从RAG中介者:如何降低成本并提高检索速度
让我们假设我们正在创建一个企业RAG应用程序。这种假设所需的数据源需要被分成块。为简单起见-我们假设有5种文档类型及其相应的块计数-例如,
- 产品 - 10K,
- 用户指南 — 10千,
- 开发人员指南 — 10K,
- QA — 10千,
- 聊天记录 — 10千。
所以对于我们能够想到的所有不同文件类型,总共将有50K个块。因此在我们的向量存储器中,我们将有50K个块。
让我们再假设一些疑问:
- 查询1:如何创建新功能?
- 查询2:哪种产品最适合用于xyz用例?
- 查询 3:我如何使用这个功能?
如果我们查看上面所有的查询 - 在标准的RAG中,我们会搜索数据库中的所有嵌入向量,这种情况下有50K个,以找到相关的上下文。但对于查询1 - 相关的上下文将在开发人员指南中,同样对于查询2 - 相关的上下文将在产品中,对于查询3 - 相关的上下文将在用户指南中。现在,如果我们有一个直接查看只有问题中相关上下文的选项,这将节省我们很多成本,也减少延迟。
让我们来看一下这个,以及在代码中的应用。
- 导入语句
- 文件:这个来自langchain的类被用来创建带有相关内容和元数据的文档。
- 递归字符文本分割器:一种实用工具,将长文档分割成较小的块,通常基于字符,确保分块保持连贯。
- FAISS:一个使用Facebook AI相似搜索(FAISS)来索引文档并执行高效基于向量的搜索的向量存储。
- HuggingFaceEmbeddings: 这导入了来自Hugging Face模型的嵌入,用于创建文本的向量表示。
- 数据集:这是来自Hugging Face数据集库的一个模块,用于加载数据集。
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
import datasets
2. 加载数据集
knowledge_base = datasets.load_dataset("m-ric/huggingface_doc", split="train")
- 目的:从Hugging Face Hub加载名为“huggingface_doc”的数据集,其中包含文档。该数据集被分割为“train”分区。
- 解释:这里提取并存储了一系列文件,稍后会被处理和拆分。
3. 创建文档对象
source_docs = [
Document(page_content = doc["text"], metadata= {"source":doc["source"].split("/")[1]}
) for doc in knowledge_base
]
- 目的:将数据集中的每个文档转换为一个文档对象,其中存储着文档的内容和元数据。
- 说明:每个文档中的文本字段变为页面内容,而“来源”元数据通过分割URL并提取和简化(在“/”之后的第二部分)提取。
4. 将文档分割成块。
docs_processed = RecursiveCharacterTextSplitter(chunk_size=500).split_documents(source_docs)[:1000]
- 目的:使用RecursiveCharacterTextSplitter将长文档分解为每个500个字符的较小块。
- 解释:经过处理的前1000个文档块存储在docs_processed中。这一步对于在基于向量的系统中管理大型文档至关重要,因为较小的文档块可以提高检索效率。
5. 创建嵌入模型
embedding_model = HuggingFaceEmbeddings(model_name="thenlper/gte-small")
- 目的:从Hugging Face初始化嵌入模型,将文本转换为数值向量表示。
- 解释:这里正在使用Hugging Face的“thenlper/gte-small”模型为文档块创建嵌入。嵌入对于相似度搜索至关重要。
6. 使用FAISS索引文档
vectordb = FAISS.from_documents(documents=docs_processed,
embedding=embedding_model
)
- 目的:通过将处理过的文档块嵌入到FAISS向量数据库中,并对其进行索引,以实现有效的相似性搜索。
- 解释:FAISS.from_documents方法将分块索引到一个向量存储器中,其中每个分块都由其对应的向量嵌入表示。这使得可以快速且可伸缩地搜索语义上相似的文档。
7.统计和显示文档块和来源
n_chunks = len(docs_processed)
print("The total number of chunks are", n_chunks)
all_sources = list(set([doc.metadata["source"] for doc in docs_processed]))
print("All the sources are ", all_sources)
all_sources_2 = list([doc.metadata["source"] for doc in docs_processed])
from collections import Counter
counter = Counter(all_sources_2)
print("The count of chunks by their source")
print(counter)
- 目的:此代码部分计算文档块的数量并确定文档来源的不同来源。
- n_chunks: 存储已处理文档块的总数。
- 所有来源:使用文档元数据检索所有文档的唯一来源。
- 计数器:创建每个来源的块来自多少的计数。
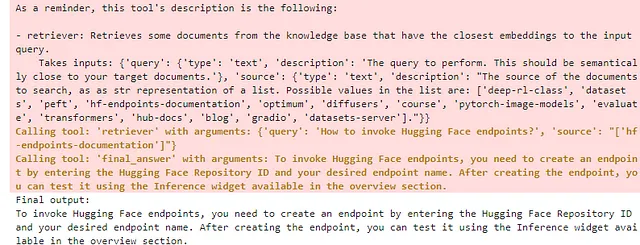
8. 检索工具定义
class RetrieverTool(Tool):
name = "retriever"
description = "Retrieves some documents from the knowledge base that have the closest embeddings to the input query."
inputs = {
"query": {
"type": "text",
"description": "The query to perform. This should be semantically close to your target documents."
},
"source": {
"type": "text",
"description": ""
},
}
output_type = "text"
- 目的:这定义了一个自定义的检索工具,它与向量存储交互以根据查询嵌入检索文档。
- 输入:定义查询和文档来源,其中查询是一个字符串,而来源(如果提供)则过滤文档。
- 输出类型:这个工具的输出是文本,表示检索到的文件。
9. 工具初始化和搜索逻辑:
def __init__(self, vectordb: VectorStore, all_sources: str, **kwargs):
super().__init__(**kwargs)
self.vectordb = vectordb
self.inputs["source"]["description"] = (
f"The source of the documents to search, as a str representation of a list. Possible values in the list are: {all_sources}."
)
- 目的:使用向量数据库和可用资源列表初始化工具。它会动态更新描述以及有效的文档来源。
- vectordb: 包含文档嵌入的向量存储。
- 所有来源:用于过滤的文档来源列表。
10. 文件搜索和过滤
def forward(self, query: str, source: str = None) -> str:
assert isinstance(query, str), "Your search query must be a string"
if source:
if isinstance(source, str) and "[" not in str(source):
source = [source]
source = json.loads(str(source).replace("'", '"'))
docs = self.vectordb.similarity_search(query, filter={"source": source} if source else None)
if len(docs) == 0:
return "No documents found with this filtering. Try removing the source filter."
return "Retrieved documents:\n" + "\n==Document==\n".join(
[doc.page_content for doc in docs]
)
- 目的: 实现了查询向量数据库的主要逻辑。它允许用户指定查询和可选的源筛选器来缩小搜索范围。
- 查询:使用提供的查询和可选源过滤器在向量库上执行相似性搜索。
- 结果: 如果找到文档,则返回其内容。否则,建议移除筛选器以获得更广泛的结果。
11. LLM与OpenAI GPT-4集成
class OpenAIEngine:
def __init__(self, model_name="gpt-4o-mini"):
self.model_name = model_name
self.client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
)
- 目的:使用API密钥初始化OpenAI GPT-4模型(或其他OpenAI模型)。该模型将根据输入和检索的文件生成回复。
- model_name: 指定要使用的模型(在本例中为“gpt-4o-mini”)。
- 客户端:使用存储在环境变量中的API密钥连接到OpenAI API。
12. 调用LLM生成响应
def __call__(self, messages, stop_sequences=[]):
messages = get_clean_message_list(
messages, role_conversions=openai_role_conversions
)
response = self.client.chat.completions.create(
model=self.model_name,
messages=messages,
stop=stop_sequences,
temperature=0.5,
)
return response.choices[0].message.content
目的:此方法调用OpenAI模型,并根据消息列表生成响应。
- 信息: 在将信息传递给模型生成回复之前对其进行清理。
- 响应:将查询发送到GPT模型并返回生成的响应。
13. 将检索工具与ReAct代理集成
llm_engine = OpenAIEngine(model_name="gpt-4o-mini")
agent = ReactJsonAgent(
tools = [RetrieverTool(vectordb, all_sources)],
llm_engine = llm_engine
)
目的: 将检索工具和GPT-4引擎结合在一个ReAct代理程序中,使代理程序能够根据查询检索文档并使用这些检索到的文档生成响应。
- ReactJsonAgent:ReAct代理配置了RetrieverTool和LLM引擎,实现了在查询文档和生成AI驱动答案之间无缝交互。
14. 运行代理
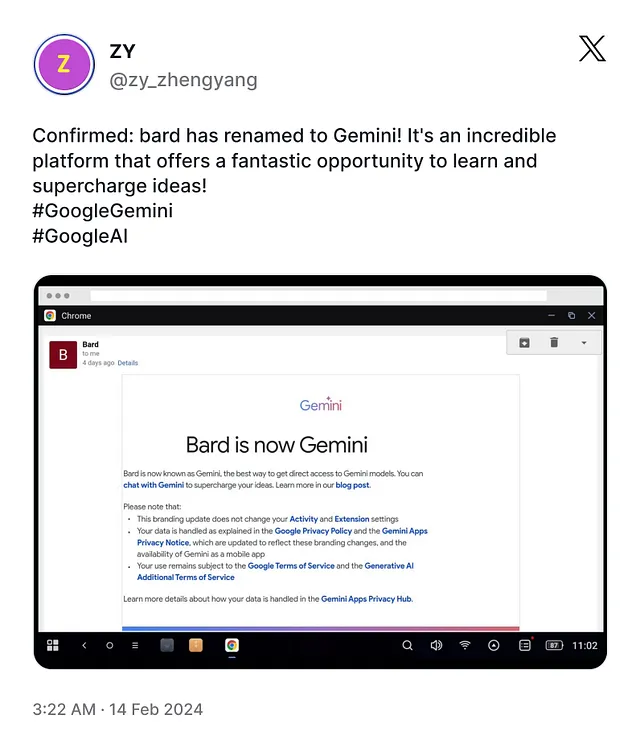
agent_output = agent.run("Please show me a LORA finetuning script")
print("Final output:")
print(agent_output)
- 目的:执行代理以检索相关文档,并生成对用户查询“请展示一个LORA微调脚本”的响应。
- 输出:最终输出,包括任何相关文档和AI生成的响应,会被打印。
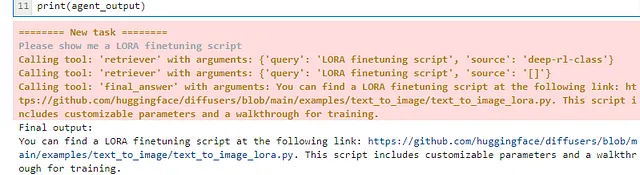
agent_output = agent.run("how to invoke hf endpoints")
print("Final output:")
print(agent_output)
摘要
- 文档块:文档被处理成块,并且识别出它们的来源。
- RetrieverTool:一种根据文档嵌入和可选源过滤器查询向量存储的自定义工具。
- OpenAI集成:该工具与OpenAI的GPT模型集成,根据用户查询和检索到的文档生成具有上下文意识的响应。
- 执行代理:ReAct代理利用检索工具和语言模型获取相关文档,并为复杂查询提供智能响应。
- 最终结果是:我们建立了一个代理检索器,通过动态选择相关数据源,以降低成本并提高RAG系统中的检索速度。—使用Hugging Face工具和嵌入来创建检索器,代理动态过滤数据源。—代理识别正确的数据源,将搜索范围从数千个减少到几个相关的块。—如果没有结果出现,则默认搜索所有数据源以确保检索。
参考资料:
- https://huggingface.co/docs/datasets/v1.2.1/loading_datasets.html 将英文转化为简体中文: https://huggingface.co/docs/datasets/v1.2.1/loading_datasets.html
- Youtube视频- AI实践
- 请访问https://huggingface.co/learn/cookbook/advanced_rag。