通往AI之路:通过人工智能助手实现更好的商业智能
概述
继续我们的系列“通往AI之路”,我们探索让各种规模的企业更轻松接触AI的方式。我想分享如何计划利用ChatGPT这样的大型语言模型(LLMs)来创建AI助手。这一套生成式AI聊天机器人帮助产品和业务团队以更具对话性的方式获取数据洞察,与现有的仪表板和报告相辅相成。我们的目标是通过AI提供简单、按需、灵活的数据访问,并通过AI增强业务智能能力。
本文概述了我们如何使用Snowflake的Cortex AI和笔记本电脑开发一套AI助手的概念验证(POC)。这些助手将通过提供更快速,更灵活的方式访问数据来解决我们业务团队的痛点。
愿景
随着我们公司向更加以产品为导向的文化转变,对数据的快速灵活访问的需求变得日益重要。我们的人工智能数据助手旨在应对这一挑战,实现自助式数据探索和报告。虽然像Tableau这样的传统BI工具已经奠定了坚实的基础,但任何参与分析或数据团队的人都知道一旦启动了仪表板,业务部门的问题就会如潮水般涌来。这经常会造成瓶颈,因为我们匆忙地将所有必要的答案整合到这些仪表板中。结果,复杂性可能会让用户不知所措,使他们难以获取有意义的见解。
我们的新人工智能助手通过提供即时、对话式访问数据改变了游戏规则。这使用户可以以自己的步调获取洞察力,深入挖掘数据,甚至在选择时探索那些引人入胜的数据深渊。我们的目标是为每个数据集(电子邮件营销指标、客户关怀指标、产品指标、财务等)建立一个数据助手,最终的目标是结合所有这些,构建一个坚实的数据集,可以回答有关我们公司数据的所有问题。
用户界面和功能
我们基于人体工程学设计的AI数据助手,确保用户体验,确保数据访问尽可能直观和简单。用户可以登录到我们的Snowflake账户与这些聊天机器人互动。进入后,他们会受到助手可以帮助的简要概述,包括访问的数据类型和可以回答的问题类型。这为从一开始就实现无缝互动奠定了基础。
主要特点:
- 引导性介绍:用户会收到一个简洁的助手功能描述,概述可用的具体数据和他们可以提出的查询类型。这有助于用户快速了解如何最大程度地与助手互动。
- 用户信息存储:系统收集每个用户的姓名和部门。这些信息对于后续跟进非常宝贵,确保我们能够在需要进一步澄清或协助时联系到他们。
- 动态响应:助手以清晰的表格格式提供答案,不仅可搜索,还可下载为CSV文件。此功能使用户能够根据需要轻松操作和分析数据。
- 可视化:在适用的情况下,助手提供折线图和柱状图来直观地展示数据,让用户一目了然地了解趋势和洞察力。
- SQL查询透明度:每次助手检索信息时,它会生成并显示用于提取数据的SQL查询。 这种透明度允许用户在希望的情况下验证查询,从而促进对数据检索过程的信任和理解。
- 客户反馈机制:为了持续改进用户体验,我们已经引入了一个带有点赞和点踩选项的反馈系统。这使用户可以快速指示所提供的信息是否有帮助,促进助理表现的持续改进。

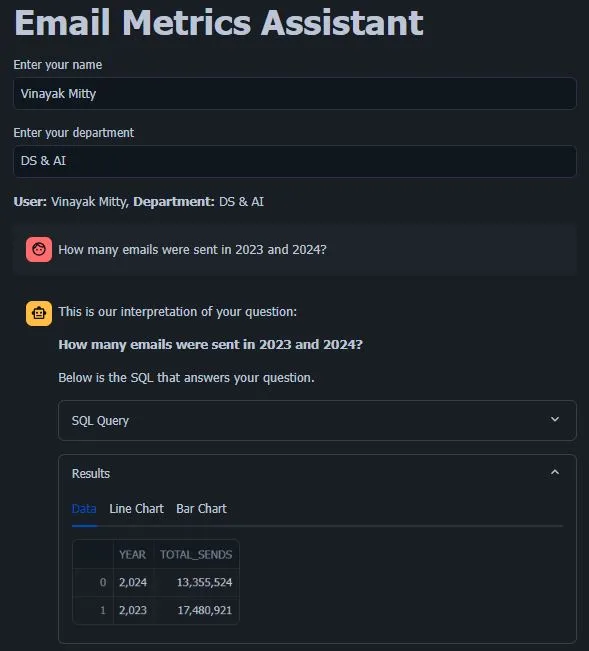
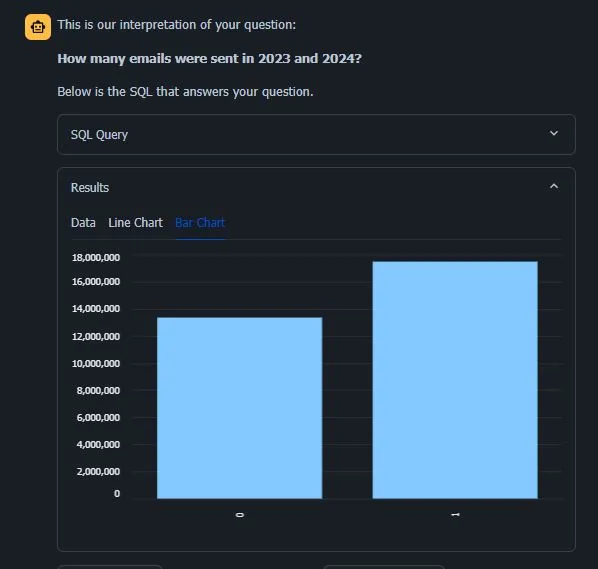
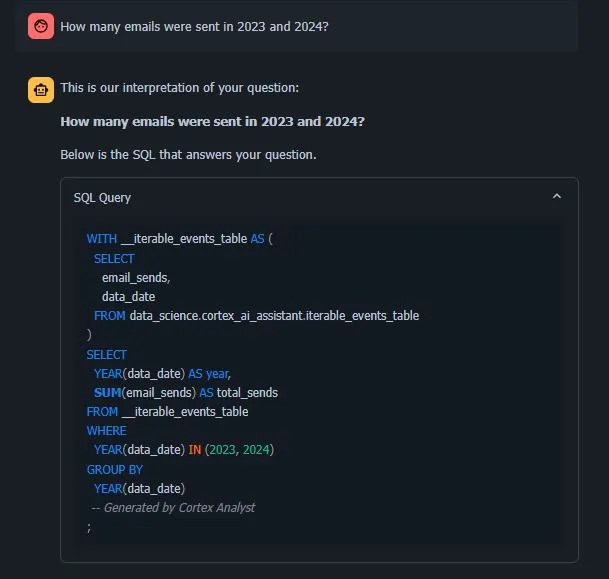
用户界面本身是作为一个Streamlit应用程序构建的,它提供了简洁且响应灵敏的设计。此外,Streamlit的灵活性使我们能够利用Python增强和定制这些功能,为未来的文章提供了改进的空间。通过这些贴心的设计元素和功能,我们的AI数据助手旨在创建一种引人入胜且高效的数据探索体验。
多智能体架构
为了确保我们人工智能数据助理的效力和可靠性,我们开发了复杂的多代理体系架构。这个架构由三个关键组件无缝地共同工作组成:
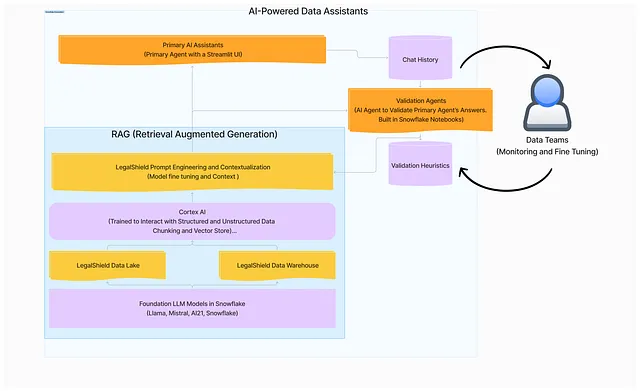
- 主要AI代理:这是用户直接互动的接口。它处理用户查询,并根据提供的输入检索相关数据。主要代理被设计为能够理解自然语言,并以对话方式进行回应,使数据探索直观且用户友好。
- 次要验证代理:作为一种保障,该代理会重新运行提交给主要AI代理的相同提示。通过独立验证回应,它确保所提供的信息一致准确。这种额外的验证层对于保持数据洞察的完整性至关重要。
- 比较的Python脚本:一个专门的Python脚本分析主要和次要代理的输出。通过比较两组答案,它验证了响应的准确性和质量。该脚本还围绕发现构建启发式,帮助持续改进助手的性能和可靠性。
除了这些组件之外,我们还将聊天记录存储为我们基本的“人在循环”框架的一部分。这使得我们的分析师和数据团队能够监控互动并根据需要微调模型。通过利用这种多代理架构,我们确保我们的AI助理提供高质量见解的同时,也提供了持续改进所需的灵活性和适应性。
挑战
当然,并不是一切都是美好的。随着我们深入进行这一倡议,我们正在应对一些挑战,特别是在应用检索增强生成(RAG)和语义建模技术以获得期望的结果方面。从大型语言模型(LLMs)中获得一致结果是一个正在进行中的工作,我们正在积极学习如何优化这些方法。
我们面临的主要挑战之一是应对幻觉问题——即AI生成不正确或荒谬信息的情况——并确保准确性。准确性是我们的主要关注点,因为我们希望我们的商业用户能够信任这些助手提供的数据。为了建立这种信任,我们正在训练模型,在不确定时避免回答问题,有效地把可靠性置于数量之上。
在接下来的文章中,我将深入探讨这些挑战的技术方面,我们正在实施的应对策略,以及我们如何不断改进我们的方法来增强我们的AI驱动的数据助手的性能和可靠性。
资源
- 雪花皮质用于生成式人工智能
- 开始使用Cortex Analyst:用AI增强商业智能
- 使用Streamlit和Snowflake Cortex构建基于检索增强生成(RAG)的LLM助理