英伟达大胆之举:开放性AI模型有望与GPT-4竞争

Nvidia在人工智能领域取得了显著的进步,发布了NVLM 1.0,这是一组大型多模态语言模型(LLMs),旨在与OpenAI和Google等行业巨头竞争。领导此次发布的是NVLM-D-72B,这是一个拥有720亿参数的模型,能够在视觉和文本任务中提供一流性能。
这次开源发布标志着人工智能开发领域的转变。通过提供模型权重的公开访问,并承诺发布训练代码,Nvidia正在为研究人员和开发人员提供实验最前沿技术的机会。NVLM 1.0 发布不仅展示了Nvidia在人工智能方面的能力,也表明公司致力于促进更具协作性的人工智能生态系统。
什么使NVLM 1.0独特?
NVLM 1.0被设计用来突破边界,尤其在视觉-语言任务中表现得非常出色。NVLM-D-72B与其他模型不同的地方在于,在训练后能够增强多模态和仅文本任务的能力。许多同类模型在进行视觉-语言任务训练时面临文本表现下降的问题,但NVLM-D-72B通过在平均4.3分的文本基准测试中提高准确性打破了这一趋势。
这种性能飞跃在多个领域显而易见,比如图像解释,模因分析,甚至逐步解决复杂数学问题。通过展示在视觉和文本输入方面的多种用途,NVLM-D-72B被定位为人工智能研究中的改变者。
NVLM 1.0的主要特点
- 多模式功能:NVLM 1.0可以无缝地集成文本和视觉数据。它能够解释图像,理解复杂的表情包,以及逐步解决数学问题。
- 文本任务性能提升:与许多模型不同,NVLM-D-72B在多模态训练后提高了在仅文本任务上的性能,各项主要基准上提高了4.3个点。
- 开源倡议:通过公开模型权重并承诺发布训练代码,英伟达为更广泛的人工智能社区打开了创新先进技术的大门。
- 基准领导力:NVLM-D-72B与顶级专有模型如GPT-4o、Llama 3.1(405B)和Gemini展开激烈竞争,在视觉语言和仅文本任务上表现出色。
NVLM-D-72B: 一个多才多艺的表演者
NVLM-D-72B之所以脱颖而出,是因为它具有720亿参数,并且能够高效地处理复杂的视觉和文本输入。它在诸如以下任务中展示出令人印象深刻的表现。
- 解读Meme:分析图像和视觉幽默。
- 解决数学问题:逐步分解解决方案。
- 视觉语言任务:例如图像分析和视觉问答等任务,极大地受益于该模型的多模态架构。
NVLM-D-72B相比其先前版本和其他模型在仅限文本的基准测试中表现出改进,如数学和编码,在需要逻辑推理的任务上甚至超过了一些较大的模型。
编码和部署:开发人员的NVLM 1.0
NVLM 1.0专为开发者社区量身定制,为他们提供资源来根据自己的需求实施、测试和修改模型。英伟达决定将这个模型开源意味着开发者现在可以获得无与伦比的接触状态最先进的工具,与甚至是最大的专有模型竞争。
设置和环境准备
英伟达提供了一个Dockerfile,方便设置,让您能够重新创建环境以进行有效的训练和推理。
Dockerfile 设置:
# Use Nvidia's PyTorch Docker image
FROM nvcr.io/nvidia/pytorch:23.09-py3
# Install necessary packages
RUN pip install transformers datasets accelerate
# Install additional requirements for NVLM
RUN apt-get update && apt-get install -y ffmpeg libsm6 libxext6
这让您可以快速搭建一个为NVLM-D-72B训练和推理优化的环境。
加载模型
利用Huggingface的transformers库,您可以使用以下代码加载NVLM-D-72B模型:
import torch
from transformers import AutoModel
path = "nvidia/NVLM-D-72B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=False,
trust_remote_code=True
).eval()
这将使用Huggingface框架在评估模式下初始化模型,具有较低的内存使用率,并优化了多GPU推断。
多模式图像和文本推理
NVLM-D-72B可以处理涉及文本和图像的多模式任务。以下是如何加载图像并运行推断的示例:
from PIL import Image
import torchvision.transforms as T
import torch
from transformers import AutoTokenizer
# Load and preprocess the image
image = Image.open("example_image.jpg").convert('RGB')
transform = T.Compose([T.Resize((448, 448)), T.ToTensor()])
image_tensor = transform(image).unsqueeze(0).to(torch.bfloat16)
# Load tokenizer and prepare text prompt
tokenizer = AutoTokenizer.from_pretrained("nvidia/NVLM-D-72B", trust_remote_code=True)
question = "<image> Please describe the image."
# Run inference
response = model.chat(tokenizer, image_tensor, question, dict(max_new_tokens=1024, do_sample=False))
print(response)
这段代码演示了如何利用NVLM-D-72B来进行多模态任务,接受图像作为输入并生成相关的文本描述。
数学和编码任务
NVLM 1.0在数学和编码任务方面表现出色,优于其他模型,如Llama 3.2和GPT-4o。它能够理解并解决复杂问题:
question = "Solve the equation: 3x + 5 = 20."
response = model.chat(tokenizer, None, question, dict(max_new_tokens=512))
print(f"Solution: {response}")
该模型展示精准解决数学问题的能力,经常提供逐步解决方案。此外,它在编码基准测试中表现出色,使其成为诸如代码生成、调试和算法问题解决等任务的有价值工具。
基准结果和模型性能
Nvidia的NVLM 1.0在各种多模态基准测试中实现了最先进的性能。
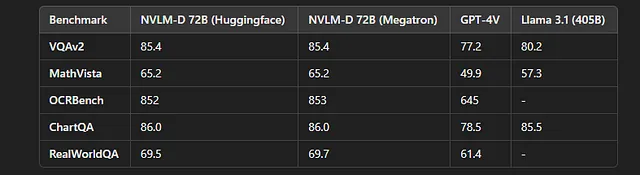
NVLM 1.0在视觉-语言任务方面的表现与顶级专有模型媲美,同时在传统的纯文本任务如数学和编码方面表现出色。
结论:NVLM 1.0 — 人工智能研究的改变者
Nvidia发布NVLM 1.0标志着人工智能领域的一个变革时刻。通过将这个强大的多模态模型开源,Nvidia向其他科技巨头发出了挑战,可能改变了人工智能模型的开发、共享和使用方式。
这种开源方法可能会加快AI研究的进展,并更公平地访问尖端技术,使较小的组织和独立研究者能够以重要的方式做出贡献。
然而,随着更大的可访问性,也带来了更大的责任。人工智能社区需要建立道德准则,以确保这些工具被负责任地使用,并确保它们所带来的创新与社会价值观一致。
随着NVLM 1.0的发展和扩展,我们将看到英伟达的大胆举措如何影响人工智能研究和更广泛的科技行业,可能引领人工智能领域的开放、合作性进步时代的到来。
喜欢这篇文章吗?如果你觉得它有帮助,请为它鼓掌,别忘了关注KagglePro获取更多有见地的更新和技巧!您的支持帮助保持社区充满活力,并充满优质内容。
阅读Kagglepro LLC更多内容