了解LLM代理:为联系中心优化构建AI解决方案的实用指南
几个月前,我意识到全球联系中心都在努力准确分类电话并了解呼叫量背后的具体原因。作为数据科学顾问,这个想法激发了我一个想法——我们是否可以建立一个解决方案来解决这个问题?
这是一年多以前,当LLM刚开始蓬勃发展的时候。我的最初想法是使用手动标记的数据训练NLP模型-一种传统的机器学习方法-因为我怀疑LLMs是否能处理这样一个微妙的用例。第二个选择-我考虑建立一个主题建模模型,与当今的LLM代理的功能相比,现在看起来功能极少。然后另一个想法冲击了我:如果我们能够微调一个开源的、较小的模型,如初期版本的Llama或Alpaca,以对联系中心的呼叫进行分类和识别主题会怎么样呢?然而,这些方法都没有快速的反馈和较少的努力。在研究过程中,我了解了LLM代理的概念以及如何使用基础LLM添加状态和工具来建立一个完全功能的解决方案,而无需进行微调。有了这个解决方案作为起点,我已经为我的组织建立了几个AI代理人(一些包括RAG等)来解决问题。
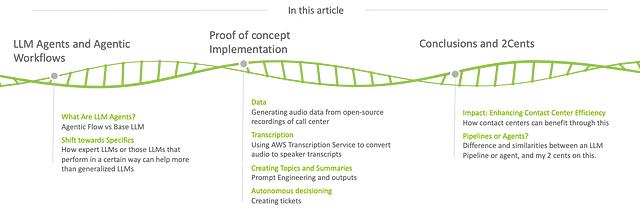
在这篇文章中,我深入研究了在过去一年里如何在我的组织中专业地建立LLM代理,以解决这个问题以及许多其他问题。与我们的联系中心团队密切合作,我们利用这些LLM代理来分析通话记录,使我们能够做出前所未有的基于数据的决策。我将分享我在LLM代理方面的学习和经验,并展示它们如何可以自动化流程,并解锁组织中的创新解决方案能力。
尽管我的经验主要围绕在Azure AI Studio中构建代理和LLM管道,但任何代理流程的核心原则在各个平台上保持一致。最近我开始通过吴恩达的课程学习更多关于AWS Bedrock的知识,该平台提供了惊人的低代码能力,并有助于构建LLM代理和评估流程。以下是我在AWS Bedrock上的实验,利用亚马逊的Titan LLM构建这个“代理流程”。随着我踏上与AWS Bedrock的新旅程,我将强调我的经验,采用提示工程和基础技术以提高准确性并减少幻觉。
了解LLM代理和代理工作流程
什么是LLM代理?
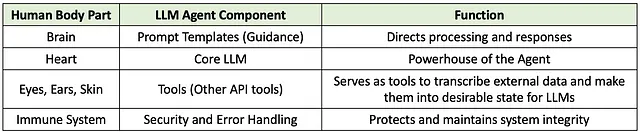
LLM代理是由大型语言模型(如OpenAI的GPT-4或亚马逊的Titan)驱动的先进人工智能系统。为了更好地理解这一点,在下面的表格中,我对AI代理与人体进行了一个过于简化的比喻性比较。就像心脏是身体的动力源一样,GPT和Titan等核心LLM构成了基础,而其他功能使动力源更适合工作。与操作在被动、单一回合交互模式下的基础LLM不同,LLM代理被设计为动态地与环境进行交互,自主执行任务,带来一些其他基础LLM无法提供的知识,如使用RAG检索公司文档,并进行多回合对话。
主动工作流程解释
主动性工作流程是指AI代理独立执行任务的过程,根据接收到的数据和编程的目标做决策。在联系中心的背景下,主动性工作流程使AI代理能够处理客户互动,从对话中提取洞见,并在没有持续人为干预的情况下提供可操作的结果。
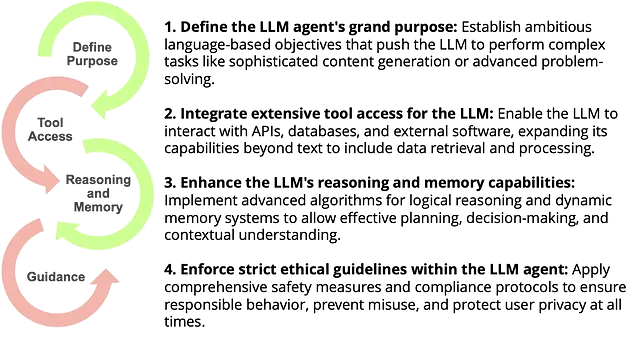
从基本LLMs到专家代理的演变
基本LLM和LLM代理之间的区别
虽然基本的LLMs能够根据输入提示生成类似于人类的文本,但它们缺乏自主执行任务或与外部系统交互的能力。另一方面,LLM智能代理则旨在:
- 了解上下文:在多回合对话中保持状态。
- 与系统互动:执行操作,访问数据库或调用API。
- 学习和适应:通过反馈循环随着时间的推移改善性能。
我对LLM代理的理解是:LLM代理 =

A. LLM:了解并生成类似人类文本的核心模型,基于输入提示。 B. STATE:保持上下文的机制,使其能够在多次互动中保持连贯和具有上下文意识的对话。 C. TOOLS:与外部系统(如API和数据库)交互的接口,使代理能够执行操作并访问最新信息。
专业化的转变
LLM代理代表了转向更专业的系统,可以处理复杂任务。他们不仅仅是被动的回应者,而且是工作流程中积极参与者,能够理解微妙的客户互动并提供定制解决方案。
使用AWS基石构建主动型工作流
在这一部分,我们将探讨如何使用AWS Bedrock创建一个任务代理工作流来提升联系中心的能力。我们将使用开源音频记录,转录它们,并利用亚马逊的Titan LLM生成摘要见解。代理将自主决策创建带有主题和摘要的服务票。这是一个非常简单的概念验证代码,可以进一步定制(例如-添加模板中的基础固化和几个截图等)以进一步改进模型。
逐步实施(概念验证)
这只是示例代码,不包含许多其他功能和类。我已经将github存储库与这篇文章固定在一起… 😅
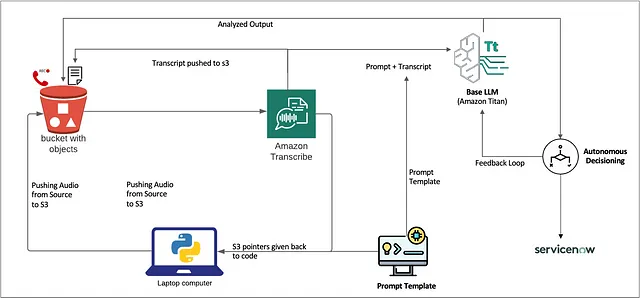
1. 在亚马逊S3中存储音频录音
我从几个网站下载了一些mp3录音,这些录音的例子如下:
我首先将音频记录上传到亚马逊S3存储桶。这些记录作为我们工作流程的原始数据。
import os
from helpers.s3_helper import S3_Helper
bucket_name = 'audiorecordingsllm'
data_folder = 'data'
s3_helper = S3_Helper(s3_client)
for filename in os.listdir(data_folder): # Upload audio files to S3
if filename.endswith('.mp3'):
audio_path = os.path.join(data_folder, filename)
s3_helper.upload_file(bucket_name, audio_path, filename)
解释:我遍历数据文件夹中的音频文件,并使用辅助类将它们上传到我们的S3存储桶中。
2. 使用亚马逊转录来转录音频
接下来,我会使用亚马逊转录功能转录音频文件,该功能将语音转换为文本并支持说话者识别。
from helpers.transcribe_helper import Transcribe_Helper
transcribe_helper = Transcribe_Helper(transcribe_client)
transcript_job_name = 'transcription-job-' + str(uuid.uuid4())
transcript = transcribe_helper.transcribe_audio(
transcript_job_name, bucket_name, filename
)
解释:我创建一个独特的转录工作名称并开始转录过程。助手类处理与转录服务的交互。
3. 格式化转录
一旦我收到文字记录,我会将其格式化以识别说话者的标签和内容,并准备数据进行总结。
def extract_transcript_from_text(transcript_json):
output_text = ""
current_speaker = None
items = transcript_json['results']['items']
for item in items:
speaker_label = item.get('speaker_label')
content = item['alternatives'][0]['content']
if speaker_label and speaker_label != current_speaker:
current_speaker = speaker_label
output_text += f"\n{current_speaker}: "
output_text += f"{content} "
return output_text
说明:此函数处理来自亚马逊转录的JSON输出,并使用讲话者标签对转录内容进行结构化处理。
4. 使用Jinja2模板制作提示
提示工程对指导LLM产生期望的输出至关重要。我使用Jinja2模板来创建动态提示。
from jinja2 import Environment, FileSystemLoader
env = Environment(loader=FileSystemLoader('templates'))
template = env.get_template("prompt_template.txt")
data = {
'transcript': formatted_transcript,
'topics': ['charges', 'location', 'availability']
}
prompt = template.render(data)
解释:我加载一个提示模板,并使用文本和特定主题渲染它,让LLM专注于这些主题。
提示模板(prompt_template.txt):
I need to summarize a conversation. The transcript of the conversation is between the <data> XML like tags.
<data>
{{transcript}}
</data>
The summary must contain a one-word sentiment analysis and a list of issues or causes of friction during the conversation. The output must be provided in JSON format as shown in the following example.
Example output:
{
"version": 0.1,
"sentiment": <sentiment>,
"issues": [
{
"topic": <topic>,
"summary": <issue_summary>
}
]
}
An `issue_summary` must only be one of:
{%- for topic in topics %}
- `{{topic}}`
{% endfor %}
Write the JSON output and nothing more.
说明: 指令要求LLM生成一个JSON输出,汇总对话内容,重点关注指定的主题和情感分析。
5. 使用亚马逊的 Titan LLM 进行总结
我通过Bedrock运行时客户端将精心制作的提示传递给亚马逊的Titan LLM,以生成摘要。
def bedrock_summarisation(prompt):
kwargs = {
"modelId": "amazon.titan-text-lite-v1",
"contentType": "application/json",
"accept": "*/*",
"body": json.dumps({
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512,
"temperature": 0.8,
"topP": 0.9
}
})
}
response = bedrock_runtime_client.invoke_model(**kwargs)
response_body = json.loads(response.get('body').read())
return response_body['results'][0]['outputText']
解释:我配置了模型参数并调用了模型。响应被解析以提取摘要。
6. 输出和解释
最终输出是一个以JSON格式呈现的摘要,包含了对谈话中讨论的情绪和问题的描述。
{
"version": 0.1,
"sentiment": "Negative",
"issues": [
{
"topic": "charges",
"summary": "The customer is disputing unexpected charges."
},
{
"topic": "availability",
"summary": "The service the customer needs is currently unavailable."
}
]
}
解释:这种结构化输出可以帮助联系中心快速了解客户情绪并有效地解决问题。
第7步:解析LLM输出并提取主题
import json
# Parse the LLM output
llm_output = bedrock_summarisation(prompt)
summary_data = json.loads(llm_output)
issues = summary_data.get('issues', [])
解释:解析LLM输出的JSON数据,并提取问题列表。
步骤8:定义可操作的主题并创建服务票。
本节的代码是针对组织特定的,并且可以与ServiceNow数据库集成,自动创建工单。
actionable_topics = ['charges', 'availability', 'billing', 'technical_issue']
def create_service_ticket(topic, issue_summary):
ticket_id = str(uuid.uuid4())
print(f"Created ticket ID {ticket_id} for topic '{topic}': {issue_summary}")
Explanation: 指定需要采取行动的主题,并定义一个创建工单的函数。
第九步:处理问题并采取行动
for issue in issues: # Process each issue and create tickets if necessary
topic = issue.get('topic', '').lower()
summary = issue.get('summary', '')
if topic in actionable_topics:
create_service_ticket(topic, summary)
说明:对于每个提取出的问题,如果该主题是可操作的,则创建一个服务工单。
由于该当前原型基础且易于实现,我们有巨大的机会通过个性化和改进进行定制。
融入微调:可以通过在特定领域数据上对LLMs进行微调来提升在对客户互动进行分类和解释时的准确性。确保数据隐私和合规性:可以实施强大的数据保护措施并遵守合规框架,以在整个工作流程中保护敏感客户信息。提高可扩展性和健壮性:可以增强系统的可扩展性和健壮性,以有效处理高容量电话处理,包括更好的错误处理和容错能力。整合人类监督:可以建立人类审查和验证AI生成的输出的机制,以维护系统决策的准确性和可靠性。
影响:增强联系中心效率
通过自动化客户互动的转录、摘要和工单创建,联系中心可以:
- 减少手动出票时间:由于代理商可以手动识别原因、打开和指定票。
- 减少电话数量:了解客户为何致电,量化并做出战略性决策。
- 增强质量保证:监控互动以确保合规和性能。
- 获得洞察:分析客户反馈和情绪的趋势。
管道与代理 — 哪一个更合适?
当我们探索LLM代理时,值得质疑它们是否真的必不可少。虽然它们提供了高级功能,但也带来了复杂性和不可预测性。一些专家建议使用更简单的LLM管道以获得更好的透明度和可靠性。重要的是避免盲目跟风新技术趋势而不评估实际需求。最终,考虑一下LLM代理对于您的具体案例是否必要,或者更简单的解决方案是否同样有效。
我的看法:
在过去的几年中,随着我们开始使用GPT-3和更小的开源模型,如Llama,行业仍在学习如何有效地实现这些技术。当我开始在我的组织中实施这个解决方案时,我最初的想法是要微调一个LLM,因为我相信像ChatGPT这样的模型可能不会像需要的那样表现出色或提供足够的上下文。然而,随着检索增强生成(RAG)、少样本学习和无代码LLM的出现,景观开始发生变化。
我与Azure OpenAI团队合作,进行了多次会议,以了解什么是Agent流和我们可能不需要对LLMs进行微调,除非绝对必要。在我进行这些项目的过程中,Prompt流、思维链、上下文学习、基础和幻觉等概念——所有与人工智能相关的关键词——开始变得清晰起来。在这段旅程中,我面临了几个挑战,我计划写更多关于每个挑战的文章。
总之,我会说我们仍然处于人工智能之旅的开端阶段,虽然这些模型很令人兴奋,但有时会失败或者表现不如我们所希望的那样。然而,它们提供了令人惊叹的工作流程,可以解决组织内的重大挑战。它们提供了宝贵的见解,增加了净收入,并帮助使过程更加精益和优化。
我在持续学习中可能会忽略某些方面或者过度简化一些内容,但这是基于我目前的理解。我欢迎任何建议和问题,以进一步完善这项工作。