LLMs无法记住对话,那么ChatGPT如何工作呢?
ChatGPT背后的主要是LLM,一种专门针对单一任务训练过的语言模型:从一段文本中预测下一个词(实际上,预测的是令牌,文本的一小部分)。它不会记得之前的交互。
LLMs 就是关于执行文本完成。
一件你在使用ChatGPT时可能没有意识到的事情是,LLMs没有记忆。每次你使用LLM时,它只会完成你刚刚给它的文本(提示),不多不少。
准备一个基本的聊天界面
我们将在P6 KMS/平台上配置一个具有基本提示的聊天室。
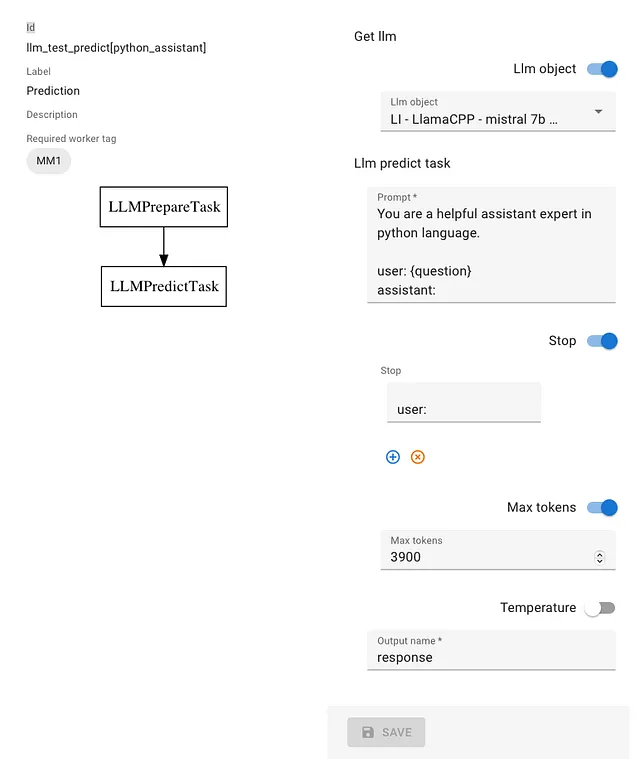
在屏幕截图中,您可以看到我使用的LLM将是在我的计算机上运行的Mistral 7B模型。提示涉及成为Python专家。
您可以看到,已经添加了一个停用词“user:”,以防止模型预测下一个问题。(是的,这是一个真正的问题).
只有两个任务,一个是准备LLM实例的任务,另一个是执行预测/文本完成的任务。
使用聊天室
我们将首先要求创建一个“car”类,然后要求它继承自另一个类。

正如你在截图中所看到的那样,LLM在构建第二个回应时没有考虑第一次互动。
把历史插入到提示里
进行对话的诀窍是允许LLM访问先前的消息,方法是将它们添加到提示中。
这次,我们将从对话开始,然后解释发生了什么变化。
聊天室的截图
正如您所看到的,查询是相同的,但是...

… 这次,第二个问题的答案紧随在第一个问题之后!
所使用的配置
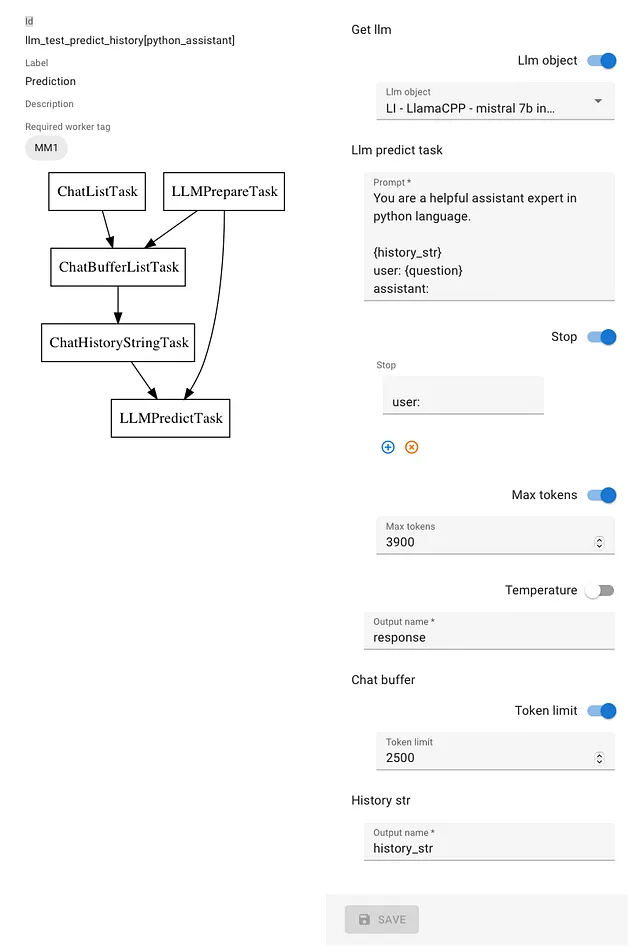
您可以看到在这种情况下有三项额外任务。
- 聊天记录任务,用于从数据库中检索传递的信息,
- ChatBufferListTask,将会从前面一步中检索到的消息中创建一个缓冲区,包括最多2,500个令牌(为了计算令牌,我们需要访问将要使用的LLM实例的分词器)。
- ChatHistoryStringTask,将缓冲区的内容转换为字符串,并使用“history_str”变量使其可访问。
由于LLM上下文窗口中可以存储的文本大小存在限制,我们可能需要删除较旧的内容,这就是聊天内存缓冲区的作用。
对于提示,我们只是添加了{history_str}占位符。
对于好奇的人,当前的ChatBufferListTask源代码(_process方法的签名可能会在不久的将来更改)。
class ChatBufferListTask(Task["ChatBufferListTask.InputModel"]):
class Parameters(BaseModel): # To declare task parameters for both the task and the UI
token_limit: Optional[int] = Field(ge=0)
class InputModel(BaseModel): # The easy (static) way to declare data needed for this task
class Config:
arbitrary_types_allowed = True
chat_history: List[ChatMessage]
llm_model: LiLlm
class OutputModel(BaseModel): # The easy (static) way to declare data provided by this task
chat_history: List[ChatMessage]
async def _process(
self, context: "Context", input_data: Mapping[str, Any]
) -> Mapping[str, Any]:
input_model = self.input_object(input_data)
parameters = cast(ChatBufferListTask.Parameters, self.merge_params(input_data))
raw_token_limit = parameters.token_limit
from llama_index.core.memory.chat_memory_buffer import ChatMemoryBuffer
token_limit = raw_token_limit if raw_token_limit else None
memory_buffer = ChatMemoryBuffer.from_defaults(
chat_history=input_model.chat_history,
llm=input_model.llm_model._llm,
token_limit=token_limit,
)
return {"chat_history": memory_buffer.get()}
关于完整任务图的声明:
with TaskDAG(
id="llm_test_predict_history", label="Prediction", required_worker_tag="MM1"
):
llm = LLMPrepareTask(id="get_llm", is_passthrough=True)
predict = LLMPredictTask(id="llm_predict_task")
llm >> predict
chat_list = ChatListTask(id="chat_list")
chat_buffer = ChatBufferListTask(id="chat_buffer")
chat_history_str = ChatHistoryStringTask(id="history_str")
chat_list >> chat_buffer >> chat_history_str >> predict
llm >> chat_buffer
这就是全部了!
请随意发表评论或与我联系,如果您想了解LLM如何使用以及为什么任务编排至关重要。
附录:在平台上使用LLM进行游戏时,主要是基于LlamaIndex的基本任务内容,但对于任务编排,使用的是平台本身,因为它允许在无需编辑源代码的情况下更改参数。
P6代表Pinceau6,我在2010年在法国卫生和医学研究所(INSERM)实习期间构思了第一个Pinceau系统。这是一个平台,可以轻松访问数据库内容,处理继承,并执行相关任务。