大型语言模型的工作原理:第一部分 — 理解词汇和预测
在之前的文章中,我们探讨了随着ChatGPT等工具的兴起而主导流行媒体的流行词,详细解释了诸如AI、ML、深度学习和LLMs等术语。现在,让我们专门深入研究大型语言模型(LLMs)的工作原理——这些模型是ChatGPT等工具的支柱。由于这些概念非常广泛,我将解释分为三篇文章,以免变成一本迷你书! 😉
本文讨论了计算机如何处理语言并预测单词。下一篇将探讨一个叫做Transformers(技术,而非机器人)的颠覆性概念,将传统方法推向了新的高度。在最后一部分,我们将深入探讨这些模型可能存在的偏见,以及在人工智能在我们生活中扮演更重要角色时,我们需要注意的事项。
第一部分:计算机是如何理解词汇的?
LLMs 本质上是理解人类语言的程序。要理解一种语言,首先需要掌握它的词汇。为了简单起见,让我们坚持使用英语。(一旦掌握了基础知识,扩展到其他语言并不难。)
现在,这就变得有趣了:计算机不像人类那样“理解”单词 - 它们只理解数字。每个词都在计算机的内存中表示为一个唯一的数字,就像一个编码的词典一样。例如,一个示例词典可能如下所示,在英语词典中总共有大约90万个独特单词,每个单词都被分配一个与之对应的数字。

假设我们想用上面的字典表示句子“你叫什么名字?”。它会看起来像一串数字(蓝色),简化为更低的数字以便解释重点。😉

第二部分:预测下一个单词!
让我们继续讨论计算机如何预测下一个单词,就像谷歌建议你下一步要输入的内容一样。他们通过概率表来做到这一点。
假设有一张大表格,表格的行中包含我们字典中的所有单词,列也是同样的单词。计算机会检查最有可能跟在你最后一个输入的单词后面的单词是什么。每个单元格显示了列中的单词在行中的单词后面出现的概率。
表格中的每个单元格都是顶部单词(列)在左侧单词(行)之后出现的机会/概率(以1或100%计算)。每行中所有数字的总和为1(或100%)。
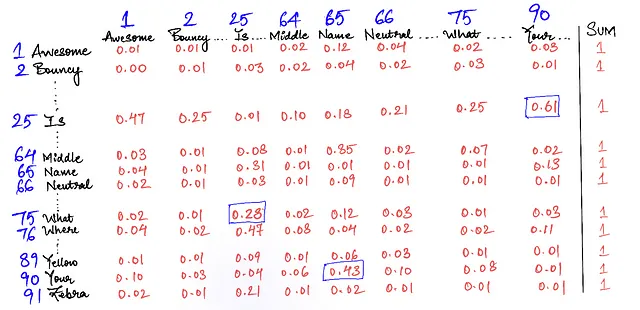
所以当我们输入“什么”时,计算机会在上面的矩阵中搜索单词“什么”所在的行,并查看顶部的单词哪一个最有可能出现在后面,然后称之为下一个单词的预测。在这种情况下,“是”有0.28的概率(或者有28%的机会)是“什么”后面最有可能出现的单词。对于熟悉机器学习的读者来说,这就是机器学习中的二元模型(NLP - 自然语言处理)。
计算机是如何生成这个表格的呢?其实并没有听起来那么复杂。计算机分析大量的文本数据(我们称之为“训练数据”),看看某些词语在其他词语后面出现的频率。这只是一种计算和计算概率的过程。所以,对于你输入的任何单词,计算机都会检查概率并选择具有最高概率的那个。
上述表格还可以简单地看作是两个词的组合,以及它们相邻出现的概率,如下面所示。

这是表格中相同的统计数据,以更易于查看的方式呈现。正如我们所看到的,出现在单词“什么”之后的所有单词的概率(机会)之和总计达到1(或100%)。
第三部分:预测完整句子
预测下一个词相对比较简单——在概率表中查找最新的词(在我们讨论的示例中是“什么”),找到对应最高可能性的词,就完成了。正如许多人可能已经猜到的那样,我们可以继续应用这种技术来获取下一个词,以及下一个词,依此类推。
然而,我们在上述方法中遗漏了一个低 hanging fruit。我们缺少前面单词的上下文,而只考虑最近的单词(在上面的情况中是什么、上或你)来进行下一个单词的预测。
正如你可以想象的那样,这是宝贵的信息,因为如果我知道在做下一个预测时“是”之前发生了什么,“你”的预测很可能会是。为了做到这一点,我们现在看一下在给定所有先前单词的情况下下一个单词的概率:

如今我们可以看到,引入前面的单词(更多的上下文)会改变下一个单词出现的概率(通常更高)。请注意,这些概率与我们上面绘制的表格不同,因为那只是对最近一个单词条件的,并没有考虑前面的单词。这是有道理的,因为当我们像人类一样思考时,我们知道如果我们有"什么是",最可能的下一个预测会是"你的"或"我的"。总和继续保持为100%,因为我们正在观察词汇表中与"什么是"之前出现的所有可能单词。
我确定你知道接下来要发生什么,如果我们有3个单词的上下文。 “你的是什么”看起来可能是以下这样的,很有可能“名字”(68%)紧随其后!这也表明,我们拥有的上下文越长,我们就能更有信心(概率)地做出下一个词汇的预测。

在做以上所有的事情时,正如您所注意到的那样 - 我故意保留了计算机将每个单词与之绑定的词汇数量(用蓝色标示)。这是为了演示对于计算机来说,75-25-90的组合能以68%的概率得出与65(名称)对应的单词!这就是大型语言模型所做的事情,它获得的数字(单词)越多,就越准确地猜测下一个数字(单词)。它们应该被称为大型数字模型,那是另一回事!🤣
💡专业见解:对于计算机来说,一切都是数字。文本(如上所述),声音(声音的频率和音高),图像(RGB组合的像素值)。这本质上意味着,给定足够的声音或像素的先前上下文,它可以预测下一组声音或像素,并创建连贯的声音或图像。正如你可以想象的那样,这在计算上更加密集,因为每个图像包含成千上万的像素 — 但嘿,这正是花哨的图像生成,甚至现在的视频生成的工作方式。这再次证实了我们的信念,它更像是一个大数字模型,而不是一个大语言模型。
第四部分:如果概率是唯一需要的,为什么这么难?
在这一点上,你可能会想知道:如果只是计算概率,为什么我们花了这么长时间来发展LLMs?
好吧,这是挑战。句子越长,计算机就需要计算更多的词组组合。这会产生大量几乎无法管理的数据。
这里是一个快速概述:
- 为了基于前一个单词预测下一个单词,我们需要一个包含900k×900k个单元的表格。
- 为了将此扩展到前两个词,它将增加到900k×900k×900k。
- 为了扩大到前10个单词,这将超越宇宙中的原子数量🤯
显然,这种方法并不具有良好的扩展性。但在2017年,一群谷歌的研究人员提出了一种解决方案叫做transformers(注意力全在你需要的地方),可以高效地处理大量的单词,而不会导致计算量激增。这是一项重大突破,我们将在下一篇文章中深入探讨。曾经想过ChatGPT如何能准确理解并回答关于这么多话题的问题吗?答案就在于transformers,相信我——这将改变AI的游戏规则。敬请关注,了解他们如何重塑了语言模型的整个风景,打开了我们几年前无法想象的可能性。您绝对不想错过这个!
总结
这篇文章介绍了大型语言模型是如何工作的基本原理,重点放在计算机如何理解词汇并预测单词上。在下一篇文章中,我们将深入研究transformers-这一关键突破使得像ChatGPT这样的现代LLM成为可能。
建议阅读
- 什么是LLM by Spotify的CTO(前15分钟)——为以上文章提供启发和指导。