技术观点:为什么您不应该依赖ChatGPT
ChatGPT发布后震惊了全世界,并引发了有关生成人工智能(genAI)的热潮。而这种热潮并非毫无根据——它的益处很容易被很多人识别。从生成论文和旅行行程到编写代码。每个人都开始跟风。但尽管它有很多好处,我们仍应该谨慎对待——它并非完美。要了解genAI背后的一些缺陷,我们首先需要了解它的工作原理。
GenAI 模型根据统计模型产生输出,分析输入元素并识别潜在的模式和可能的输出。例如,基于文本的 GenAI 模型如 ChatGPT 是在大量文本数据集上进行训练,试图推断下一个可能的字符或单词是什么;而基于图像生成的平台将在图像(像素)上进行训练,尝试在生成输出时确定下一个像素应该是什么颜色。生成的输出即使对于开发这些模型的工程师也是一种黑盒。即使训练数据是100%准确的,数据可能并不涵盖一切,因此最终会进行假设并尽量猜测生成响应。这导致了第一个问题,幻觉。
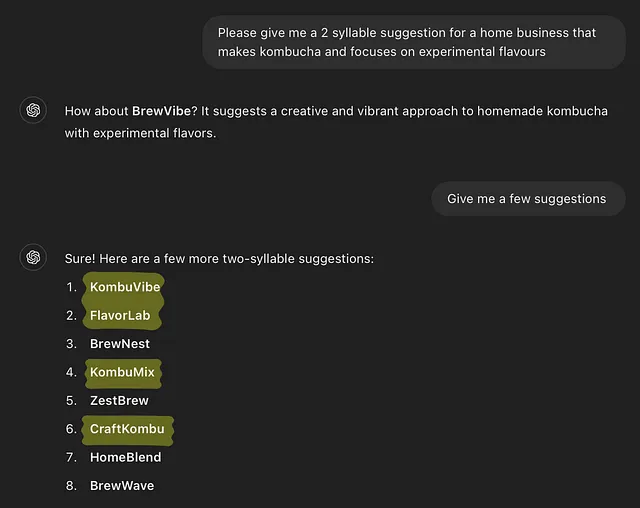
由于这些模型仅仅试图预测下一个最佳正确输出,它们缺乏理解人类用户提出的问题背后的语境的能力。对于提出的问题没有逻辑推理。因此,响应可能不是最准确的,甚至可能包含错误信息。总的来说,幻觉可能包括各种不准确之处,从矛盾、错误、到毫无意义的回答。现在流行的一个幻觉可以在Reddit帖子中看到,ChatGPT一直在错误地计算单词“草莓”中字母'r'的数量。在这里你可以看到更多幻觉的例子。过度依赖这些响应作为绝对真理将会有害。举个例子,最近我做了一个搜索,一半的建议甚至没有2个音节,尽管我明确要求了,而ChatGPT也承认了这个请求。
话虽如此,genAI 模型正在不断改进[2],随着时间的推移,幻觉的发生可能会减少。但只要模型不是100% 准确,我们必须始终验证我们的信息来源,并在接受 genAI 响应作为终极真相之前进行交叉参考。
其次,genAI模型可能容易受到偏见的影响。这些模型只有所训练数据的好坏。如果数据本身存在偏见,可能会导致输出结果同样带有偏见。例如,考虑一下替代性制裁的矫正罪犯管理系统(COMPAS)--黑人被错误地认定有44.9%的概率再次犯罪的风险,而对于白人个体而言,这个比例是23.5%。这意味着算法几乎有两倍的机会错误地对黑人进行定罪,可能会持续推动种族偏见的存在。虽然COMPAS不是genAI工具,但同样存在这个限制。尝试理解这些模型也是genAI面临的问题,因为这些模型往往复杂而混乱。即使我们揭示和更好地理解这些模型,也会涉及更大的风险,从而产生AI透明度悖论。透露这样的信息可能导致漏洞攻击。
此外,还有许多其他相关(伦理)问题,比如深伪造[6]或genAI图像模型的版权问题[7],但这将导致一篇篇幅较长的文章。genAI的问题不仅仅停留在模型本身。它们也对我们构成风险。过度依赖这些工具可能导致我们的创造力和批判性思维受到抑制,因为我们不会思考得太多,可能会刺激我们的大脑,也不会验证来源,确保回应是事实正确的。这可能导致更广泛和迅速传播错误信息。
但所有希望并未失去-如果正确使用,genAI仍然可以有用。 这些工具可以帮助我们简化和加快工作,并且在学习方面提供帮助,前提是不要滥用它们。 它们应该与人类的努力相辅相成。 只要我们意识到它们的局限性和偏见,就可以做到这一点。 我们应该积极参与验证genAI工具的响应,并行使道德意识和责任。 也许那时,我们将能够克服与这些工具相关的风险。