搭便车者指南
我经常被问及关键术语、资源以及如何入门。这篇文章是一个简短的尝试,总结了关键术语并提供了链接。
关键术语和概念:
- 本地的拉马:一个充满活力的 Reddit 社区,由从事本地LLM世界的从业者、研究人员和黑客组成。- https://www.reddit.com/r/LocalLLaMA/
- LLM(Large Language Model):通常是基于transformer的模型,具有数十亿甚至数万亿参数,并在大规模文本数据集上进行训练。-https://en.wikipedia.org/wiki/Large_language_model
- 变压器:一种擅长语言任务的神经网络架构。它是大多数现代LLM的支柱。 — “注意力就是一切”论文:
- GPT(生成式预训练变压器):一个训练有素的变压器模型,用于预测句子中的下一个标记。GPT-3是一个显著的例子。 —— OpenAI的GPT-3博客文章
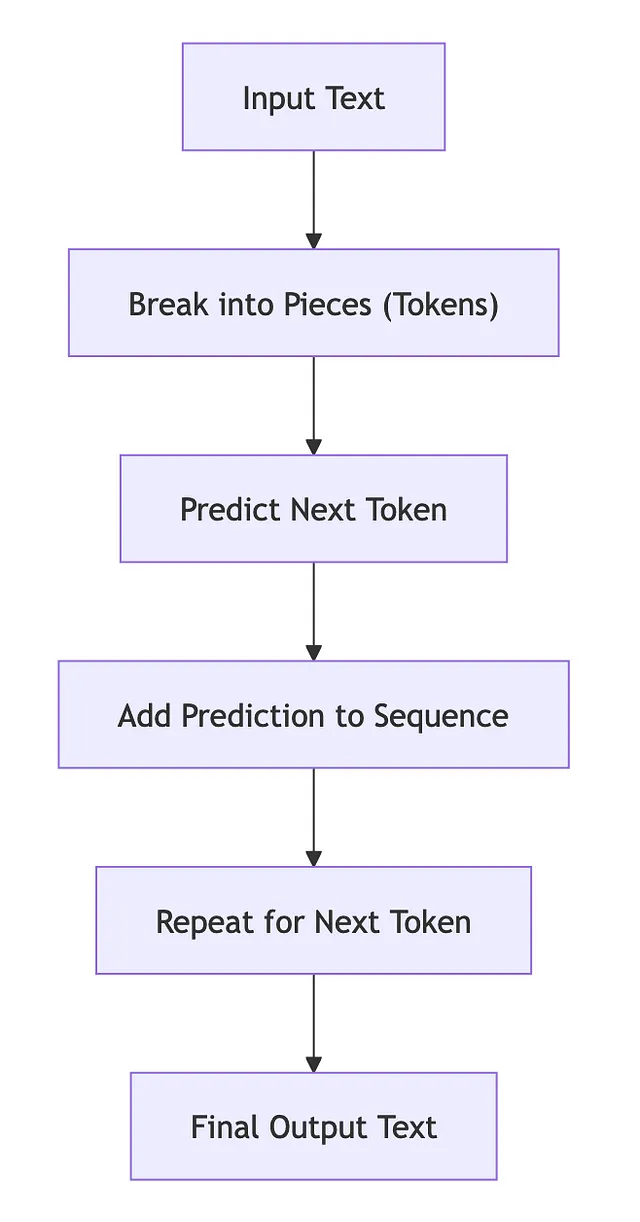
- 自回归模型:一次生成一个标记的文本,使用自身的预测来影响后续标记的生成。— 维基百科:自回归模型
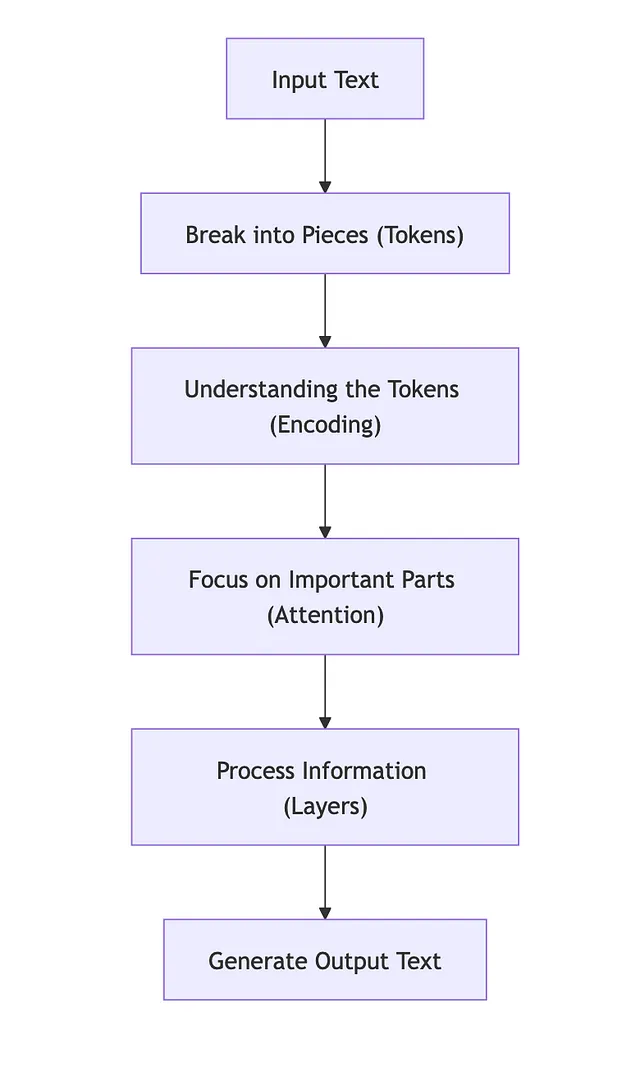
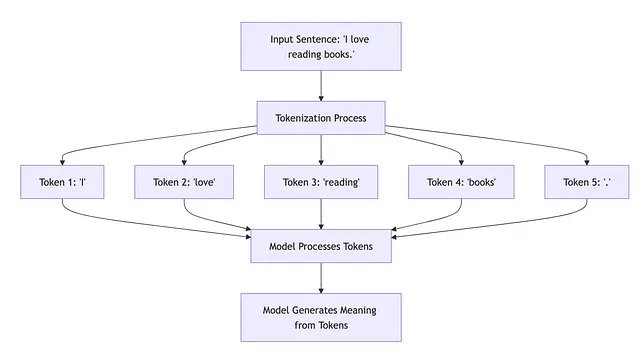
- 令牌:模型理解的最小文本单元。它可以是一个单词、一个单词的一部分或标点符号。 — Hugging Face Tokenizers 文档
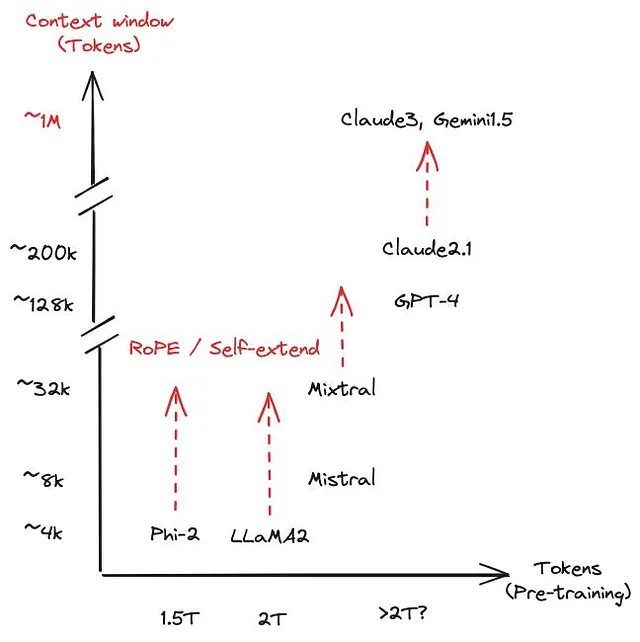
- 上下文长度:模型可以同时处理的标记数。更高的上下文长度可以提供更大的存储器和理解能力,但需要更多的资源。 https://agi-sphere.com/context-length/
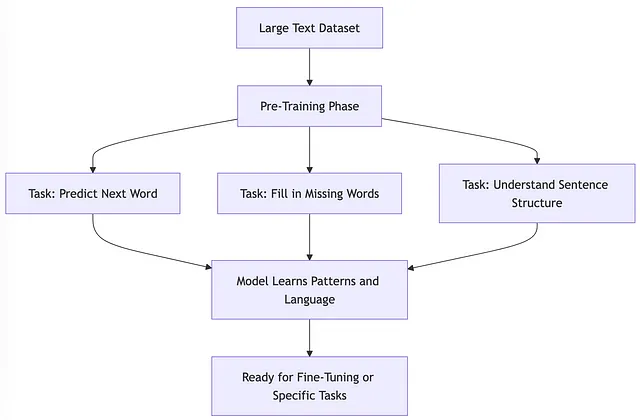
- 预训练:对神经网络进行预训练是指首先在一个任务或数据集上训练一个模型。然后使用这个训练的参数或模型来在另一个不同的任务或数据集上训练另一个模型。
- 微调:在较小的标记数据集上对预先训练的模型进行训练,以执行特定任务。 — Hugging Face微调教程
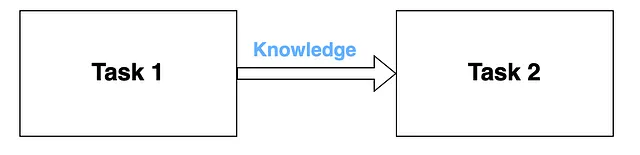
- 迁移学习: 迁移学习是指利用从一个机器学习问题中获得的知识来解决另一个问题。例如,利用从猫/狗检测中获得的知识来检测建筑物。迁移学习的主要组成部分是使用预训练模型从一个任务中获取知识并应用到其他任务中。最重要的是,迁移学习被认为是人工智能开发者的一大进步,因为它让我们能够更快速、更高效地开发应用程序。
提示:初始文本输入是提供给模型以指导文本生成的。
- 零-shot: 生成文本而不进行任何特定任务的微调。
- Few-shot: 在提示中提供少量示例生成文本。
- 指导微调:微调一个模型以遵循指导并生成更受控制的响应。- InstructGPT 论文
- RLHF(利用人类反馈的强化学习):一种通过利用人类反馈和强化学习来提升会话能力的微调技术。- OpenAI博客:将语言模型与指令对齐
- 打开LLM排行榜:一个平台,比较各种基准上开放存取的LLM的表现。—Hugging Face Open LLM Leaderboard
- 聊天机器人竞技场:一个基于人类喜好评估对话模型的流行开放基准测试。— lmsys.org 聊天机器人竞技场
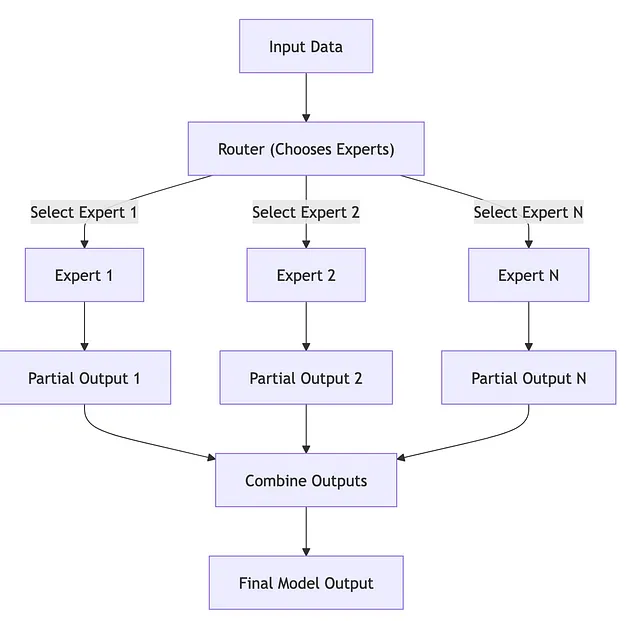
- 专家混合(MoE):一种架构,其中一些层被一组专家所取代,每个专家专门从事任务的不同方面。 https://huggingface.co/blog/moe
- 模型合并:将多个模型合并成一个更强大的单一模型的方法。— 模型合并论文
- 本地LLMs:由于模型效率和量化的进步,现在可以在个人电脑甚至智能手机上运行LLMs。 —— 本地AI项目
- 量化:通过降低模型权重的精度来减小模型大小,从而实现在资源受限设备上部署。- Hugging Face博客:量化
- PEFT(参数高效微调):一组微调模型的技术,只需对其参数进行最小的更改。 — Hugging Face PEFT文档
- 多模态:能够处理多种输入模式(文本、图像、音频)并生成相应输出的模型。- OpenAI CLIP博客文章
在本地运行模型
奥拉玛
奥拉玛是一种流行且快速运行模型的方法。它很容易在Mac、Windows和Linux上安装。只需一个命令,你就可以下载和运行一个模型。有一个漂亮的网页界面可以浏览可用的模型。这些模型已经预量化,因此可以在比原始模型低得多的硬件上运行。有很大的生态系统与Ollama集成并可以与之一起工作的工具,因此它是一个很不错的原型方式,并且在开发应用程序时目标明确,因为它的服务器模式非常受欢迎。
文本生成WebUI
文本生成WebUI,有时称为Ooga Booga,是另一种流行的选择。这更像是一个应用程序本身。它自动安装Llama.cpp,但也包含其他运行和连接到LLMs的方法。
利亚马文件
Llamafile 是 Mozilla 的一个非常有趣的项目,它将跨平台运行时嵌入到模型本身中。这允许您下载一个单一文件,然后双击它,立即开始与模型交互。运行时是 Llama.cpp 的一个分支。Llamafile 的开发人员一直非常活跃,不断添加速度改进,并将它们提交到 Llama.cpp 的上游。
呢骡.cpp
Llama.cpp是LLMs快速推理的实现。它最初是Llama2的CPU实现,但已扩展为支持广泛的模型,具有许多后端,包括通过CUDA、Metal和Vulkan支持的GPU。它还可以在混合状态下运行模型,其中模型的一部分在CPU上运行,一部分在GPU上运行。它甚至可以在树莓派和安卓设备上运行!
羊驼- CPP- Python
Llama-cpp-python是llama.cpp的python封装器。这是我们在直接转向Llama.cpp之前将使用的第一件事。
选择一个模型
量化的,7b,13b,Q5_?什么鬼?
好的,在选择一个模型时,你会遇到很多行话术,让我们来分解一些。
- 参数 — 这是模型中权重的数量。通常用十亿或万亿来表示,因此有7B、13B、1.7T。参数的数量直接影响运行模型所需的内存,以及生成文本所需的处理能力。这也可以用来快速估算运行模型所需的最小内存量以及下载的大小。在不深入研究模型配置和架构的情况下,许多模型使用16位浮点数作为大多数权重,因此7,000,000,000个参数 * 2字节 = 14,000,000,000字节 = 14吉字节的内存。
- 量化/量化/Q4/Q8 - 这是一种有损压缩。基本上,它试图在丢弃不影响LLM结果的信息的同时保持尽可能多的原始数据和性能的平衡。在我们下载了一个模型之后我会更深入地介绍这个概念。我们将首先以完整精度下载一个模型,然后学习如何进行量化。
- 基础/聊天/指导模型 - 这些是训练的不同水平、阶段或目的。基础模型已经进行了大部分的训练。这是训练和构建模型的昂贵部分。聊天和指导的变体经过了进一步的训练,也被称为微调,以针对特定目的或用途进行训练。指导模型也被称为“遵守指令”。这对于您可能要求总结文件或执行特定任务的模型非常有用。聊天变体更针对聊天机器人和助手,擅长处理问题/回答提示格式。
- LOAR / QLOAR / PEFT — 这些都是在微调中使用的技术,可以大幅减少内存和计算需求。 它们与模型在训练后没有关联。 有时您可能会遇到一个仅可用作“LOAR”的模型,这意味着它是微调的结果,但结果尚未被“应用”或合并到模型中。 您可以将其视为一种差异或一组增量更改。 在这种情况下,您需要加载原始模型,然后应用LOAR,或者您可以将LOAR合并到原始模型中并另存为新文件,然后像加载任何其他模型一样加载。
- (更多)专家混合/ MoE - 这是一种模型架构,其中仅在特定时间使用/激活模型的部分。您仍然需要能够将完整模型加载到内存中,以获得快速的推理/生成速度,因为模型将决定下一部分生成的句子需要哪个专家。由于任何给定时间仅使用一部分,这显着加快了模型的推理/生成速度。例如,Mixtral一次仅使用两个专家,并由八个70亿参数专家模型组成,因此您的生成速度接近于15b参数模型。但需要明确的是,这些专家是不能选择的。您不能只说“嗯,我不需要医学信息,所以我会关闭该专家”。这不是它的工作方式,我也不确定模型的哪一部分包含哪一部分知识或培训。这纯粹是一种计算优化,而不是知识分割。
- 合并/合并模型 — 这是一个过程,其中2个模型的权重可以合并,结果可能优于两个原始模型。 这是一个可以产生有趣结果的有趣概念。
模型格式
模型可以以多种方式打包、分发和运行。选择的运行方法通常决定了你需要的模型格式。幸运的是,我们只需要担心几种,但下面是一些术语,你可能会遇到相当多。
- PyTorch — 这并不是一个严格的LLM格式,而只是一个通用的PyTorch模型,可以以几种方式保存。
- .pt / .pth / .bin — 这是 PyTorch 模型的通用序列化格式。这是使用 Python 的 Pickle 库进行序列化的,该库在解压过程中还可以包含和执行 Python 代码,这自然会引发一些安全问题,特别是如果你开始真正进行实验并下载许多任意模型进行测试。
- SafeTensors — 这是一种序列化模型的新方法。通过 pickle 方法保存的 PyTorch 模型可能包含任意代码,而 SafeTensors 不能,因此它是一种更安全的格式,用于共享模型。
- 拥抱脸 / hf / 变换器 - 这通常只是一个具有特定文件布局的PyTorch或SafeTensors模型,用于定义模型、模型架构、分词器等。这与拥抱脸变换器库兼容。这是我们将要下载的模型类型。
- GGUF(GPT生成的统一格式)—该格式是与Llama.cpp项目一起开发的,因此我们将在推理/生成中使用它。所有必要的数据都打包到一个文件中。
- GGML - 这是GGUF的前身,现在已经过时了。你应该转换或继续使用GGUF。
- JAX — JAX是来自谷歌的高性能机器学习库,他们发布了一些模型的变体,支持JAX。
- ONNX Runtime — ONNX是微软推出的人工智能框架。微软通常会使用ONNX变种来发布他们的模型。
绝大多数模型都发布了HuggingFace Transformers版,因此这是一个我们可以专注的良好格式,因为它得到了广泛支持和获得。
输入HuggingFace模型
通常情况下,HuggingFace 模型由许多文件组成,以下是您可以在 HuggingFace 模型中看到的一些文件。
- config.json 将描述一些模型配置。
- generation_config.json 定义了一些运行时参数,如上下文长度和温度。
- *.safetensors或者*.bin存储实际的模型权重和不同的矩阵。特别是对于非常大的模型,可能会有多个这些文件。
- index.json 定义了模型的哪些部分存储在哪个文件中。如果您下载的模型没有分成文件,可能不存在。
- tokenizer.json, special_tokens_map.json - 这些文件定义了模型的令牌。 您可以在文本编辑器中打开它,查看所有令牌ID及其关联的字符串。
- tokenizer_config.json - 分词器的配置。