OpenAI 提供即时缓存以降低 API 成本.

从2024年10月1日开始,对于最新版本的GPT-4o、GPT-4o 迷你版、o1 预览版、o1 迷你版及其经过调优的变体,Prompt Caching 将自动启用。该功能有助于降低使用这些模型的成本,因为缓存的提示可以按照打折价提供,与未缓存的提示相比。通过缓存经常使用的提示,OpenAI 优化性能,同时为常与模型互动的用户提供更具成本效益的解决方案。这种增强功能确保更有效地利用资源,并为与大规模应用程序一起工作的开发人员提供更好的可扩展性。
什么是提示缓存
在生成式人工智能(genAI)中,提示缓存是指存储先前处理的提示结果以减少计算负荷和成本的实践。当用户向人工智能模型发送提示时,系统会检查是否已经处理过相同或足够相似的提示,而不是每次重新计算响应。如果有缓存的响应可用,可以快速检索而无需再次生成它,从而减少了计算资源的使用并提高了响应时间。
这种方法特别适用于重复或频繁请求的提示,因为它有助于优化性能,并显著减少API调用的成本。 缓存提示通常以较低的价格提供,与新的、未缓存的提示相比更经济,对于在客户支持、内容生成或自动化工作流等场景中反复与AI模型交互的用户来说更经济。
如何使用提示缓存
即使对于某些OpenAI模型如GPT-4o、GPT-4o mini、o1-preview和o1-mini以及它们的fine-tune版本,Prompt Caching都会自动应用。请确保在API请求中使用其中一个模型,因为Prompt Caching只会与它们一起使用。
不需要额外采取行动来启用API请求中的缓存。您可以像平常一样向OpenAI API发送提示。OpenAI的系统会自动检测是否最近已经使用了相同或类似的提示,并在可用时检索缓存的响应。
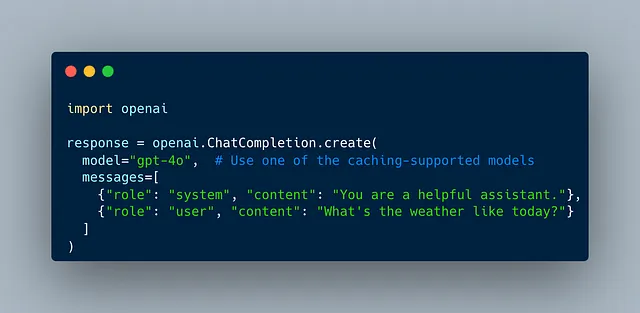
如果先前已经使用过该提示,并且存在缓存版本,则OpenAI将自动返回缓存的结果。缓存提示的收费标准比非缓存提示的费用要低,这有助于降低您的整体API成本。
确保您熟悉缓存与非缓存提示的定价,因为缓存响应将更便宜。这些费率的具体信息通常可以在OpenAI的定价文档中找到,或者通过联系OpenAI支持团队获取。
尽管缓存会自动发生,但您可以通过重用常见提示或以增加它们被缓存的可能性的方式构造提示来最大化好处。例如,对于常见输入数据的“总结此文本”等一致查询可能会受益于缓存。
如果提示没有缓存存在,模型将像往常一样生成一个新的响应。然后该响应可以被存储在缓存中以备将来使用。
通过利用提示缓存,您可以优化您对OpenAI API的使用,使您的交互更加高效和具有成本效益。
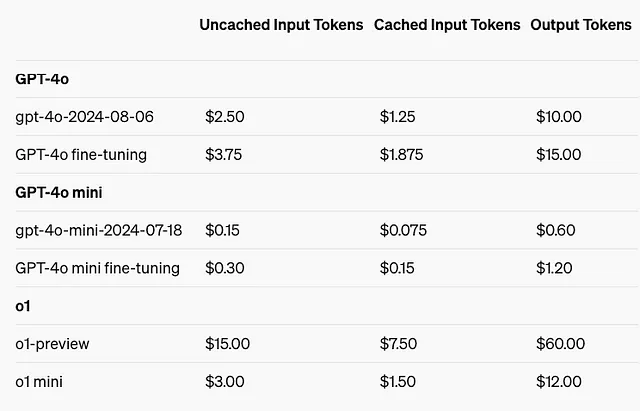
我可以节省多少?
在所有列出的模型中,与未缓存的输入令牌相比,使用缓存的输入令牌时节省的百分比始终为50%。这意味着使用缓存的提示可以将输入令牌的成本减少一半。
如何检查缓存使用情况
当您调用支持的模型的API时,对于超过1,024个标记的提示,Prompt Caching会自动启动。 API会保存已经处理过的提示的最长部分,从1,024个标记开始,每次添加128个标记。如果您经常使用类似开头的提示,则Prompt Caching折扣将自动应用,无需更改API设置中的任何内容。
您可以通过检查 API 响应的 usage 字段中的 cached_tokens 值来查看是否使用了提示缓存。