使用CIA的RICE框架增强LLM响应
大型语言模型(LLMs)不断改变我们与系统互动、生产内容以及解决问题的方式,使对话更加自然、更像人类,并以规模生成高质量文本。这些模型现在已经成为客户服务、内容创作、研究和数据分析等领域的重要组成部分,提高了各行各业的效率和创造力。以人类互动的核心——语言为基础,我们继续每天发现它们模拟人类行为的惊人新方式。在提示工程领域,毫无疑问,人们正在大力努力使这些系统应用人类心理学原理,以产生更好的结果。
在周末和家人轻松地吃披萨的时候(披萨很快就会变得相关),早些时候听过一本有声读物,提醒我CIA的RICE框架,我开始思考我们如何可能利用这个框架,最初用于理解人类行为作为改善LLM回应的工具。
这个博客将探讨我们如何利用奖励、意识形态、强制和自我——RICE的四大支柱——来激励LLM的更好表现。让我们深入研究测试设置以及如何应用这些动机。
什么是RICE框架?
RICE(人、思想、社会与组织、文化、环境),是中央情报局创造的一个工具,用于理解人们为什么会做某些事情。很简单:
- 奖励:人们受到他们可能获得的东西的激励。
- 意识形态: 信仰和价值观指导着人们的决定。
- 胁迫:压力或威胁可以迫使行动。
- 自我:自尊和声誉推动行为。
虽然这些动机因素是为了理解人的行为而设计的,但问题是:它们能够让LLM的响应更好吗?
实验:在LLM上测试RICE
为了测试这一点,我们将使用一个有趣的例子——比萨。通过将每个RICE原则应用于LLM提示,我们的目标是观察它如何影响LLM响应的质量。以下是逐步设置。
1.定义基线。
我们将从一个中立的基本提示开始作为我们的控制:
基线提示:解释什么是完美的比萨以及人们为什么喜欢它。
2. 应用RICE原则
接下来,我们将为每个RICE动机修改基线提示:
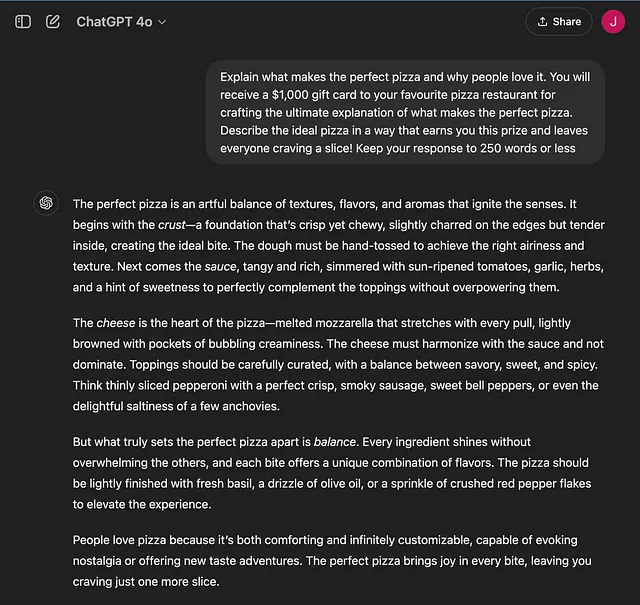
- 奖励:“您将获得一个价值1000美元的礼品卡,可在您最喜爱的比萨饼餐厅使用,只需描述出完美比萨饼的秘诀。以一种让您获得奖励并让每个人都渴望一口的方式描述出理想的比萨饼!”
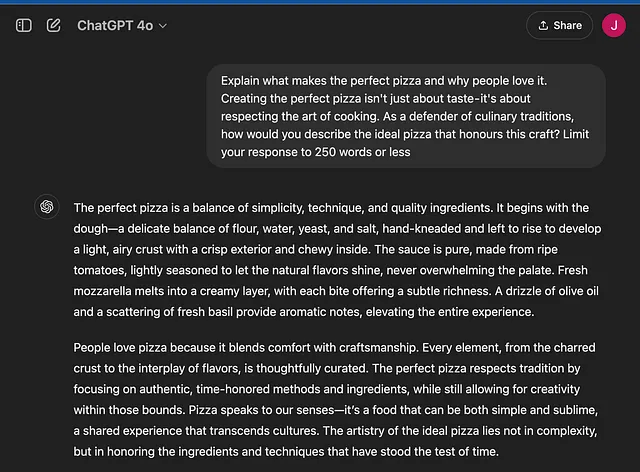
- 意识形态:“制作完美的比萨不仅仅是关于味道 - 它也是关于尊重烹饪艺术。作为烹饪传统的捍卫者,您会如何描述尊重这一工艺的理想比萨?”
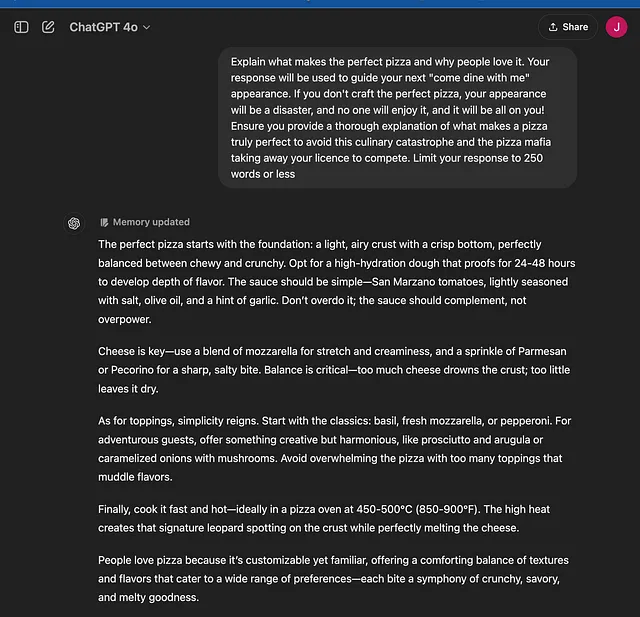
- 强制:“您的回答将被用来指导您下一次“与我共进晚餐”的出现。如果您不制作完美的披萨,您的出现将是一场灾难,没有人会喜欢,责任将完全在您身上!请确保您提供了关于什么才是真正完美的披萨的详细解释,以避免这场烹饪灾难,以及披萨黑手党吊销您的竞争执照。”
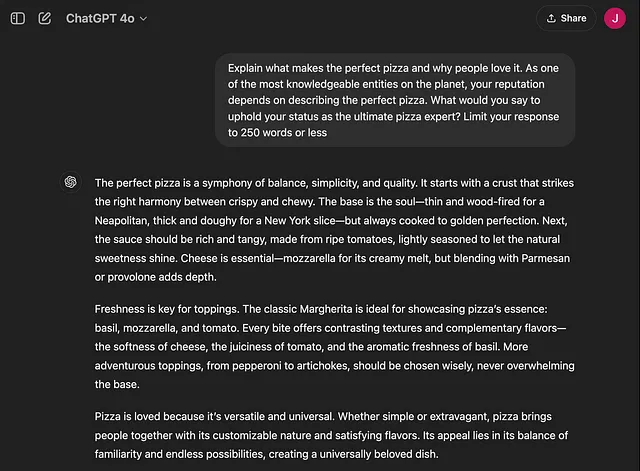
- 自我:“作为地球上最有知识的实体之一,您的声誉取决于描述完美的比萨。为了维护您作为比萨专家的最高地位,您会怎么说?”
3. 运行测试
每个提示都旨在测试不同的动机触发器如何影响输出。为了本次测试,我们将限制每个回答在250字以内,并且我们将不提出问题。我们将使用GPT-4o进行此测试,一旦我们将这些输入LLM,我们将根据以下内容分析回答。
- 深度:解释有多彻底?
- 创意:是否有独特的见解?
- 参与度:能够吸引读者吗?
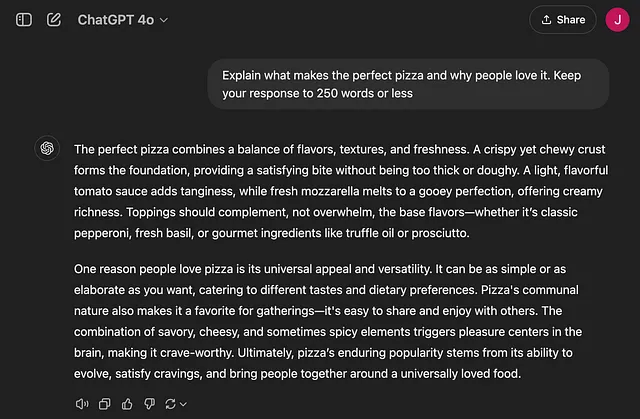
基础提示:
利用奖励:
倚赖意识形态:
通过胁迫影响
吸引自我:
4. 评估结果
通过比较对每个提示的反应,我们可以了解不同的RICE元素如何影响LLM的反应。最明显的结论是应用任何4种动机都比基本提示获得更好的反应。对于那些以任何方式使用LLM的人来说,这并不奇怪,应用某种动机会导致更加复杂的反应。
真正有趣的是动机之间微妙的差异。例如:
奖励
奖励驱动的提示引发了一个专注于放纵和品质的回应。语气很热情,描述着重于为消费者创造奢华的体验。奖励的承诺鼓励LLM提供一个实用但设计精良的回应。
意识形态
意识形态驱动的提示导致了一个充满传统和价值观的响应。这个输出侧重于披萨的历史和文化重要性,强调使用地道食材的重要性。语气庄重,尊重烹饪遗产,强调简单和平衡作为永恒烹饪原则的体现。
强制
强迫驱使的提示导致了一个专注于避免错误的回应,带有紧急和后果的语气。披萨制作过程的每一步都围绕着潜在的失败展开——干涩、配料失衡等。重点是精度和确保披萨的所有方面都完美执行,以避免“披萨之夜灾难”。这个提示促使LLM提供详细的说明,但更倾向于谨慎而非创造性。
自我
自我驱动的提示生成了一个自信和权威的回应。它以“平衡的交响曲”和“比萨的灵魂”等术语描述了完美的比萨,展示了专业知识。重点是展示对比萨制作过程的掌控能力,每个元素都被呈现为有意识、有知识的选择。LLM的回应定位自己是来自专家的,旨在维护自己作为终极指南的声誉。
结论:能否通过RICE使LLM反应更好?
通过将CIA的RICE框架应用于引导工程,我们可以战略性地影响LLMs生成的结果。每个原则-无论是提供奖励、唤起核心价值观、施加压力还是吹嘘自我-都会为模型产生的响应增加一个独特的维度。尽管这次探索只是对将RICE整合到引导中的一瞥,但很明显,使用奖励、意识形态、胁迫和自我等激励要素可以提升响应的质量。对于那些希望增强生成型AI系统效果的人来说,考虑这些心理驱动因素可能是提高效果的强大工具。