能否用人工智能绘制全球地图?揭示低冗余语言模型对我们世界的看法
LLMs(大型语言模型)旨在用于翻译、写作和摘要等任务。虽然在这些任务上表现出色,但它们对地理的理解可能不够精确。本文通过可视化它们在力导向图中的响应来探讨不同模型如何“感知”世界。
通过查询这些模型并在力导向图中可视化它们的响应,我们旨在了解它们对世界地理的感知准确程度,以及它们的空间推理中是否出现任何模式或偏见。
方法和验证
LLM对地理理解的可视化过程很简单:
城市选择从每个大洲选取了十个受欢迎的城市,以确保全球代表性多样化。
距离计算这些城市之间的距离是使用GPS坐标和Haversine公式计算的,这是一种在球体上测量大圆距离的三角法。该公式提供了大约0.5%的误差。
图形可视化 经过计算的距离被输入到一个力导向图中,城市被表示为节点,距离被表示为边。这种可视化使我们能够看到城市之间的距离与现实地理匹配的情况,并评估图形是否按预期工作。

图形看起来不完全圆的原因是因为地球的大部分被海洋覆盖,导致某些大陆之间没有城市。
提示设计
接下来,我用以下请求提示了LLM。每个提示包含50行城市和一个空的“距离”列。
在表格中填写“距离”列,填写乌鸦飞行的英里数。如果不知道确切的数值,请估算距离。只返回已填写的表格,不要其他内容!
这里是一个例子。从;到;距离 乔治敦;比绍;2921 乔治敦;罗马;7917 乔治敦;巴马科;5537
填写以下表格。
这是GPT在英里里看到地球的样子。

在下表中,我将真实距离与GPT生成的距离进行了比较。正值表示LLM生成了一个更高的值。
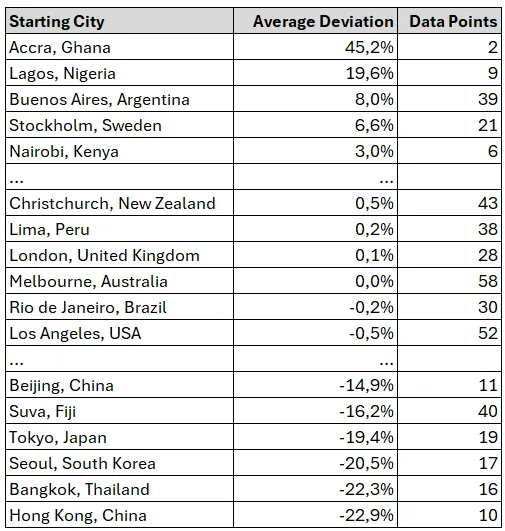
我们可以观察到,亚洲和非洲的城市在表现上比其他地区差。这可能是由于这些地区在训练集中数据表示不足造成的。在亚洲的情况下,语言障碍可能是导致这种不足的原因之一。另一个可能的原因是大多数国家使用公制而不是英里制,这可能会影响数据。
以下是克劳德的结果。由于一些模型表现更好,而另一些表现更差,我们不会进一步探讨数据。

总的来说,结果基本符合预期。当模型的训练数据包含距离时,它提供准确的答案;否则,其回答可能会有些偏差。然而,大洲的总体结构仍然基本正确。
新方法
为了更有效地突显LLMs中潜在的偏见,我考虑了一个不同的方法。如果我们让模型根据从1到100的尺度评估两个城市之间的距离呢?这种方法迫使模型依赖自己的推理,而不仅仅是从训练集中检索数据。
提示被改成了这样:
在表格中的“距离”列内填写一个1到100之间的数字。
| 一个较低的数字表示这些城市彼此之间接近,而一个较高的数字表示它们相距较远。 |
从;到;距离乔治敦;比绍;23乔治敦;罗马;64乔治敦;巴马科;44
填写以下表格。
下面是GPT和克劳德的结果。

GPT的结果尤其引人注目。例如,北美洲和南美洲明显分开,这令人意外。东京和金沙萨显著突出,而首尔似乎几乎隐藏在可视化图像的中心附近。
Claude v2的虚构地球也很有趣,柏林扮演了一种北极的角色,悉尼则是南极,它们与其邻近城市的距离远远超出预期。然而,克劳德将北美和南美的距离拉近了,这与我的预期更加一致。

我期待着不同的结果,也许会有大陆合并,比如北美和欧洲,或亚洲和澳洲。我欢迎读者们的任何解释,也很乐意听听你们的想法。谢谢你们的时间!