使用ChatGPT和Python进行网络爬虫来寻找新的绿色工作
作为一名最近的硕士研究生 (??),是时候开始寻找新工作来开始接下来的生活了 (我知道我应该在我的最后一学期开始找工作,但我没感觉到准备好了)。我意识到我需要知道当前工作的职责、所需的软件技能、他们正在开发的产品或服务、薪资等等。因此,我开始手动浏览招聘平台上的职位列表,比如 Climate Base,因为我想在绿色技术/项目方面工作。从每一个当前的职位列表中找到这些信息会花费很长时间去阅读和整理。所以,我突然想到,既然我是AI时代的开发者,我需要一个反映这一点的项目,那么什么比一个网络爬虫+ChatGPT更好的开始呢!本文末尾有项目的Github链接。让我们从概述开始:
0. 定义一家工作平台并筛选出你想要的工作 1. 从每个 URL 中提取 CSS 元素 2. 为 ChatGPT3 创建提示 3. 逐步从每个工作清单中提取信息 4. 将信息整理成易于阅读的对象。
? 要求:
- OpenAI API(关注这篇文章获取更多详情)
- Python开发环境(我使用了Jupyter Notebook)
- Chrome扩展程序SelectorGadget用于检索CSS元素。
0. 定义一个工作平台,过滤出你想要的工作。
⚠️ 免责声明:本项目将不可避免地存在些许硬编码元素,专门用于从气候基地工作平台上爬取信息,因此可能会有些偏见。我没有在其他平台上测试过它,但我相信编码块可以轻松地重新用于任何工作平台上。但无论如何,请考虑绿色工作!它们是未来的方向!?

在我开发的解决方案中,有一些参数是我手动定义的。我意识到可以从URL中过滤出一些特定的条件。首先,我为不同的过滤器定义了一组感兴趣的筛选条件。比如说,对于职位角色,我只想寻找全职和实习的职位。或者是数据分析师、数据科学家或研究岗位等职位。特别是,我对可以远程工作的岗位非常感兴趣。这里还有更多的筛选条件可以找到并且您可以进行更改,但出于实际考虑,我只对上述筛选条件感兴趣。
#https://climatebase.org/jobs?l=&q=&p=0&remote=false
domain_name = "https://climatebase.org"
url_path = "/jobs?l=&q=&p=0&remote=false"
# Job types
#https://climatebase.org/jobs?l=&q=&job_types=Full+time+role&p=0&remote=false
d_job_types = {0:"", 1:"Full+time+role", 2:"Internship"}
# Role type
#https://climatebase.org/jobs?l=&q=&categories=Data+Analyst&p=0&remote=false
d_categories = {0:"", 1:"Data+Analyst", 2:"Data+Scientist", 3:"Research"}
# Remote
#https://climatebase.org/jobs?l=Remote&q=&p=0&remote=true
d_remote = {0:"", 1:"true", 2:"false"}
css_object_class = "list_card"对于每次运行,我都可以过滤出特定的组合。在这种情况下,我想找到可以远程工作的数据科学家全职工作。
job_types = d_job_types[1]
print("Job type: " + job_types.replace("+", ""))
categories = d_categories[2]
print("Category: " + categories.replace("+", ""))
remote = d_remote[1]
print("Remote: " + remote)Job type: Fulltimerole
Category: DataScientist
Remote: true1. 从每个网址中抓取CSS元素。
网络爬虫需要您在网页中识别CSS元素来检索所需的信息。如果您使用谷歌浏览器,有这个称为SelectorGadget的扩展程序,我用它来获取我想要检索的文本的CSS选择器。看以下例子:
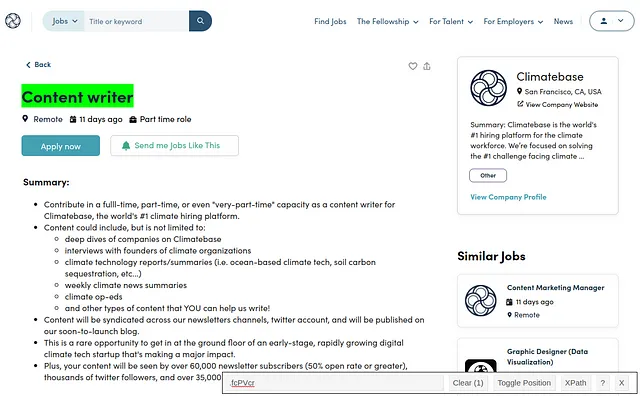
使用这个扩展程序,我只需指点一下…
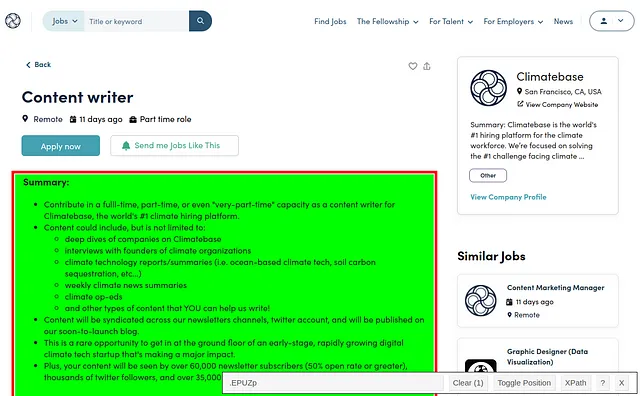
标题和工作描述是我从网页中获取的唯一元素。可以说,从这个网页中可以抓取更多的信息,但我觉得已经足够了,因为我使用了一些标准进行了筛选,已经获取了这个职位描述。
现在,在Python中,有一个叫做BeautifulSoup的库,它将到网络页面上寻找CSS元素并且取回它。我为此编写了一个通用函数。
def scraping_css_object(url_path, css_object_class):
"""
Given a CSS object class, this scraper will obtain the relevant information from the website.
"""
url = domain_name + url_path
#"https://climatebase.org/jobs?l=&q=&categories=Data+Scientist&p=0&remote=true"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# Find all elements with class="list_card"
found_objects = soup.find_all(class_=css_object_class)
return found_objects它的输入是工作列表的领域和您想要抓取的CSS对象。从网页中提取和格式化对象不是一个可泛化的任务,我花了一些时间来做,但是通过ChatGPT和几次尝试,测试成功了,我终于能够检索所需的信息了。例如,检索标题的特定函数如下所示:
def scrape_title(current_path):
"""
This function will obtain the job title from a predefined CSS object specific to
the ClimateBase.org website.
"""
html_title = scraping_css_object(current_path, "fcPVcr")
soup = BeautifulSoup(str(html_title), 'html.parser')
title = soup.find('h1', {'class': 'PageLayout__Title-sc-1ri9r3s-4 fcPVcr'}).text
return title2. 为ChatGPT创建提示语。
考虑使用大型语言模型(LLMs)可以完成的任务:情感分析,摘要,推断,转换,文本扩展以及作为聊天机器人。该项目需要从每个工作列表中提取信息,并将其组织成一些相关类别。这些任务属于推理和转换任务。我们希望LLM从一组类别中推断信息,提取它,并将其转换为相关格式(JSON)以便进行后续分析。
有两种提示:基本提示和指令提示。对于基本提示,您允许语言模型自由预测下一个最可能的单词。指令提示是一种更高级的提示,它根据一组指令设计而成,供语言模型遵循。该提示将不断改进和调整,直到结果符合您的要求。
我尝试了几次,但我找到了我所需的最佳提示。如果找到类别的信息,它将被保存在一个JSON对象中,键名为类别名,值为相关文本。如果找不到,则键名不变,但是值会反映其未找到。我犯的最大错误是我想让LLM对信息进行分类的JSON对象具有大小写不一致的键名,结果我得到了一个意料之外维度的混乱JSON对象。因此,在最后一次重新设计时,我制作了一个有趣的参数化字符串,可以使用更多或更少的分类进行更新。它看起来像这样:
def chatgpt_prompt(title, bodytext):
"""
This function contains the prompt with the set of rules that are to be sent to ChatGPT to process a text.
"""
categories = """
* Job title
* Company name
* Company mission
* Company values
* Company products or services
* Job responsibilities
* Desired software skills
* Education
* Required Job Experience
* Equal Employment Opportunity
* Salary
* Benefits
* Location
* Type of employment
* URL
"""
json_keys = [category.strip('* ').lower().replace(' ', '_') for category in categories.strip().splitlines()]
text_prompt = f"""I will prompt you with a job description contained within ```, and I want your help to extract and categorize its information. Before we begin, please follow these rules:
1. Replace any double quotes in the text with single quotes.
2. Extract and categorize the information from the job description for the following categories:{categories}
3. Please provide your answers in a JSON object format. The keys will be the same as the categories but in lower case and with spaces replaced by underscores. These are respectively and in order: {json_keys}.
4. Use a consistent structure for all data entries. Never create nested values. Separate them with a delimiter such as ";" instead.
5. If any category has no available information, please include a "null" value for the corresponding key in the JSON object.
6. Make the categorizations as concise as possible, maybe even as keywords. Be as economic as possible.
7. Avoid paragraphs of text or long sentences.
8. Avoid redundant text.
Please keep these rules in mind when categorizing the job description. Let's begin!:
""" + "```Job title: " + title + ".\n\n "+ bodytext + " URL: " + domain_name + current_path + " \n```"
return text_prompt
#display(Markdown(chatgpt_prompt(title, bodytext)))您可以随时查看URL以获取更多信息。
3. 从每个工作列表中迭代地提取信息
我曾怀疑是否每次为每个工作清单都放置提示和说明是一个好的做法。我的意思是,ChatGPT是一个聊天模型,如果我在开头定义指令集并说一些像“现在再次按照下面的工作清单遵循说明…”的话,会发生什么。为了澄清事情,我是指Isa Fulford和DeepLearning.AI的Andrew Ng的“ChatGPT Prompt Engineering for Developers”课程。

在课程中,他们实现了一条指令,正如我最初想的那样;他们确实重复了提取新文本信息的指令。课程后期,他们解释了聊天模型的结构,并展示了它需要所有先前提示的列表,这对我想要的任务是不实用和无关的,因此我有信心地说这个算法是正确的?。我在一个列表中保存了每个处理过的 JSON 对象。循环看起来像这样:
json_list = []
for current_path in scraped_url_paths:
try:
# Scraping job title
title = scrape_title(current_path)
# Scraping job description
bodytext = scrape_job_description(current_path)
# Redacting prompt for ChatGPT
text_prompt = chatgpt_prompt(title, bodytext)
# Calling ChatGPT
reply = call_openai_api(text_prompt, tokens = 1000)
reply = reply.replace("\n", "")
#reply = reply.replace("'", "\"")
json_object = json.loads(reply)
# Collecting JSON objects
json_list.append(json_object)
except:
continue4. 将信息组织成易于人类阅读的对象。
在上一步中的for循环会产生一个JSON对象列表作为输出。这个列表可以很容易地转换为其他格式。我决定先将它转换为CSV文件。
df = pd.DataFrame(columns=json_file[0].keys())
for i in range(len(json_file)):
y = pd.json_normalize(json_file[i])
# Patch:
y.columns= y.columns.str.lower()
df = pd.concat([df, y], ignore_index=True)
print(df.shape)
df.to_csv("{}.csv".format(filename), index=False, sep='~')此外,每个JSON元素都很容易显示到HTML中。
# Convert JSON to HTML
#json_object = json_file[0]
html_table = json2html.convert(json.dumps(json_object))
display_json_as_html = f"""
<div style="display: flex; justify-content: center;">
<style>
table {{
width: 60%;
border-collapse: collapse;
}}
th, td {{
padding: 8px;
border-bottom: 1px solid #ddd;
word-wrap: break-word;
}}
th:nth-child(2), td:nth-child(2) {{
width: 400px;
}}
</style>
{html_table}
</div>
"""
display(HTML(display_json_as_html))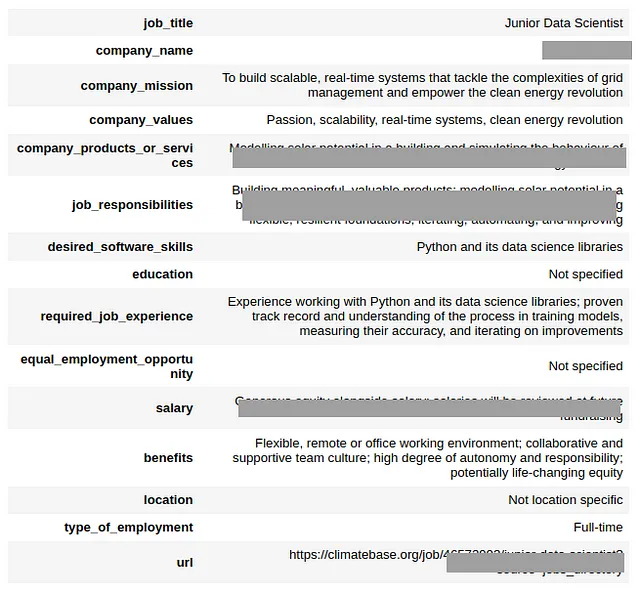
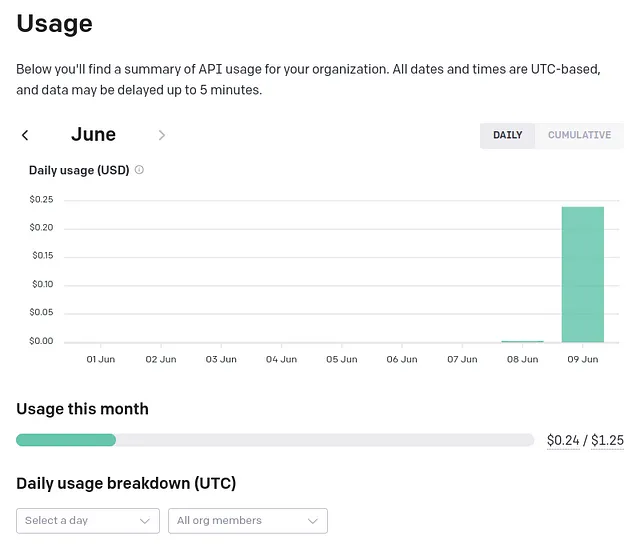
在经过一次小测试(0.03美元)之后的第二轮结束时,我花费了不到四分之一的时间将阅读和组织100个工作清单的责任委托给了ChatGPT。挺酷的,是吧?