揭示ChatGPT:AI聊天机器人的内部运作并不神秘
用一个有用的乐高类比来解释!
揭穿迷思
您可能已经听说过“ChatGPT”——这是一种人工智能工具,帮助您轻松完成繁琐的任务,校对给老板的电子邮件,或者仅仅通过其“人类化”的语音让您赞叹。但ChatGPT实际上了解任何东西吗?它是有感觉的吗?它能解决您的所有问题吗?(剧透——不行)
作为最近毕业的学生,我估计我认识的至少70%的学生都使用过某种形式的大型语言模型(LLM)或生成式人工智能工具。这些技术在2023年爆炸式增长,并且ChatGPT在两个月内达到1亿用户,迅速成为许多人工作流程中不可或缺的工具。然而,我很快意识到很少人真正理解这些工具的功能或运作方式。当我的班上学生们假设ChatGPT是一个无所不知的实体,可以解决他们最大的困难——第三级微积分作业时,情况变得更加明显。让他们惊讶的是,他们得到了糟糕的成绩,甚至被抓到抄袭。在OpenAI于2022年推出ChatGPT时使用的模型GPT 3.5,在撰写论文和解释文本方面表现出色,但在高维微积分或复杂推理方面却表现不佳。
那么,ChatGPT究竟是什么?把它想象成一种高度复杂的类固醇自动补全,或者是铁甲奇侠中贾维斯的基础版。ChatGPT是OpenAI开发的大型语言模型,旨在理解并生成类似人类的文本,根据其接收的信息。其主要目的是在与您互动时尽可能自然地协助、提供信息甚至娱乐您。
让我们澄清一点:ChatGPT并不像我们人类那样“思考”或“理解”。它不是在数据库中查找答案或读取你的心思。相反,它是一台文本预测机器。当你键入一个问题时,它利用大量数据中的模式猜测序列中最有可能出现的下一个词。这些数据来自书籍、维基百科文章、Reddit(这绝对没错),以及数百万其他文本来源。通过这些,LLM学会了词语通常是如何跟随彼此的,可以构建有结构的答复来回答你的问题。但这个过程究竟是如何进行的呢?
关键词: 变形金刚
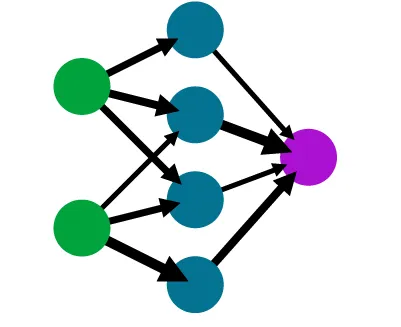
变形金刚是一种神经网络架构,自2017年谷歌发表的名为“注意力就是一切”的研究论文以来,在自然语言处理领域改变了游戏规则。神经网络的简要解释:受人脑启发的计算机系统,由相互连接的节点(如神经元)组成,传输和转换数据。这些节点使用称为“权重”和“偏差”的参数进行调整,这些参数确定节点之间相互影响的程度。通过微调和调整这些参数,网络学习识别数据中的模式并进行预测。
下面的图片展示了一个神经网络,节点用不同颜色的圆圈表示,箭头表示节点之间的权重和偏差。你可以看到箭头的大小不同,每个都代表着节点之间不同的影响。这种可视化简化了神经网络逐层处理数据的过程,调整权重和偏差以做出更准确的预测。
变形金刚通过允许语言模型关注句子的不同部分来改变游戏,从而理解单词之间的关系 —— 使用一种叫做注意力的东西。想象一下你在派对上与朋友聊天,但有人在远处提到了你最喜欢的电影。突然间,你的大脑更专注于那个遥远的对话,同时仍然保持对朋友说话的某种意识。变形金刚做了类似的事情 ——他们应用注意力机制来决定句子中哪些词值得最多关注。
在变压器中,每个句子中的每个单词都同时被处理,使模型能够一次考虑句子的所有部分。这比旧模型更高效,旧模型一次处理一个单词。通过这种方式,变压器根据彼此的相关性调整与每个单词相关的权重和偏差,有效地学习哪些单词在特定上下文中更重要。让我们学习在诸如ChatGPT的LLM中如何使用这些变压器。
逐步指南:ChatGPT如何处理和生成文本
让我们逐步通过 ChatGPT 的逻辑进行漫步,以乐高作为一个有用的比喻!
- 标记化:分解
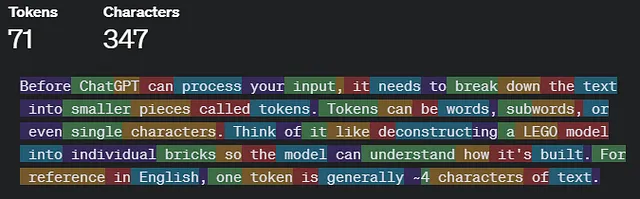
在ChatGPT可以处理您的输入之前,它需要将文本分解为称为标记的更小的部分。标记可以是词、子词甚至是单个字符。可以将此视为在开始构建之前倒出一个乐高积木盒子。每个积木(标记)都是将对最终模型有所贡献的基本部分。
作为参考,一个令牌通常是~4个字符的文本。
2. 嵌入:进入数字领域
一旦进行标记化,每个标记都会转换成一个称为嵌入的数值表示。想象为每个乐高积木贴上描述其形状、颜色以及如何与其他积木连接的独特代码。这些嵌入使模型能够以数学形式“理解”单词的上下文和含义。
例如,这就是模型知道‘国王’和‘皇后’比‘香蕉’和‘皇后’更密切相关的方式。类似于按照类型和功能整理乐高积木一样,这个‘嵌入空间’捕捉了输入中标记之间的关系和模式。
3. 应用权重和偏差: 决策工具箱
现在,让我们回到权重和偏差!在将文本转换为标记然后转换为数值嵌入之后,ChatGPT将它们馈送到神经网络中,它们通过多个‘层’ — 将这些层想象成构建过程中的不同阶段。
想象一下,你正在遵循一本复杂的乐高指导手册。权重就像指导你哪些积木应该连接到哪些的说明一样。有些连接更重要(比如连接基础块),而其他的是次要细节(比如在顶部添加一个旗帜)。权重决定每个“乐高积木”(令牌)应该如何影响下一个。
但有时,各部分并不完美契合,或者您需要调整以保持稳定。这就是偏差发挥作用的地方 - 就像您为了确保结构稳固而做的额外微调一样,即使原始说明没有考虑某些问题。偏差有助于微调模型的输出,引导其改进预测,无论输入如何,就像确保最后的砖块完美地放在顶部一样。
当ChatGPT训练时,它不断调整这些权重和偏差,以更好地理解标记之间的模式和关系。随着时间的推移,它学会了哪些组合(或连接)会产生准确的结果,从而使其能够在每个新查询中生成更准确的预测。
4. 自我注意机制:关注重要的内容
记得我们谈过的注意力机制吗?这就是它真正发光的地方。自我注意机制允许模型一次考虑所有令牌之间的关系,而不只是一次关注一个单词。就像进行对话并能够回忆起到目前为止所说的每个单词,理解每个单词是如何与其他单词连接的。
例如,在句子“The cat sat on the mat because it was tired.”中,模型需要弄清楚“it”指的是“the cat”,而不是“the mat”。注意机制通过为相关单词分配更高的重要性(权重)来帮助建立这些联系。就像你,乐高积木建造者一样,本能地知道车轮连接到轴上。你理解这些部件之间的关系,这种理解有助于你最终建立整个套装。
5. 通过Transformer层进行处理
令牌及其调整后的嵌入通过多个变换器层。在每一层中,模型通过重新应用注意力机制和相应地调整权重和偏置来完善对上下文和单词之间关系的理解。
将每个变压器层视为乐高搭建中的一个新阶段。在每个阶段中,您需要重新评估结构,进行调整,添加新的部件,同时保持整体设计的思路。这种迭代过程有助于确保最终模型具有连贯性和良好的结构。
6. 生成响应:把所有元素结合起来。
经过所有层的处理后,ChatGPT 生成下一个令牌(单词或子词)应该是什么的概率。基于这些概率,它选择最有可能的下一个令牌,并继续这个过程,直到形成一个完整的回应。
这就像一块一块地搭建乐高模型,根据之前的每块积木来选择每块积木,以达到一致性和相关性。结果是一个感觉自然和在背景下合适的结构 - 就像ChatGPT的回答旨在在对话的语境中讲得通一样。
在所有这些步骤中,有大量的线性代数、向量和复杂的数学运算以极高的速度计算信息,但这只是 ChatGPT 后端发生的极其简单的版本!如果你对更深入的分析感兴趣,我强烈推荐观看这两个视频:
如何 ChatGPT 技术上为初学者工作(youtube.com)
ChatGPT完全解释(YouTube.com)
从人类反馈中学习强化学习
在使ChatGPT的回复不仅连贯,而且有用、准确且符合人类价值观方面,还有另一个关键组成部分 - 这就是人类反馈的强化学习(RLHF)的作用。虽然该模型可以生成结构良好的句子,但其初始训练并不总能保证回复在事实上是正确的、有用的或安全可靠的。这就是人类反馈发挥关键作用的地方。
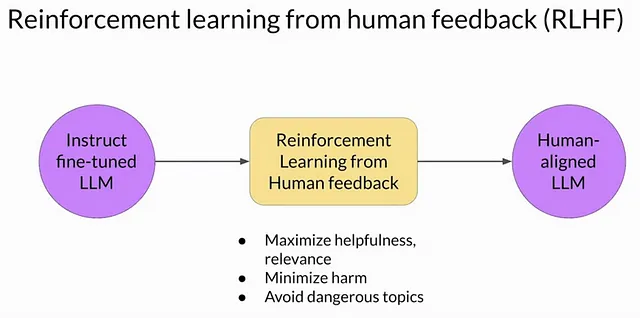
把它想象成一个LEGO Masterbuilder帮助一个初学者改进他们的项目。初学者可能会遵循基本的指导并组装出一个体面的东西,但是大师知道当部件不太合适或需要微调以使模型更加强壮和功能更强时。 类似地,人类审阅员与ChatGPT互动,根据准确性和有用性对响应进行评级。
这些排名会训练一个奖励模型,指导ChatGPT学习哪些回答人类更喜欢。随着时间的推移,这种微调过程有助于该模型生成不仅连贯,而且也符合人类价值观如真实性和实用性的答案。在一个Masterbuilder指导ChatGPT的步骤和告诉它“什么是错的”与“什么是对的”的情况下,它能够提供与人类判断一致的最佳答案。
机器的限制
虽然ChatGPT非常强大,但它也有局限性。首先,ChatGPT并不理解它生成的文本 — 它是一个文本预测机器,基于从大量数据集中学习到的模式、权重和偏见来进行回应。这意味着它有时可能会产生事实不正确的信息,或者生成看起来自信但具有误导性的答案,这种现象被称为“幻觉”。

这些幻觉发生是因为ChatGPT不像人类那样处理信息。它并不真正理解上下文或含义,而是根据训练数据中的模式预测句子中的下一个单词。虽然这通常导致连贯和相关的回答,但有时它会产生听起来合理但完全不准确或虚构的内容。
ChatGPT的另一个关键局限性是它的记忆。该模型一次只能处理一定数量的信息,称为其令牌限制。例如,早期版本的ChatGPT可以处理大约2048个令牌(大约相当于1500个单词)。随着对话变得越来越长,模型会忘记交互早期部分的内容,导致可能忘记重要的上下文,导致似乎不合适或重复的回复。
这就是更近期的模型,例如GPT-4、4o和o1带来一些改进之处所在。在写作时,ChatGPT的token限制增加到65,000多个token,这使得在较长对话中保留更多上下文,可以产生更流畅、更一致的回答。然而,即使有了这些改进,该模型仍然只能在单个会话中记住。它不能在不同对话之间保持记忆,因此,如果您开始新会话,ChatGPT将不会记住您的偏好或以前的问题。
日常生活融入
AI语言模型如ChatGPT被设定为将更深度地融入到我们的日常生活中。从通过个性化辅导增进教育到通过即时、准确的回应彻底改革客户服务,可能性是广泛的。在专业领域中,我们可能会看到受过特定领域数据训练的专门模型。例如,ChatGPT的医疗版本可以通过提供有关治疗和药物的最新信息来协助医生。
随着这些模型变得更加强大,道德考虑和负责任的人工智能的重要性也在增长。开发人员正在努力使人工智能更加透明,减少偏见,并确保这些工具被积极使用。训练和运行这些大型语言模型所需的能量成本是另一个热门话题,因为它们消耗大量的电力和功率来在大规模数据集上训练这些模型。我计划写一篇关于这个话题的未来文章,敬请关注!
结束
所以在这里你可以看到——借助可靠的乐高类比,窥探ChatGPT如何运作的数字幕后。从将您的输入拆分成单独的砖块(标记)到构建连贯且上下文适当的回应,ChatGPT汇集单词的方式很像搭建乐高杰作。
虽然它不是一个有思想的生物或全知实体,无法解决你最棘手的微积分问题,但它是一个强大的工具,旨在帮助你解决计算困难的任务。它处理语言和生成类人文本的能力是复杂神经网络、变压器以及大量精细调节的结果 — 来自大规模数据集和人类反馈。
但请记住,就像任何工具一样,它有其局限性。它并不能真正“理解”内容,有时会产生“幻觉”,并且存在内存限制。在我们不断前进的过程中,类似新的OpenAI o1模型采用“推理和思考”等进步正在解决这些问题,使我们更接近更无缝和可靠的互动。
查看OpenAI 01模型应用于编码场景的视频:使用OpenAI o1进行编码(youtube.com)
人工智能语言模型的未来光明,有潜力彻底改变我们日常生活的各个方面。从个性化教育和专业辅助到伦理考虑和环境影响,未来充满了挑战,也是一个令人兴奋的时代,可以见证这些新发现的诞生和发展。
随着这些技术不断发展,我们需要保持信息灵通和批判性。了解它们的运作方式能帮助我们更有效和负责任地使用它们。所以下次当你向ChatGPT提问或寻求它的帮助时,希望你能了解那些看似轻松回答背后复杂过程的一些知识。
感谢阅读我的首篇Medium文章!作为一名最近毕业的数据科学专业学生,专业方向是统计学和经济学,我对这三个领域背后的高级概念有扎实的理解。我的目标是为人工智能、机器学习和数据科学领域的最新趋势和发展提供清晰的解释和洞察!我很乐意听取您对我从自己的角度来解析的任何主题或问题的建议,所以请随意在评论中留下任何建议。