语言模型(LM)是什么?
语言模型(LM)是一个概率模型,为token序列(单词、字符或子词)分配概率。语言模型的主要功能是提供一个概率分布,允许模型预测一系列单词出现在一起的可能性有多高。
这是更详细的工作原理:
语言模型如何生成文本?
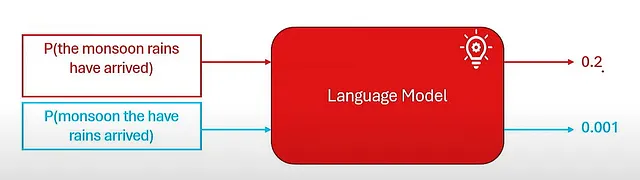
考虑一个标记序列{X1,X2,X3….XL}在词汇V中,那么一个词在“季风雨后”出现的概率可以通过使用以下等式确定,使用概率链规则如下:
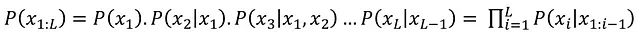
This is a cat. It has fur and four legs. It likes to sleep and eat fish.
让我们以“季风雨已经”这部分句子为例,并使用链式法则计算接下来的词X5发生的概率。假设:
- X1 = "这"
- X2 = "季风"
- X3 = "下雨"
- X4 = "有"
现在,序列“季风雨有X5”的概率由以下公式给出:
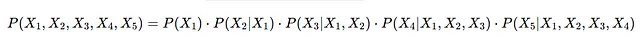
实际情况是这样计算单词X5在序列“季风雨已经”之后出现的概率:
P(X1): 第一个词是“The”的可能性。
P(X2 | X1):在第一个词为“The”情况下,第二个词为“monsoon”的概率。
P(X3 | X1, X2): 在前两个单词为“The monsoon” 的情况下,第三个单词为“rains”的概率。
P(X4 | X1, X2, X3): 给定前面的词是“季风雨”,第四个词是“有”的概率。
P(X5 | X1, X2, X3, X4): 给定前面的序列“The monsoon rains have”,下一个单词X5的概率。
Illustration with Next Word Prediction: 以下一个单词预测为例进行解释:
现在,假设我们想要预测“季风雨已经”后面的下一个词。我们会查看一个模型(比如语言模型)来计算:
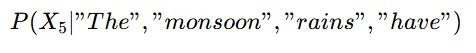
该模型可以为x5提供不同的选项,比如:
- 开始
- 减弱
- 导致
每个选项都会有一个相关的概率,并且具有最高概率的单词将被选为下一个单词。
例如:

由于“started”具有最高概率(0.6),模型会预测“started”作为下一个词。
参考资料
- 深度学习调查:从激活到变压器。https://arxiv.org/abs/2302.00722
- 一个关于课程内容、后勤、政策和背景的介绍 — 由Tanmoy Chakraborty在IIT Delhi教授的LLM课程。https://lcs2-iitd.github.io/ELL881-AIL821-2401/static_files/presentations/1.pdf
- NLP的演变:过去,现在和未来,由Pepper团队提供。访问链接:https://www.peppercontent.io/blog/tracing-the-evolution-of-nlp/