使用微调的OpenAI模型为Oracle APEX开发创建我自己的专业ChatGPT
作为与Oracle APEX一起工作的开发人员,保持对最新功能和增强功能的更新对于构建可扩展和安全的应用程序至关重要。虽然像ChatGPT这样的工具对编码辅助已经变得非常宝贵,但我经常发现它对特定技术的了解可能落后于最新的更新。特别是在发布具有我想要在开发工作流程中利用的关键功能的新版本时,这一点尤为真实。
Oracle APEX 24.1介绍了一系列新的功能,包括增强的人工智能集成、JSON关系二元性和高级数据可视化。然而,当我使用ChatGPT来帮助解决这些特定功能时,我有时会收到反映过时版本的信息。因此,我意识到需要使用最新的文档来微调模型,以确保在开发过程中AI能够提供准确、相关的回应。
在这篇文章中,我将带领您通过使用数据科学在Oracle云基础设施中微调OpenAI模型与Oracle APEX 24.1终端用户指南的旅程(但您也可以在任何代码编辑器中本地运行它)。目标是创建一个专门针对Oracle APEX开发的高度专业化的AI助手,这样我就可以提出关于最新功能的问题,并获得最新详细的回答。如果您曾经发现自己需要精确的、特定版本的编码帮助,这篇指南将向您展示如何为任务定制您的AI工具。
准备数据
微调模型:使用Python为GPT-4结构化Oracle APEX数据
在为微调语言模型准备数据时,数据格式在确保模型能够有效学习方面扮演着至关重要的角色。OpenAI 模型需要特定的结构,包括提示-响应对,体现真实世界的互动。在微调模型以解决特定领域任务(比如解释Oracle APEX概念)时,这种结构特别有用。
为什么需要这种格式进行微调?
OpenAI的微调过程依赖于结构化数据,其中用户与助手之间的每一次互动都以统一的方式表示。JSONL格式使得结构化学习成为可能,因为:
- 基于角色的学习: “用户”角色教导模型如何解释提示,而“助手”角色则指导如何回应。
- 一致性:这确保模型从模仿真实世界使用的互动中学习。模型会期望用户提问并学习提供适当的回答,就像真实的对话一样。
- 灵活性:JSONL 格式很灵活,允许我们在每次互动中包含元数据或附加上下文,可以根据需要进行扩展。
这些结构化数据至关重要,因为它为诸如 GPT-4 这样的模型提供了必要的格式,以理解特定领域的语言(例如 Oracle APEX 术语)并生成准确的回复。
以下,我将解释将Oracle APEX最终用户指南转换为微调数据集的过程,以及为什么这种格式是必不可少的。
1.1. 将PDF转换为逐行数据
首先,我们需要以结构化的方式从Oracle APEX终端用户指南这个PDF文档中提取内容。由于数据存储在非文本格式(PDF)中,重要的是逐行阅读以便我们可以准确地捕获文档中的问题和答案。为了实现这一目标,代码会逐行读取PDF的每一行,并相应地拆分内容。
import PyPDF2
# Extract text from the PDF guide, line by line
def extract_text_by_line(pdf_path):
lines = []
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
for page in reader.pages:
text = page.extract_text()
lines.extend(text.splitlines()) # Split text into lines
return lines
这种方法确保我们捕捉到细节,比如包含提示(用户问题)和对应答案(助手回应)的具体行。通过将内容分割成单独的行,我们增加了从技术文档中创建准确问题-答案对的可能性。
1.2. 为微调结构化数据:提示-完成对。
一旦文本被提取出来,我们需要将其结构化为JSONL(JSON Lines)格式,这是OpenAI微调所需的格式。文档的每一行都被视为提示(问题)或完成(答案)。这就是微调数据的对话格式发挥作用的地方。

提示:双方第一行起到“用户”输入的作用,是一个问题。
- 完成:第二行作为“助手”回应,提供解释或答案。
通过这种方式组织数据,模型可以学习根据提供的内容回答有关Oracle APEX的问题。这确保了一旦经过良好调整,模型可以对平台上的特定用户查询进行响应。
1.3. 添加额外的例子
为补充从Oracle APEX文档中提取的数据,我们添加了额外的预定示例。这一步是至关重要的,因为它可以更好地控制模型将学习回答的问题类型。
# Add predefined examples
additional_examples = [
{"messages": [{"role": "user", "content": "What is Oracle APEX?"},
{"role": "assistant", "content": "Oracle APEX is a low-code development platform for building scalable, secure applications."}]},
{"messages": [{"role": "user", "content": "How do I create an application in Oracle APEX?"},
{"role": "assistant", "content": "In Oracle APEX, you can create applications using the App Builder wizard to define pages, data sources, and navigation."}]},
# Additional examples follow...
]
这样可以确保模型具有更全面的训练数据集,不仅反映了从文档中提取的内容,还包括可能不在文本中的自定义示例。
1.4. 保存数据以进行微调
在对数据进行结构化之后,它将以JSONL格式保存,这对在OpenAI平台上对模型进行微调是必要的。
# Save the structured data into JSONL format
def save_as_jsonl(examples, output_file):
with open(output_file, 'w') as f:
for example in examples:
json.dump(example, f)
f.write('\n')
# Save the dataset
output_file = "apex_finetune_data_end_users_guide_by_line.jsonl"
save_as_jsonl(fine_tuning_data, output_file)
2. 数据分析
2.1. 加载数据集
第一步是加载包含来自Oracle APEX终端用户指南的提取提示和完成的JSONL数据集。 JSONL文件中的每一行代表一个提示-完成对,将用于微调模型。
with open(data_path, 'r', encoding='utf-8') as f:
dataset = [json.loads(line) for line in f]
此脚本逐行读取JSONL文件,并将每一行转换为Python字典。数据集中的每个条目包含一组消息,其中包括用户提示和助手响应,这些将用作训练示例。
2.2. 初始数据集统计
在继续微调过程之前,我们需要检查数据集以了解其结构和内容。具体来说,我们想要检查有多少个示例,并打印出第一个示例,以确保数据提取已正确执行。
print("Num examples:", len(dataset))
print("First example:")
for message in dataset[0]["messages"]:
print(message)
- Num示例:这只是计算数据集中提示-完成对数的数量。在这种情况下,它显示了17个示例。
- 通过打印第一个示例,我们可以检查其内容。然而,在这种特殊情况下,第一个示例似乎包含了法律版权信息,而不是一个有用的提示-响应对。这表明在PDF提取过程中可能捕获了一些不必要的文本,这可能需要在调优之前过滤掉不相关的部分。
2.3. 格式错误检查
为了确保数据集符合微调所需的正确格式,我们进行了几次格式检查。这些检查有助于确认所有必需字段(例如角色和内容)是否存在,并且消息角色有效(用户,助手等)。
format_errors = defaultdict(int)
for ex in dataset:
if not isinstance(ex, dict):
format_errors["data_type"] += 1
continue
messages = ex.get("messages", None)
if not messages:
format_errors["missing_messages_list"] += 1
continue
for message in messages:
if "role" not in message or "content" not in message:
format_errors["message_missing_key"] += 1
if any(k not in ("role", "content", "name", "function_call", "weight") for k in message):
format_errors["message_unrecognized_key"] += 1
if message.get("role", None) not in ("system", "user", "assistant", "function"):
format_errors["unrecognized_role"] += 1
content = message.get("content", None)
function_call = message.get("function_call", None)
if (not content and not function_call) or not isinstance(content, str):
format_errors["missing_content"] += 1
if not any(message.get("role", None) == "assistant" for message in messages):
format_errors["example_missing_assistant_message"] += 1
if format_errors:
print("Found errors:")
for k, v in format_errors.items():
print(f"{k}: {v}")
else:
print("No errors found")
这个脚本执行以下检查:
- 确保数据集中的每个条目都是一个字典。
- 检查必需的键角色和内容是否存在。
- 验证每条消息都有有效的角色(例如用户、助手、系统)。
- 确保每一个提示完成对都有一个助手消息(以完成示例)。
结果:输出显示没有发现错误,这意味着数据集已经适当结构化以用于微调。
2.4. 令牌计数函数
接下来,我们需要通过计算每个示例(提示和响应)中的标记数量来分析数据集,以确保我们在OpenAI微调(每个示例16385个标记)的标记限制范围内。为此,我们使用tiktoken库,该库经过优化,适用于使用OpenAI模型进行标记计数。
encoding = tiktoken.get_encoding("cl100k_base")
# Token counting function
def num_tokens_from_messages(messages, tokens_per_message=3, tokens_per_name=1):
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3 # Bias for end of conversation
return num_tokens
此函数计算每条消息中的令牌数量。每条消息都被分配了3个令牌的偏差(用于消息开销),并根据内容添加额外的令牌。令牌计数至关重要,因为超出OpenAI的令牌限制可能会导致微调过程中出现错误或截断的示例。
要特别计算助手回应中使用的标记数,我们使用以下函数:
def num_assistant_tokens_from_messages(messages):
num_tokens = 0
for message in messages:
if message["role"] == "assistant":
num_tokens += len(encoding.encode(message["content"]))
return num_tokens
2.5. 消息和令牌的分发
在对数据集中的标记进行计数后,我们会计算并展示每个示例中消息和标记数量的分布情况。这有助于我们确定是否有任何示例过长或过短。
def print_distribution(values, name):
print(f"\n#### Distribution of {name}:")
print(f"min / max: {min(values)}, {max(values)}")
print(f"mean / median: {np.mean(values)}, {np.median(values)}")
print(f"p5 / p95: {np.quantile(values, 0.05)}, {np.quantile(values, 0.95)}")
此功能打印出给定令牌或消息计数的最小值、最大值、平均值和中位数,以及第5和第95百分位数值。这提供了关于是否有任何示例在长度方面是离群值的见解。
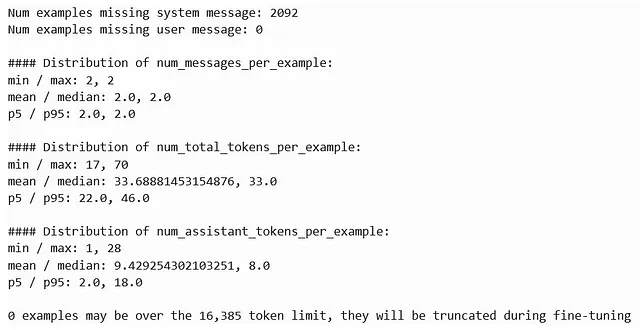
输出提供了您微调数据集的摘要,显示:
- 2092 个示例缺少系统消息(不是关键消息,但提供信息)。
- 0个例子缺少用户提示,这意味着所有条目都有有效的用户输入。
- 每个示例都包含2条信息(用户提示和助手回应)。
- 每个示例的令牌计数范围在17到70个令牌之间,平均为33.69个令牌,远远低于16385个令牌的微调限制。
- 助手回答包含1到28个标记,平均为9.42个标记,使数据集简洁高效。
总的来说,数据集结构良好,没有标记截断问题,已经准备好进行微调。
2.6. 价格和默认时代估计
接下来,我们根据数据集中的标记数量来估算训练的定价和默认时代。OpenAI的微调成本是基于训练期间处理的标记总数,所以计算我们将被计费的标记的数量是非常重要的。
MAX_TOKENS_PER_EXAMPLE = 16385
TARGET_EPOCHS = 3
MIN_TARGET_EXAMPLES = 100
MAX_TARGET_EXAMPLES = 25000
MIN_DEFAULT_EPOCHS = 1
MAX_DEFAULT_EPOCHS = 25
n_epochs = TARGET_EPOCHS
n_train_examples = len(dataset)
if n_train_examples * TARGET_EPOCHS < MIN_TARGET_EXAMPLES:
n_epochs = min(MAX_DEFAULT_EPOCHS, MIN_TARGET_EXAMPLES // n_train_examples)
elif n_train_examples * TARGET_EPOCHS > MAX_TARGET_EXAMPLES:
n_epochs = max(MIN_DEFAULT_EPOCHS, MAX_TARGET_EXAMPLES // n_train_examples)
n_billing_tokens_in_dataset = sum(min(MAX_TOKENS_PER_EXAMPLE, length) for length in convo_lens)
print(f"Dataset has ~{n_billing_tokens_in_dataset} tokens that will be charged for during training")
print(f"By default, you'll train for {n_epochs} epochs on this dataset")
print(f"By default, you'll be charged for ~{n_epochs * n_billing_tokens_in_dataset} tokens")

在这个计算中:
- 默认的训练周期:它计算出我们将训练5个周期。
- 计费令牌:该数据集包含大约70,477个令牌,这意味着在微调期间我们将被收费约211,431个令牌。
3. 调整OpenAI模型
一旦数据准备好并分析完成,让我们继续进行微调过程。这是在运行在 Oracle Cloud Infrastructure(OCI)上的数据科学笔记本中使用 OpenAI API 完成的。OCI提供了一个无缝的环境来运行基于Python的机器学习工作负载,使其成为微调诸如 GPT-4 等大型模型的理想平台。
微调过程通过将准备好的数据集上传到OpenAI开始:
from openai import OpenAI
# Initialize OpenAI client
client = OpenAI(api_key='your-api-key') # Replace with your actual API key
# Upload your fine-tune dataset
response = client.files.create(
file=open("apex_finetune_data_end_users_guide_by_line.jsonl", "rb"),
purpose="fine-tune"
)
# Check the response to confirm the file upload
print(response)
- 初始化客户端:使用您的API密钥连接到OpenAI。
- 上传数据集:上传文件“apex_finetune_data_end_users_guide_by_line.jsonl”,并指定其用途为“微调”。
- 确认上传:响应确认文件上传并提供文件ID,以用于微调的下一步。
让我们用OpenAI的Python API进行微调作业的初始化。
# Retrieve file ID from the response
file_id = response.id
print(file_id)
# Step 2: Start the fine-tuning job
fine_tune_job = client.fine_tuning.jobs.create(
training_file=file_id, # Use the uploaded file ID
model="gpt-4o-2024-08-06", # Use a valid model for fine-tuning
hyperparameters={
"batch_size": 8, # Start with a batch size of 8 for a medium dataset
"learning_rate_multiplier": 0.05, # Slightly lower learning rate to prevent overwriting base model knowledge
"n_epochs": 4 # 4 epochs to start with, monitor the results and adjust if necessary
},
suffix="apex-tuned-model-08-10-changed-parameters"
)
# Check the response to monitor the job
print(fine_tune_job)
上传您的训练数据(apex_finetune_data_end_users_guide_by_line.jsonl)后,此行检索并打印文件ID。该ID在后续步骤中是必不可少的,尤其是在启动微调作业时。
在这里,您使用之前检索到的 file_id 并指定基础模型 (gpt-4o-2024-08-06)。超参数如 batch_size, learning_rate_multiplier 和 n_epochs 控制微调过程:
- 批量大小 (8): 这决定了模型在更新权重之前处理的示例数量。对于中等大小的数据集,8 是一个平衡的选择。
- 学习速率乘数(0.05):像0.05这样的较低值可以防止模型过快地覆盖其现有知识。
- 时期(4):模型将整个数据集通过的次数。这里使用4个时期以避免过拟合。
监控微调工作。
# Check the response to monitor the job
print(fine_tune_job)
这部分打印出微调工作的详细信息,包括工作ID、所使用的模型和超参数。它有助于跟踪工作的状态,并确保其以所需的设置运行。

您还可以通过OpenAI的仪表板监控微调作业。一旦作业创建完成,您可以通过作业的响应提供的 URL 或通过OpenAI的微调部分访问仪表板。
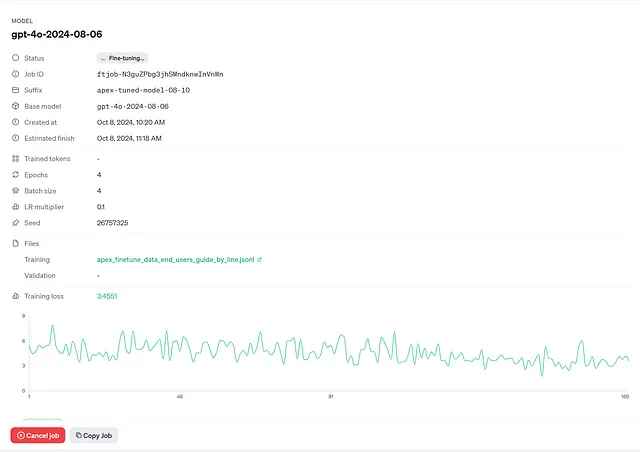
OpenAI还发送电子邮件通知关键事件,如作业完成或失败。这使您可以在无需持续监视仪表板的情况下保持更新。
4. 模型测试
一旦完成微调,就该通过传递与Oracle APEX相关的提示来测试微调模型。这包括一般问题和高度具体的主题,比如JSON关系对偶,这是在APEX 24.1中介绍的功能。
import openai
# Call the fine-tuned model with a specific prompt
def call_finetuned_model(prompt):
response = openai.chat.completions.create(
model="ft:personal:apex-tuned-model", # Fine-tuned model ID
messages=[
{"role": "system", "content": "You are an Oracle APEX assistant."},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
# Example usage
response = call_finetuned_model("Can you explain JSON Relational Duality in Oracle APEX?")
print(response)
结果:
当然!JSON关联双重性是Oracle中的一个功能,它允许JSON和关系数据结构之间的无缝集成和转换。这在处理需要在使用关系数据库的同时使用JSON数据的应用程序时,在Oracle APEX中特别方便...”

该模型成功生成了一份准确且详细的响应,解释了 JSON 关系二元性,展示了其处理有关 Oracle APEX 复杂、特定版本查询的能力。
结论与下一步步骤
这个使用Oracle APEX 24.1终端用户指南微调OpenAI模型的过程展示了当为特定用例定制时,AI可以变得多么强大。通过微调模型,我们已经创建了一个能够回答有关Oracle APEX的复杂和最新问题的专业助手。然而,这只是一个开始。
下一步:
- 这种方法可以进一步优化,通过添加更多的数据类型,比如开发者指南、API参考和甚至论坛问答数据,使助手变得更加多功能和可靠。
- 即将推出,我们将把这个经过精调的模型集成到Oracle APEX应用程序中,它将作为一个专门的AI助手,用于回答有关APEX开发的最新和最复杂的问题。
尽管本文涵盖了数据科学部分和Python代码所需的微调模型,但下一个阶段是API集成——这是一个有趣的部分,可以将该助手直接嵌入到 APEX 应用程序中。
我鼓勵你保持關注,隨著我們越來越接近在APEX中提供增強助手體驗,有更多更新。這將通過在他們的開發環境中提供即時的、特定版本的答案,革新開發人員與Oracle APEX互動的方式。
你可以像往常一样在LinkedIn上找到我:D
令人兴奋的时刻即将到来!