在HPC上运行web服务?愚蠢吗?
或者有些用例能够从永久的slurm中受益吗?
那么,如果您想提供一个需要大量计算能力的长时间运行的后端网络服务,但是您组织中所有强大的机器和配备GPU的机器都安装在只允许提交批处理作业的高性能计算(HPC)系统中,您该怎么办?
你面临着两个问题:
- HPC批处理系统可能仅允许您运行作业几个小时,或者几天,然后就会终止它,或者是因为其他的高优先级作业出现了而随时终止它,这样您的网页前端或客户端过程将无法再使用后端。
- 在高性能计算系统上,强大的计算节点通常隐藏在一个被称为“登录节点”的网关节点后面。您可以访问登录节点,但只能从那里看到计算节点,而不能直接从您的 Web 服务器或客户端进程访问。
那么,我们在谈论哪些用例?例如,许多组织不允许使用ChatGPT或其他基于云的人工智能系统,而希望构建自己的本地Chatbot。为此,您需要一台配备GPU的强力推理服务器来托管一个开源大型语言模型(LLM),例如Llama。但如果您所有的强力机器都在HPC系统中,您可以做些什么?
forever-slurm通过使用一个称为Traefik的负载均衡代理解决了这个问题,该代理位于登录节点上,并将流量路由到当前运行适当作业的一个或多个计算节点。forever-slurm将提交尽可能多的作业到集群中,以创建一个稳定的环境,保证至少有一个节点始终运行着适当软件。
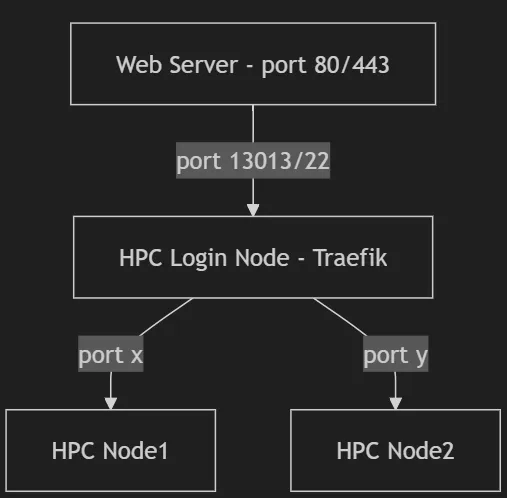
有一些更多的内容,比如保持一些元数据,告诉Traefik要使用哪些节点和端口,并确保属于同一服务的进程不会最终在同一计算节点上,以确保一定级别的高可用性。您可以在几秒钟内运行forever-slurm准备好;只需执行设置脚本 ./config.sh。
现在,您可能会认为这是个滑稽的主意,因为巨大的Llama 3.1 405B型号将阻止类似6 x A100 GPU,每个80GB,用于LLM推理服务器,而大部分时间都没有做任何事情。这相当于一个价值150,000美元的机器处于闲置状态!那怎么办呢?嗯,一个解决方案可能是在HPC集群外购买一个价值150,000美元的独立服务器。这样做有两个好处:
- HPC系统管理员和HPC指导委员会感到更加满意,因为他们关心的系统中一个低效的流程已被移除。
- 整个组织的低效率进一步增加,因为现在我们看到这台机器将会更加空闲,因为它永远也无法用于其他计算。
这显然是一个Verschlimmbesserung。我们该如何克服这个问题呢?我们知道企业HPC系统的某些部分始终空闲;事实上,平均利用率达到80%或更高的系统就已经很忙碌了。然而,大多数HPC系统都有一个选项,即在高优先级批处理作业出现时,暂时提供剩余资源,只要您允许系统将这些资源拿走。您只需要为作业添加“可抢先”选项,这是您的HPC系统管理员可以为作业队列设置的内容。有了这个功能,forever-slurm可以在HPC系统上抓取空闲周期,并确保始终至少有一个计算节点正在运行,Traefik可以将流量路由到该节点。