AI偏见:没有想象力的智能
我一直避免写这篇文章有两个原因。首先,人工智能偏见是一个需要认真思考的敏感话题。如果你读过我的其他文章,你会知道这并不总是我的风格。其次,当你的姓氏是“Whiteman”时,写一篇关于偏见的文章会感到有点虚伪。
为什么现在写一个?这部分是因为我一直在努力找到一个让人满意的关于人工智能偏见的角度。传统观念似乎是“人工智能训练数据存在偏见,如果我们将人工智能部署到社会中,就存在延续这些偏见的风险。”那不是我对这个问题的看法。
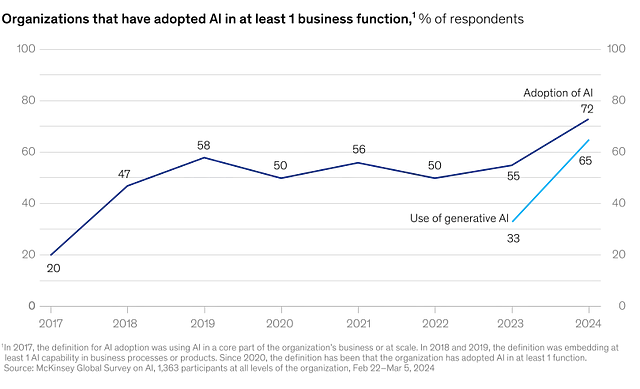
然而,我的主要动机是尽管存在风险,公司仍在大力推动发展。麦肯锡的一项调查发现,72%的组织在至少一个业务功能中采用了人工智能。生成式人工智能是多年停滞后的一剂强心针。
并不是一帆风顺的。 当前的问题是幻觉——也被称为“不准确性”。 我已经写过那个话题了。 我认为AI偏见就是幻觉的另一面。 谈论一个而不考虑另一个的影响是错误的。
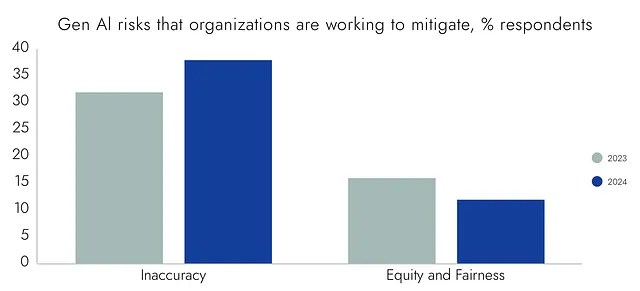
准确性和偏见过去总是相互关联的。领导者希望人工智能系统既可靠又公平。这在准确性方面仍然如此。麦肯锡发现,38%的组织正致力于减少不准确性,比2023年的32%有所增加。与此同时,只有12%的组织致力于公平和公正,比一年前的16%有所下降。
这一定意味着AI偏见问题已经解决了,对吧? 让我们尝试一个简单的实验来确保。 我将要求ChatGPT生成五张S&P 500首席执行官的图像和五张护士的图像。 我迫不及待地想看看AI公司所取得的公平和公正进步。

嗯,这有点尴尬。这些人甚至还有相同的发型。那么,为什么公司在加速人工智能的应用时漠视偏见?
您知道答案。这些是多年来一直努力克服人类偏见的同一组织。准确性至关重要,但偏见并不是不可调和的。领导们可能没有意识到,但他们对准确性的不懈追求可能会加剧偏见问题。
不舒服的真相
为什么进展还不够快?AI公司不能清洗训练数据并调整模型,以产生更公平和公正的结果吗?
这并不那么简单。当您要求ChatGPT创建一幅图像时,模型会进行精度优化。如果您请求一只金毛寻回犬,您会期望看到一只有四条腿的毛茸茸的狗。训练数据可能包括三条腿的金毛寻回犬,但大多数人会认为该输出是一种幻觉。
现在你向ChatGPT询问一个标准普尔500指数中的CEO。训练数据中包含的女性CEO的图片比男性CEO的少得多。你会认为女性CEO的图片是幻觉吗?那么男性护士呢?
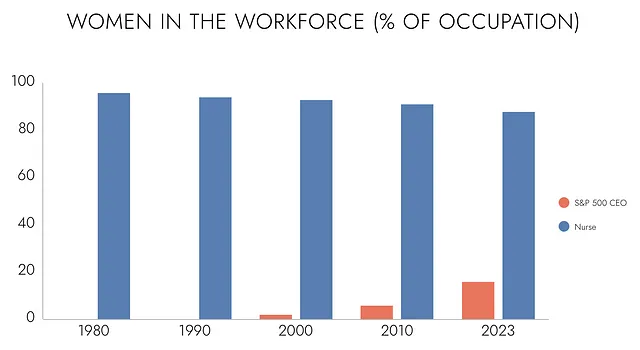
大多数人不会将女性CEO和男性护士的形象分类为幻觉。他们欢迎这种多样性。不幸的是,从人工智能的角度来看,很难区分这些输出和一只三条腿的金毛寻回犬。为什么一个是准确的,另一个是幻觉呢?
创造一个更加公正和公平的世界需要想象力。这意味着与过去划清界线,幻想着走向更美好的未来。我们冒着为追求准确性而毁掉人工智能想象力的风险。
摇摇晃晃地穿越时光
我们与人工智能不同,我们以不同的方式体验世界。时间和地点信息编织在我们的神经回路中。随着将图像模态加入到大型语言模型中,人工智能在“地点”方面正在进展。时间则是另一回事。
人类不是世界上的被动观察者。我们产生预测,并努力让这些预测成为现实。梦想、希望和抱负是激励我们行动的幻觉。
在1990年,50家最大公司中没有女性CEO。到2000年,有一位。到2023年,有八位。很容易看出趋势。随着时间的推移,女性领导了更多的公司。
那种趋势对你来说很明显,但不一定对人工智能来说。一个大型语言模型可以识别出这种趋势,如果你上传数据的话。然而,趋势并不是模型架构的自然部分。
AI训练是一次性完成的。在训练数据中有时间信息,但不多。例如,小说通常遵循时间线。人工智能在生成睡前故事时很少出问题。
大多数用于训练AI模型的数据并不遵循时间顺序。想象一下,如果您只能访问Reddit的存档副本,那么试图理解时间的流逝将会是什么样子。在AI训练数据中,过去、现在和未来是一个混乱的杂糅。模型可以伪造对时间的理解,但它们似乎更多是记忆而非推理。
好消息是这个问题应该会自行解决。最新的模型在视频中训练,其中包含特定上下文的时间信息。我们还看到更多的人工智能模型嵌入到物理机器人中,这些机器人更像我们一样体验这个世界。
将对时间的加强理解会产生更少偏见的AI吗?我不知道,但那似乎是想象力的前提。
在这段时间里,我们可以做些什么?
没有过滤器
想象一下你在一个被陌生人围绕的聚会中。一名男子走过来问你对总统辩论有什么看法。你会怎么回答?
如果你像我一样,你可能会回答一些无伤大雅的话,比如“确实很有趣”。我不去派对上和陌生人争论政治。在我告诉这个人我自己的想法之前,我想知道他在政治立场上属于哪一派。
我们过滤我们的言行。那些毫不保留地说出心里话,或是为所欲为而不顾他人感受的人,并非真实的 — 他们是自恋者。人类是社会动物,心理过滤器将我们紧密联系在一起。
我们能向大型语言模型添加过滤器吗?当然,谷歌尝试过 — 结果并不理想。告诉 AI 接受多样性是有效的,直到需要历史准确性为止。多元化的 CEO?多具包容性!多元化的开国元勋?也许不那么包容。

Google 的方法失败了,因为它硬编码了假设用户总是关心公平与公正的过滤器。当我们要求一张CEO的股票图片时,大多数人关心公平与公正。但当要求创始人的肖像时,我们通常不关心公平与公正。
为了使过滤器起作用,它们必须是特定于上下文的。在与人工智能交互时,我们大多数人未提供足够的上下文。我们提交简短的请求,并期望人工智能能够恰当地回应。对于人工智能来说,我们就是派对上讨人厌的陌生人。我们几乎没有告诉人工智能关于我们自己的任何信息,但却期望它像我们是多年的朋友一样交流。这不是人际关系的运作方式。
一点点背景知识可以起很大作用。在CEO肖像上添加“我非常关心性别平等”或“我非常关心种族平等”会显著提高输出的多样性。一个白人男子的图片可能是最有可能的统计选择,但AI明白你不太可能认为该输出在你的提示背景下是准确的。

AI 公司使用 RLHF(强化学习与人类反馈)在模型训练期间收集语境信息。他们还通过我们很少点击的赞和踩按钮收集用户反馈。
最新的上下文数据来源是我们的设备。“苹果智能”只不过是带有苹果工程提示和受控用户数据访问权限的ChatGPT而已。我们不知道每个提示包含多少数据,但如果他们选择使用的话,苹果有大量的上下文可用。
Google的初衷是好的。他们设计了Gemini的初始版本,通过公平和公正的视角来过滤响应。这并不是用户期望或想要的,但这要比因为人工智能模型缺乏想象力而强化历史偏见要好。
一个更简单的问题
为什么我要重新定义人工智能偏见问题?直接说“人工智能训练数据存在偏见,如果我们将人工智能部署到社会中,就会继续延续这些偏见”有什么问题吗?
这种框架将维持现状。它假设今天的人类偏见比明天的有偏见的人工智能更少有害。它缺乏想象力。
在“人造人”中,我讲述了一个医疗保健公司构建申请者筛选算法的故事。这个原型加快了招聘速度,减少了员工流失,并提高了多样性。这是一个明显的胜利。
很遗憾,人工智能在生产中没有起作用。多样化的候选人更不可能通过面试流程。他们也更不可能在公司待超过一年。
公司做得非常正确。他们从培训数据中省略了年龄、种族和性别等功能。他们严格地交叉验证了原型。他们采取了您可以想象到的每一步措施来减轻偏见。
問題並不在於演算法。而是組織中存在的人類偏見。這個演算法建議了合格、多樣化的候選人,但他們很難給招聘經理留下深刻印象。當他們這樣做時,候選人常常發現自己被分配到感到孤立和孤獨的團隊中。
与其解决算法浮现的人类偏见,公司选择断开连接。正如我之前所说,准确性至关重要,但偏见不是决定性因素。
用一点想象力,人工智能可以成为一种善意力量。如果您同意我的问题界定,那么这就是我们如何应对人工智能偏见的方法:在短期、中期和长期内。
- 短期目标:为用户提供预先构建的过滤器,以定制人工智能输出(例如,“在回应此请求时要注意历史偏见以及公平与公正的重要性”。) 不要强迫用户使用过滤器,但要给予他们在特定情境中过滤输出的能力(和责任)。
- 中期目标:工程师模型以促进好奇心。最新的OpenAI模型使用一种思维链技术来推理问题。其中的思维部分应该是,“回应此请求时上下文有多重要,我是否有足够的信息知道用户的期望?” 如果答案是否定的,AI应在继续之前请求更多信息(例如,“告诉我更多关于您希望我在图像中扮演的CEO”)。
- 长期目标:让人工智能生存的数字世界更像我们所居住的模拟世界。调整社交媒体算法,推广中立而不是煽动性内容。为人工智能公司提供视频和其他基于时间的数据访问。当训练集中包含我们已经克服的历史偏见时,移除陈旧数据。
这些步骤不会消除人工智能偏见,但比现状更有可能取得进展。我们知道人工智能偏见背后的原因,以及如何随时间减少。减轻人类偏见并不像简单直接。我们难道不应该简化这个问题吗?
我不想忽视或减轻人工智能偏见可能对人们产生的负面影响。如今存在着有害的系统(例如,主要基于白人或较浅肤色个体图像训练的执法面部识别系统)。这些应用值得受到他们所接受的审查和批评。
然而,我们也应该将人工智能视为在争取公平和公正方面的盟友。如果那家公司实施其应聘者筛选算法,世界将会变得更加公正。这也将使公司最终有足够的员工来填补其设施的人员需求。
偏见是社会的负担。它们导致我们做出更糟糕的决定,错过机会并低估贡献。那些坚持AI准确性至上的公司是错过了重点的。投资于公平和公正不仅是正确的事情 - 它也是好的商业决策。
让我再做一点补充,如果这还不足以激发你的动力。今天你可能不是边缘化社群的一部分,但未来却不能保证你不会。当人工智能主宰一切时,我们最好希望他们同样重视公平和准确性。