一个AI助手如何使用CRISP-DM来解决数据科学问题
当我的数据挖掘教授要求我们尝试使用AI助手进行数据科学时,我起初持怀疑态度。当然,它可能会给我提供示例代码并解释每个步骤的过程,但它能否完成整个项目并返回给我不同的数据可视化或图表呢?
好吧,二十美元和三十分钟后,我感到震惊!经过一番迅速的工程和与我的助手的讨论,我清楚地了解了一个有经验的数据科学家(即ChatGPT 4o Mini)如何使用医疗保险数据集和CRISP-DM方法论来解决保险费用预测问题。
这个过程的第一步是使用初始提示为助手设置上下文。
你是一位行业领先的数据科学家,精通利用CRISP-DM方法解决各个领域的数据科学问题。我希望你能逐步指导我处理我提供的数据集。我们将一步一步地进行,直到我在提示中说“下一步”为止你才会进行下一步。创建一个干净的回复,并清晰解释你的思维过程。考虑到我们的计算能力有限,请使用合理大小的块。
我们正在尝试预测‘charges’列。 您必须向我提供代码(以及执行的响应)和每个步骤的报告。 在遵循CRISP-DM的同时,请记住在适当的步骤中包括数据理解,可视化,清洁,预处理,特征选择和回归(使用不同的模型)。 比较模型在许多度量标准上的表现,并向我推荐最好的模型。 在每个步骤结束时,总结我们做了什么,接下来要做什么。
你可以使用Python的scikit-learn和pandas库,以及你需要的其他库。这些块应该按照CRISP DM方法论的每个步骤来划分。
在第一个段落中,我要求它模拟一名专家数据科学家的角色,并给出一份清晰的指示清单,让它在生成结果时遵循。在接下来的段落中,我提供了问题陈述和数据集,并要求它根据每个步骤生成特定的产品,包括代码、执行响应和摘要。我还定义了在整个过程中必须完成的不同任务,并在适当的阶段进行。在最后一段中,我只是添加了一些我认为必要的额外信息。
这个提示确实需要几次尝试来重写,以便生成所有所需的文档,并且以适当的格式,但我对它的工作感到满意,所以最终我进行了实际的生成步骤。
在其第一次回应中,它完成了整个业务理解阶段和一些基本的数据理解阶段任务。

类似于数据科学家会听取问题陈述并制定一组需求,助手也能通过明确定义我们的目标来做到同样的事情。
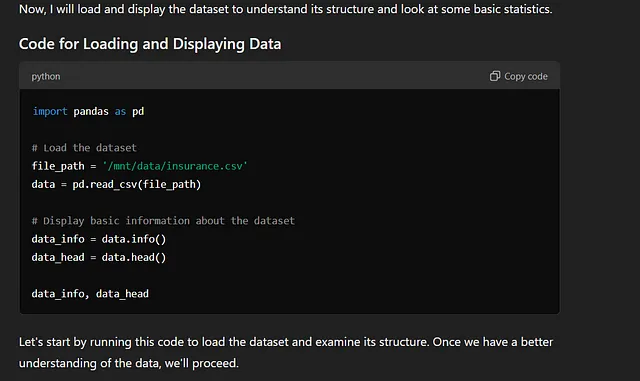
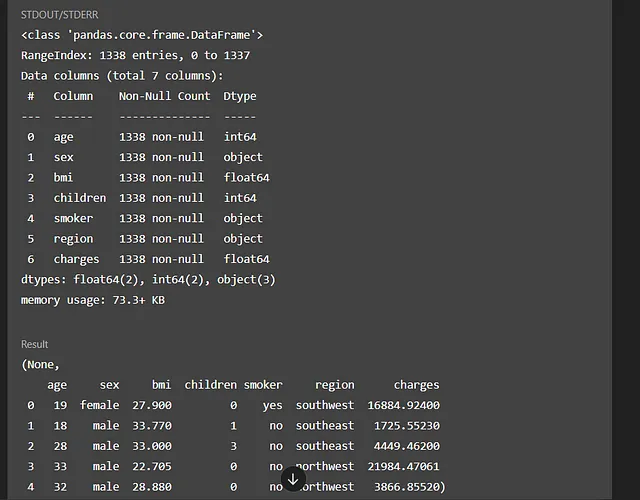
转到数据理解阶段,对提供的数据集运行info()和head()方法,并显示结果。还分析了缺失值的列,并生成了摘要和下一步计划。


在生成了这一块之后,我要求它按照我的提示所定义的“下一步”继续。它选择继续进行探索性数据分析(或简称EDA),但我不明白为什么它没有选择标题“数据理解”。我对此提出了疑问,它给了我一个有效的回复,就像你和项目伙伴讨论时会做的那样!
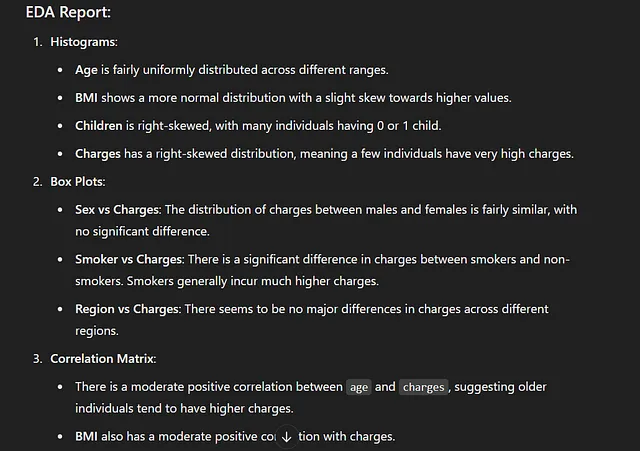
它在承认应该以不同方式行事的同时,为自己的决定进行了辩解,这很酷!好吧,回到手头的问题上,它通过生成代码并执行探索性数据分析步骤的响应来执行相同的一组步骤。它使用Matplotlib和Seaborn库创建以下直方图、箱线图和相关矩阵。
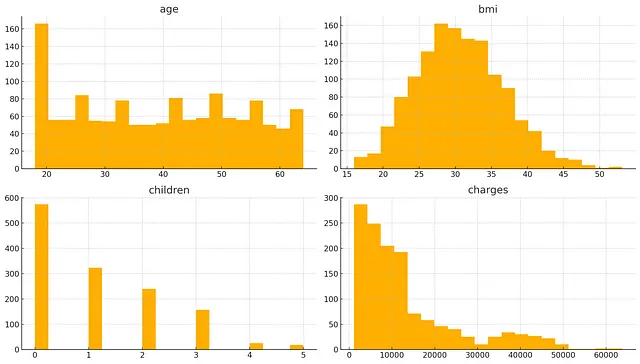
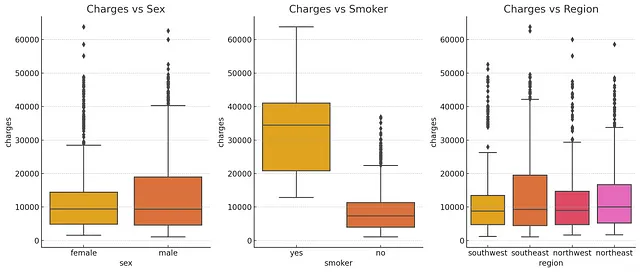
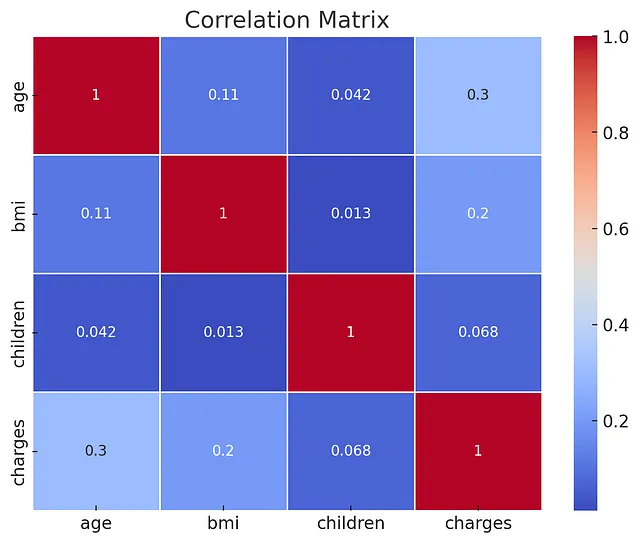
它还从每个可视化生成了清晰的报告摘要。
在数据理解阶段完成后,我们继续进行下一个响应,即数据准备阶段。

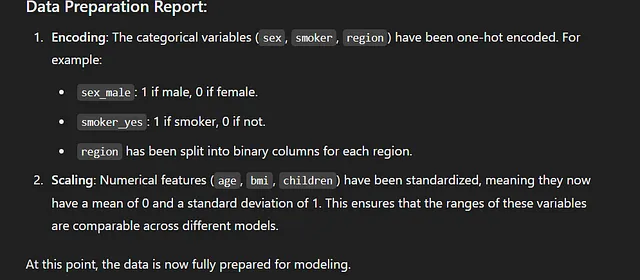
助理决定将分类数据转换为数字形式并对数字数据进行归一化处理。预处理后的数据现在看起来与我们最初的数据不同,但更适合被发送到模型进行分析。
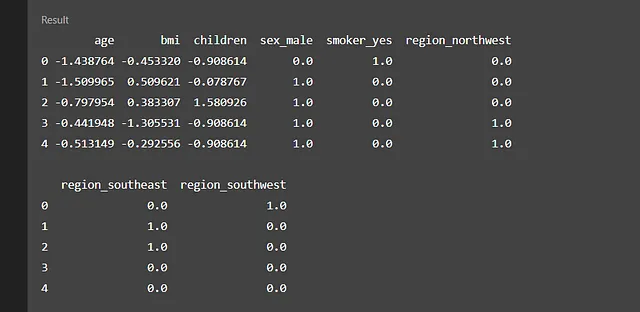
但在继续之前,我想回到数据理解的第二阶段,因为我们创建了新的列。我要求重新生成相关矩阵以及其发现。
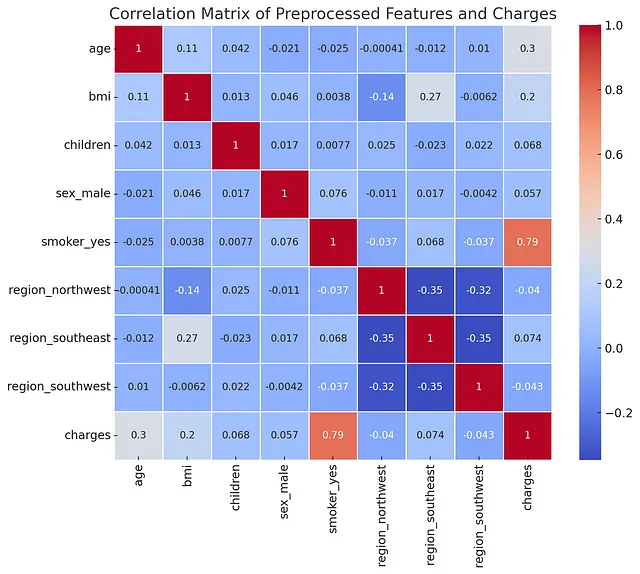

有了这些新的发现,我们决定继续进行下一步,建模阶段。

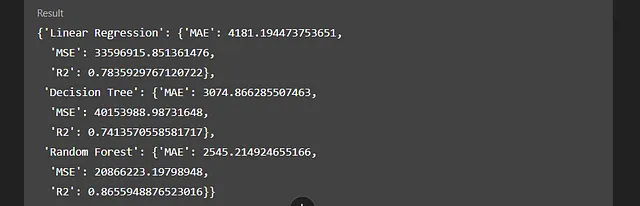
它选择了三种不同的回归模型 — 线性回归、决策树回归器和随机森林回归器。它生成并执行了代码,对我们的数据集进行训练,并展示了它们在一些常见指标上的表现 — 平均绝对误差,均方误差和R-squared。它能够总结它们的表现,认为随机森林回归器是最佳选择,并给出了理由。

我进一步调查了一下,以了解为什么每个模型在这种情况下表现如此,与其他模型相比,它提出了一个一般性的推理,解释了可能导致这种情况的原因。它指出了线性回归的线性假设和决策树的过拟合倾向作为它们比随机森林回归器表现更差的主要原因,随机森林回归器平衡了复杂性和泛化性,捕获了非线性关系和互动关系,而不会过度拟合。
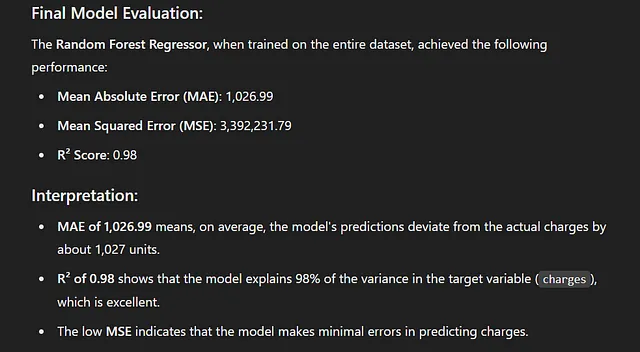
最后,我们进入了评估阶段。在选择随机森林回归器之后,它在测试数据上对模型进行了训练,并生成了最终的指标和总结。
当我要求它进入下一个阶段时,我期望的是一些部署策略。然而,它选择执行一些特征重要性分析。我质疑它做出这样的决定,它指出虽然这通常是数据理解阶段的一部分,但在这里执行这一步使得我们能够理解模型行为并可能优化模型。这本质上就是CRISP-DM方法论的要点,能够重新审视之前的步骤以改进,这对我来说是一个很好的学习点!
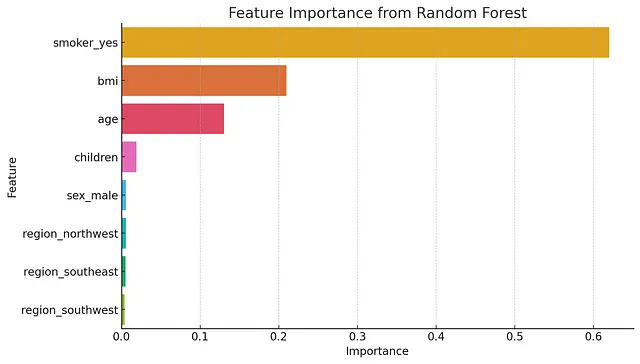

它能够发现一些关键见解,了解哪些趋势似乎在影响保险费用,以及它的最终建议。
随着评估阶段的完成,我们转到了部署阶段的最后一步。它为我提供了一个部署策略和 Flask 中的示例代码,以及一些监控和维护方面需要注意的要点。

嗯,就是这样 - 通过AI助手完全解决数据科学问题的CRISP-DM方法论。能够在几分钟内完成这项工作将彻底改变我们对计算机科学世界的看法!这确实是我们不能再忽视的事情,但这些发展值得期待和激动。就我个人而言,我迫不及待地想要在我的个人项目中使用它!
随意查看文字记录和GitHub存储库,或在LinkedIn上联系我。