端点提供给自动化部分。
使用FastAPI和Uvicorn将模型打包成API:
模型通过FastAPI框架封装为API,并使用Uvicorn服务器在本地托管。
@app.post("/resume_qa", response_model=QueryResponse)
async def generate_text(request: QueryRequest):
query = request.query
try:
response = query_engine.query(query)
formatted_response = str(response.response)
print(formatted_response)
return QueryResponse(response=formatted_response)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
# Optional: Health check endpoint
@app.get("/health")
async def health_check():
return {"status": "ok"}
# Run the application using Uvicorn
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
API 可以使用 requests 包访问。
def rag_query(query):
url = "http://127.0.0.1:8000/resume_qa"
payload = {"query": query}
response = requests.post(url, json=payload)
return response.json().get('response')
这是一个测试运行:
启动服务器:
运行示例查询:

运行整个东西:
首先我们使用以下命令启动API。
uvicorn filename:app --reload
一旦 API 上线,运行自动化脚本。它应该能够在一分钟内开始工作并申请工作。
open_linkedin_and_signin()
job_search_and_filters()
time.sleep(3)
iterator(driver)
您可以在这里找到代码库: